YARN产生背景
YARN是Hadoop2.x才有的,所以在介绍YARN之前,我们先看一下MapReduce1.x时所存在的问题:-
单点故障
-
节点压力大
- 不易扩展
MapReduce1.x时的架构如下:
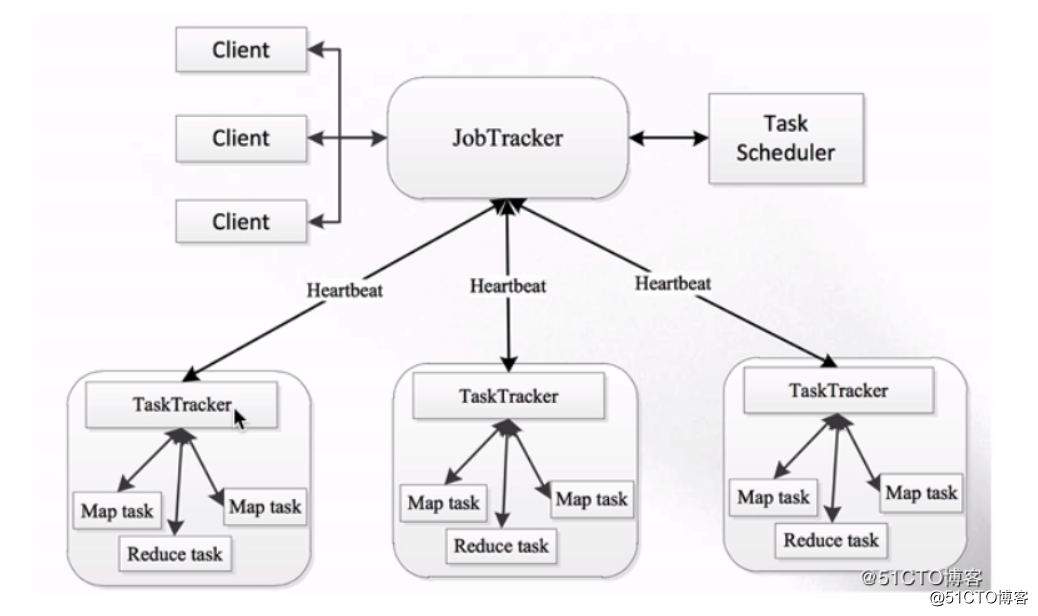
可以看到,1.x时也是Master/Slave这种主从结构,在集群上的表现就是一个JobTracker带多个TaskTracker。
JobTracker:负责资源管理和作业调度
TaskTracker:定期向JobTracker汇报本节点的健康状况、资源使用情况以及作业执行情况。还可以接收来自JobTracker的命令,例如启动任务或结束任务等。
那么这种架构存在哪些问题呢:
整个集群中只有一个JobTracker,就代表着会存在单点故障的情况
JobTracker节点的压力很大,不仅要接收来自客户端的请求,还要接收大量TaskTracker节点的请求
由于JobTracker是单节点,所以容易成为集群中的瓶颈,而且也不易域扩展
JobTracker承载的职责过多,基本整个集群中的事情都是JobTracker来管理
1.x版本的整个集群只支持MapReduce作业,其他例如Spark的作业就不支持了
由于1.x版本不支持其他框架的作业,所以导致我们需要根据不同的框架去搭建多个集群。这样就会导致资源利用率比较低以及运维成本过高,因为多个集群会导致服务环境比较复杂。如下图:
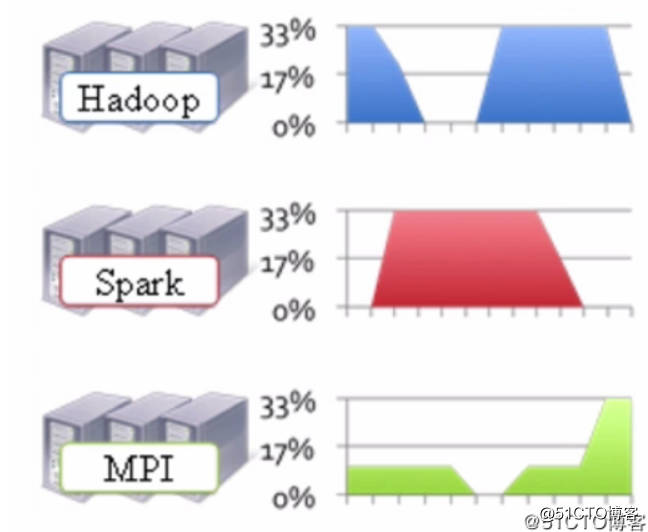
在上图中我们可以看到,不同的框架我不仅需要搭建不同的集群。而且这些集群很多时候并不是总是在工作,如上图可以看到,Hadoop集群在忙的时候Spark就比较闲,Spark集群比较忙的时候Hadoop集群就比较闲,而MPI集群则是整体并不是很忙。这样就无法高效的利用资源,因为这些不同的集群无法互相使用资源。除此之外,我们还得运维这些个不同的集群,而且文件系统是无法共享的。如果当需要将Hadoop集群上的HDFS里存储的数据传输到Spark集群上进行计算时,还会耗费相当大的网络IO流量。
所以我们就想着要把这些集群都合并在一起,让这些不同的框架能够运行在同一个集群上,这样就能解决这各种各样的问题了。如下图:
分布式资源调度——YARN框架
正是因为在1.x中,有各种各样的问题,才使得YARN得以诞生,而YARN就可以令这些不同的框架运行在同一个集群上,并为它们调度资源。我们来看看Hadoop2.x的架构图:
分布式资源调度——YARN框架
在上图中,我们可以看到,集群最底层的是HDFS,在其之上的就是YARN层,而在YARN层上则是各种不同的计算框架。所以不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度,进而提高集群资源的利用率,这也就是所谓的 xxx on YARN。
