在上一篇文章中,我们大概讲了一下urllib库中最重要的两个请求方法:urlopen() 和 Request()
但是仅仅凭借那两个方法无法执行一些更高级的请求,如Cookies处理,代理设置等等。
这是就是Handler大显神威的时候了,简单地说,他是各种处理器,有处理验证登录的,有处理Cookies的,有处理代理设置的。
高级用法
首先说一下urllib。request模块中的BaseHandler类,他是所有类的基类,它提供了最基本的方法,如:default_open() protocol_request()等。
下边是各种子类:
HTTPDefaultErrorHandler 用于处理HTTP响应错误
HTTPRedirectHandler 用于处理重定向
HTTPCookieProcessor 用于处理Cookies
ProxyHandler 用于设置代理,默认代理为空
HTTPPasswordMgr 用于管理密码
HTTPBasicAuthHandler 用于认证管理
还有一个类非常重要,他就是 OpenerDirector 我们称为Opener
为什么说这个类呢?之前使用的Request和urlopen()都是封装好的请求方法,利用它们可以完成请求,但是现在我们要实现高级功能,就需要进行深一层的配置,所以就用到了Opener
下面我们看看例子:
代理设置:
在使用爬虫难免需要使用到代理,添加代理:
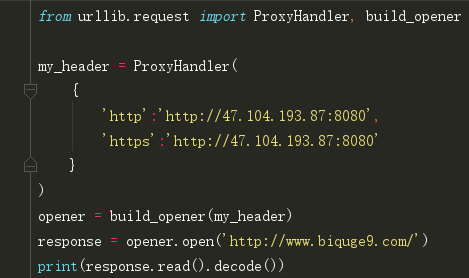
说一下代码:
这个代理是我从西刺代理上找到的,使用了 ProxyHandler类,他的参数是一个字典,key是协议名,value是代理链接。
然后再利用Handler及build_opener()方法构造一个opener,然后使用open()方法发送请求即可。
Cookies
首先我们获取网站的Cookies:
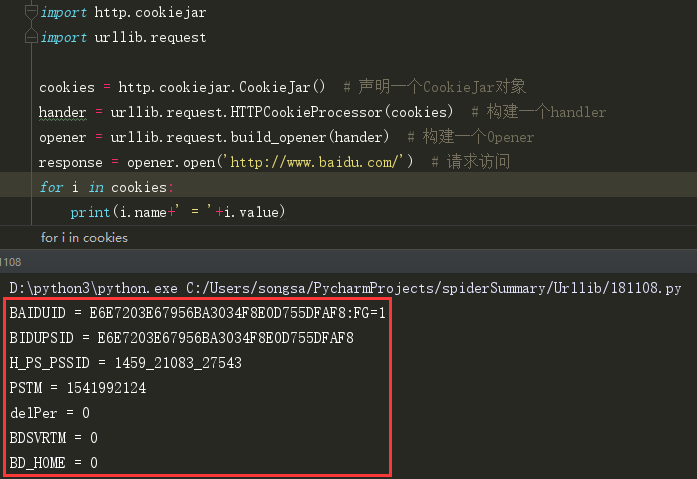
这样输出类每一条Cookie的名称和值
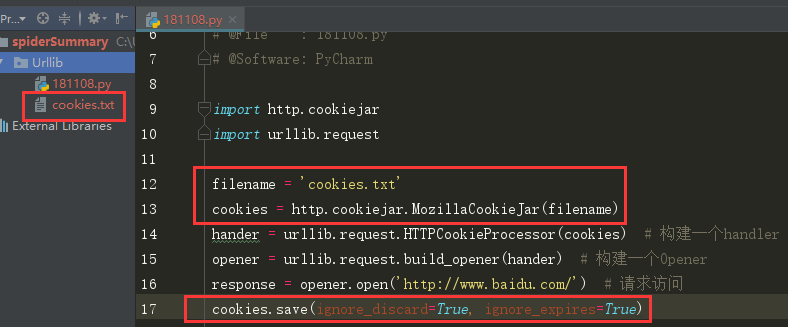
当然,也可以保存Cookie至文件:(因为Cookie实际上也是以文件形式保存的)
但是代码要稍做调整,将CookieJar改为 MozillaCookieJar(filename) 它在生成文件时会用到,是CookieJar的子类
这是cookie内容:
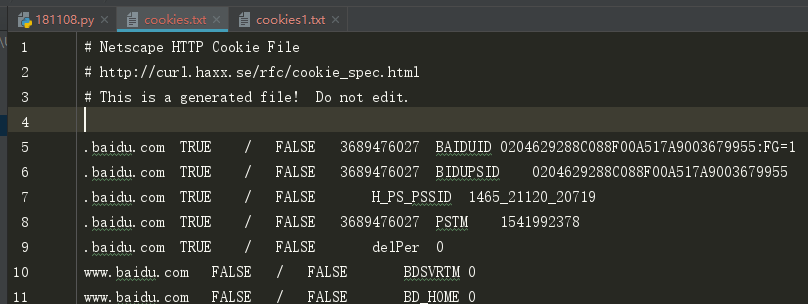
但是也可以使用 http.cookiejar.LWPCookieJar(filename) 来保存数据,但是格式会和MozillaCookieJar(filename)不大一样:
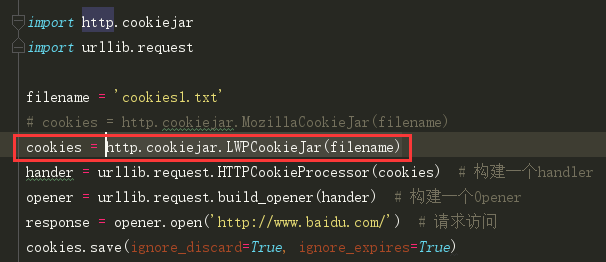

