| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/computer-science-class4-2018 |
|---|---|
| 这个作业要求在哪里 | <https://edu.cnblogs.com/campus/zswxy/computer-science-class4-2018/homework/11880 |
| 这个作业的目标 | <> |
| 作业正文 | .... |
| 其他参考文献 | ... |
1、项目github链接
https://github.com/szhswez/123/blob/main/作业
数据存储:
使用最简单的存储方式:创建一个大小为10000的字符数组存储从文件中读取的每一个字符,数组存储优点在于可以进行快速存储,缺点则是存储空间有限,如果文件过大可能会导致溢出
char buffer[MAXWORDS] = {}; //MAXWORDS为宏定义,大小为100000
读取方式:
使用文件流按字符读取数据并存入数组中(因不区分大小写,此处读取的时候把所有小写字母转变为了大写字母,便于后面的判断)
ifstream inFile;
inFile.open(argv[1]);
char x;
while ((x=inFile.get())!=EOF)
{
if (x <= 'z' && x >= 'a')
{
x = x - 32;
}
buffer[i] = x;
i++;
}
函数实现:
统计字符,此处直接使用了C++库中带有的字符统计函数strlen()来获得字符长度:
int GetCharacters(char *str)
{
return strlen(str);
}
统计单词数量,此处通过空格和回车来判定一个字符串是否满足成为单词的一个条件,然后再通过判断截取到的字符串长度是否大于等于4,如果满足,则最后再判断改字符串前四个字母是否为英文字母,如果全部满足,则将该字符串存入一个字符串数组中(通过字符二维数组来实现),若不满足则抛弃:
int GetWords(char* str)
{
char temp[MAXWORD][MAXWORD];
int j = 0;
int num = 0;
for (int i = 0; i < strlen(str); i++)
{
if (str[i] != ' '&&str[i]!='
')
{
temp[num][j] = str[i];
j++;
}
if (j == strlen(str)) //如果没有空格,判断该字符串是否为唯一单词
{
}
else if (str[i] == ' '||i == strlen(str)-1||str[i]=='
')
{
num++; //判断是否满足单词的条件结果满足单词数就加
}
if (num >= 11) //当单词数大于10则停止循环
{
break;
}
}
return num;
}
统计行数,判断是否有回车,且判断如果一个回车字符后面还是回车字符,则为空字符,直接跳过:
int GetLines(char* str)
{
int n = strlen(str);
int num = 0;
if (str[n - 1] == '
')
{
num--;
}
for (int i = 0; i < n; i++)
{
if (str[i] == '
')
{
if (str[i + 1] != '
')
{
num++;
}
}
}
return num+1;
}
将字符串数组中的每一个值通过冒泡排序方法排序并统计出现次数,出现过的字符串在接下来遇到的时候变为“0”(代替删除),然后创建一个数组来保存出现次数,这两个数组通过下表相等来相互对映,结果直接通过Show()函数来输出:
/*将二维数组存的单词放入字符串数组中*/
for (int i = 0; i < num; i++)
{
for (int j = 0; j < MAXWORD; j++)
{
if (temp[i][j] != 0)
{
strx[i]+=temp[i][j];
}
}
}
/*通过冒泡排序交换位置并记录次数*/
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (a[i] > a[j])
{
swap(a[i], a[j]);
swap(str[i], str[j]);
}
}
}
单元测试
测试统计字符函数:
``` c++
TEST_METHOD(TestMethod1)
{
ifstream inFile;
inFile.open("F:\test.txt");
char buffer[MAXWORDS] = {};
long i = 0;
char x;
while ((x = inFile.get()) != EOF)
{
buffer[i] = x;
i++;
}
Assert::AreEqual(GetCharacters(buffer), 44);
}
测试统计单词量函数:
TEST_METHOD(TestMethod2)
{
ifstream inFile;
inFile.open("F:\test.txt");
char buffer[MAXWORDS] = {};
long i = 0;
char x;
while ((x = inFile.get()) != EOF)
{
buffer[i] = x;
i++;
}
Assert::AreEqual(GetWords(buffer), 5);
}
测试统计行数函数:
TEST_METHOD(TestMethod3)
{
ifstream inFile;
inFile.open("F:\test.txt");
char buffer[MAXWORDS] = {};
long i = 0;
char x;
while ((x = inFile.get()) != EOF)
{
buffer[i] = x;
i++;
}
Assert::AreEqual(GetLines(buffer), 6);
}
测试结果展示:
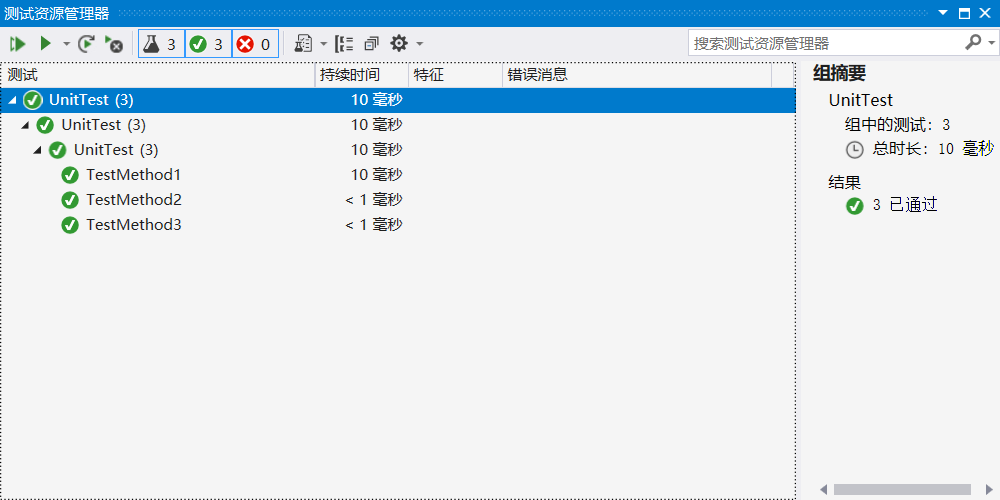
代码覆盖率检测:
成品展示:
1、input.txt:
2、运行后输出: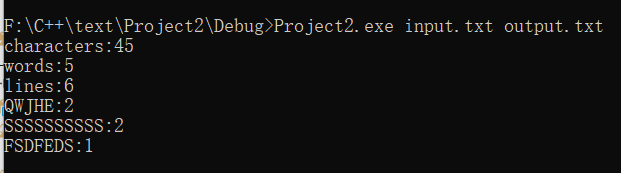
3、结果保存在output.txt中:
异常处理展示:
因为对输入输出流进行了处理,创建流的时候使用了ios::app,所以如果不存在该文件的话,不会报错,而是在该目录下面为用户创建一个文件:
心路历程与收获
这是我第一次使用GitHub,我从中学会了很多关于GitHub的操作,我感到非常兴奋;
这次话了很多时间在了解及学习git上,通过git,我可以更加方便的管理我的文档,非常的使用;
第一次使用单元测试,虽然很早以前知道单元测试是可以不通过运行代码来判断函数真确性的知识,但是一直没有实践过,通过这次作业,深入体会了单元测试的便利性,在未来的编程中,我一定会更加频繁的使用它
本次作业我有许多的不足,这次作业如果使用C++的类来编写,用上向量或者图的话会非常的高效且方便,可是这一次我对作业认知不足,曾经边编边想的坏习惯也导致了我在编程中绕弯路,以后一定先认真思考每一个项目的编程方向再下手,确保不会再犯第二次错误。