服务器的JAVA进程使用的内存是否正常
服务器中,JAVA进程的内存占用= JVM内存+ JAVA堆最大内存大小(Xmx)+JAVA堆外内存大小+栈区( 线程数* Xss)
最需要关注:
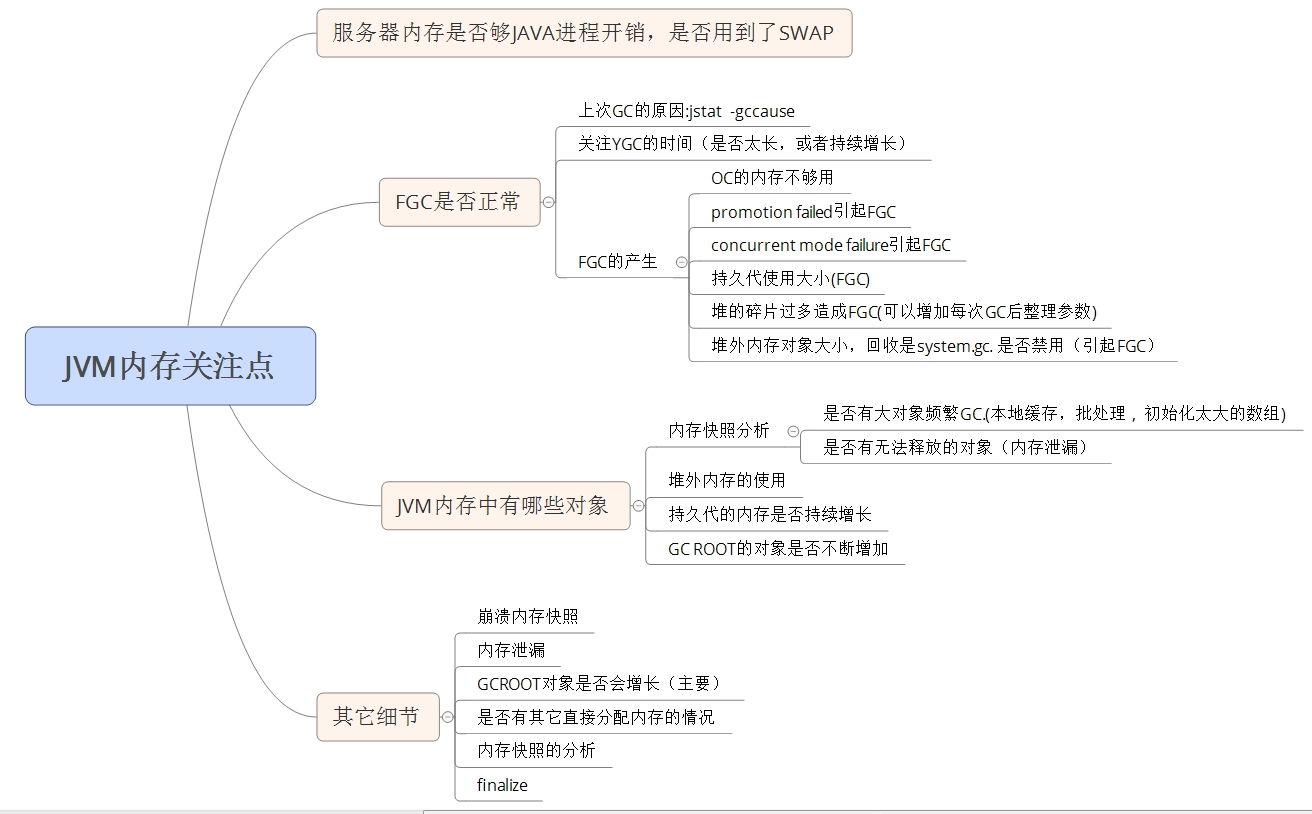
1., 服务器内存是否够JAVA进程开销
坑点: 每次JAVA的启动,只是检查当前linux的RES内存, 并不会检查申请的内存大小。
如, 服务器内存16G ,JAVA进程A的最大堆内存10G, JAVA服务B最大堆内存也是10G, 两个服务都能正常运行,但一段时间后会被服务器kill掉
详情见我另一篇 https://my.oschina.net/u/867417/blog/817866
2, 是否用到了服务器的SWAP
坑点:如果JAVA进程的垃圾回收用到了SWAP,将导致GC时间异常久,服务器上建议关掉SWAP(保证内存够用情况下)
详情见我另一篇 https://my.oschina.net/u/867417/blog/820626
GC是否正常
在启动JAVA时,注意配置:
JAVA的垃圾回收日志及地址
-XX:+PrintGCDetails -Xloggc:/data/log/gclog/web_gc_log.txt
JAVA崩溃快照以及地址配置
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/log/dump/
关注GC频率是否正常
GC 的回收频率和内存大小挂钩,一般正常情况下很少FGC。可以结合参数配置 GC垃圾回收日志分析
用 jstat -gc pid 观察FGC的次数
是否产生了FGC
上次FGC产生的原因
jstat -gccause
FGC产生的原因:
堆外内存对象大小,回收是system.gc. 是否禁用(引起FGC)
堆的碎片过多造成FGC(可以增加每次GC后整理参数)
OC的内存不够用
promotion failed引起FGC ( 对象晋升失败)
concurrent mode failure引起FGC(对象晋升时,正在CMS)
持久代大小不够( jmap -permstat )
堆的碎片过多造成FGC (碎片整理, -XX:CMSFullGCsBeforeCompaction=1 设置多少次full gc后进行内存压缩)
堆外内存对象大小,回收是system.gc. 是否禁用(-XX:-+DisableExplicitGC)
JVM内存关注点
监控JAVA进程 年轻代(edu):年老代:(ou) 持久代(G1元): 堆外内存大小
总览
jstat -gc / -gcutil pid
jmap -heap
(这样没有堆外内存大小,对外内存如果超过阀值也会调用system.gc进行造成FGC,所以也需要关注. 这个就需要JMX)
时刻掌握自己系统中的具体内存使用情况,是哪些对象在消耗内存,不要等泄漏再来看
jmap -histo pid , 查看存活对象
查看perm: jmap -permstat
dump内存分析
jmap -dump:format=b,file=dump dump整个内存
时刻关注内存的异常
内存泄漏排查:
当发生了内存泄漏时进行内存快照分析排查
详情案例见我另一篇 https://my.oschina.net/u/867417/blog/828199
堆外内存的回收是调用system.gc. 是否禁用(引起FGC)
-XX:-+DisableExplicitGC
这里也有个问题,如果用到了堆外内存(特别注意开源项目如netty),是否禁用了System.gc, 如果禁用。非堆内存会内存泄漏
我遇到过的坑分享
1,inter()的使用造成 (如fastjson) 引起的YGC时间越来越久
2, RPC调用用BIO做, 接收对象太大,结果并发上来,造成的GC
3, 半夜预约任务,然后产生了大对象引起的GC,造成了调用服务的TIMEOUT
先到这,还有堆外内存(主要netty)和finalize的两块研究先预留欠账,后续加上
最后:
养成时常关注系统的GC频率,和dump出快照分析是哪些对象在使用了我们的内存,而不是等内存溢出才去分析。
作为个程序员需要对自己系统的每块内存做到了如指掌
欢迎关注我的公众号,重现线上各种BUG, 一起来构建我们的知识体系