当然,你也可以再网页界面点击F12,手动获取Cookies
刚刚获取了Cookies,现在我们来在请求时获取本地文件Cookies
如从本地LWPCookieJar()类型的文本中获取Cookies:

异常处理
前面我们讲了发起请求,但是当程序报错是怎么办?脚本就会宕掉,这不是我们想要的,所以就有了异常处理
(1)URLError 因页面不存在而报错的异常:
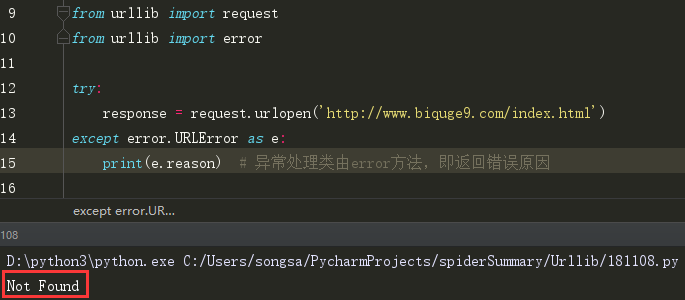
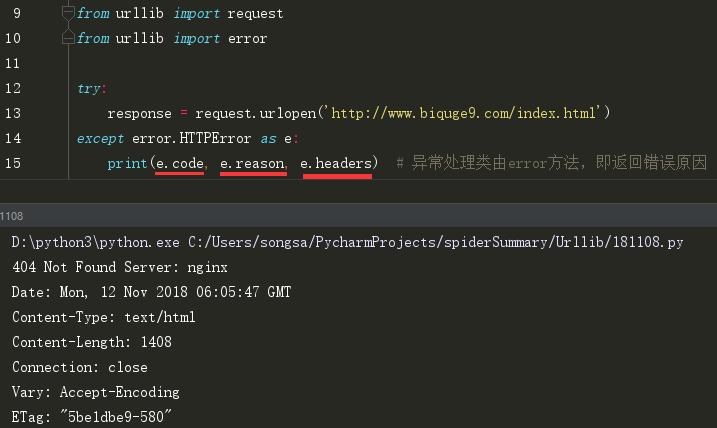
(2)HTTPError 是URLError的子类,专门处理HTTP请求错误,如认证失败等。
有三个属性:
code: 返回HTTP状态码,如200请求成功, 404网页不存在, 500服务器内部错误等。
reason: 同父类一样,用于返回错误原因
headers: 返回请求头
· 
解析链接
urllib库中还有parse模块,用于对url各部分的抽取、合并及连接转换。
(1)urlparse()
这个方法可以识别和分段URL

可以看见,返回的是一个ParseResult类型对象包含六部分。
由此可见,一个完整的URL由6部分组成: :// 之前是scheme, 代表协议; 第一个/符号前是netloc, 代表域名; 后边是path, 即访问路径; 分号;后边是parms, 代表参数; 问号?后边是query, 代表查询条件; 井号#后边是锚点,用于直接定位页面内部的下拉位置。
所以一个标准的链接格式: scheme://netloc/path;params?query#fragment
利用urlparse()方法可将其拆开
urlparse方法API:
urllib.parse.urlparse(urlstring, scheme="", allow_fragments=True)
urlstring: 必填项,是需要操作的url
scheme; 默认协议,如果url中没有协议,就使用默认协议。
allow_fragments:是否忽略 fragments 如果被设置为False,fragments就会被忽略,它会被解析为前边的一部分。
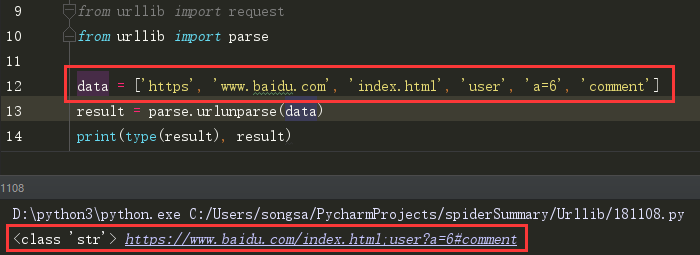
(2)urlunparse()
用于组成url,接收一个可迭代对象,但它的长度必须为6
(3)urlsplit()
这个方法和urlsplit()相似,只是不单独解析params部分,只返回5个结果。

(4)urlunsplit()
这个和urlunparse相似,可以接收列表、元祖等长度为5的参数,组成url
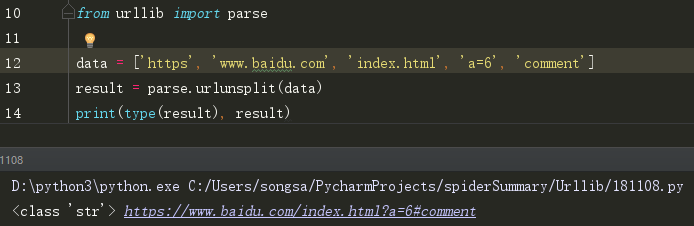
(5)urljoin()
用于拼接链接 首先有一个base_url参数作为基础链接, 将新链接作为第二个参数传入,这个方法会分析base_url的scheme, netloc, path这三个内容对新链接进行补充(注意是将对第二个链接没有的参数进行补充,有的话并不会进行替换),最终返回结果

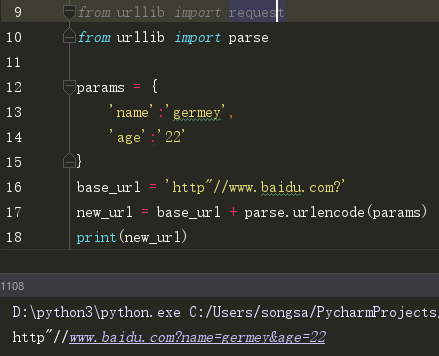
(6)urlencode()
这个方法在构造GET请求时非常有用
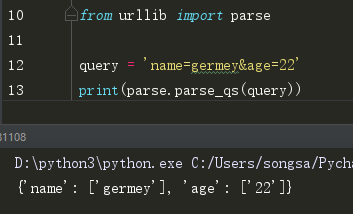
(7)parse_qs()
有序列化,就会有反序列化,这个方法可以将get参数反序列化为字典:
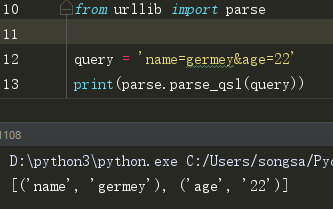
*(8)parse_qsl()方法,用于将参数转化为元组形式的列表, 返回结果每个元组中,第一个参数为参数名,第二个参数为参数值。
(9)quote()
该方法可以将内容转化为URL编码的格式。 但当url中有中文时有可能会乱码。


(10)u你quote() 可以将URL进行解码
至此,urllib库基本就已经说完了,如有疑问或建议请评论留言进行补充。不甚感激