YARN架构
YARN概述:
YARN是资源调度框架
通用的资源管理系统
为上层应用提供统一的资源管理和调度
YARN架构图,也是Master/Slave结构的:
分布式资源调度——YARN框架
从上图中,我们可以看到YARN主要由以下几个核心组件构成:
-
ResourceManager, 简称RM,整个集群同一时间提供服务的RM只有一个,它负责集群资源的统一管理和调度。以及还需要处理客户端的请求,例如:提交作业或结束作业等。并且监控集群中的NM,一旦某个NM挂了,那么就需要将该NM上运行的任务告诉AM来如何进行处理。
-
NodeManager, 简称NM,整个集群中会有多个NM,它主要负责自己本身节点的资源管理和使用,以及定时向RM汇报本节点的资源使用情况。接收并处理来自RM的各种命令,例如:启动Container。NM还需要处理来自AM的命令,例如:AM会告诉NM需要启动多少个Container来跑task。
-
ApplicationMaster, 简称AM,每个应用程序都对应着一个AM。例如:MapReduce会对应一个、Spark会对应一个。它主要负责应用程序的管理,为应用程序向RM申请资源(Core、Memory),将资源分配给内部的task。AM需要与NM通信,以此来启动或停止task。task是运行在Container里面的,所以AM也是运行在Container里面。
-
Container, 封装了CPU、Memory等资源的一个容器,相当于是一个任务运行环境的抽象。
- Client, 客户端,它可以提交作业、查询作业的运行进度以及结束作业。
YARN官方文档地址如下:
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
YARN执行流程
假设客户端向ResourceManager提交一个作业,ResourceManager则会为这个作业分配一个Container。所以ResourceManager会与NodeManager进行通信,要求这个NodeManager启动一个Container。而这个Container是用来启动ApplicationMaster的,ApplicationMaster启动完之后会与ResourceManager进行一个注册。这时候客户端就可以通过ResourceManager查询作业的运行情况了。然后ApplicationMaster还会到ResourceManager上申请作业所需要的资源,申请到以后就会到对应的NodeManager之上运行客户端所提交的作业,然后NodeManager就会把task运行在启动的Container里。
如下图:
分布式资源调度——YARN框架
另外找到两篇关于YARN执行流程不错的文章:
【图文】YARN 工作流程
Yarn应用程序运行流程剖析
YARN环境搭建
介绍完基本的理论部分之后,我们来搭建一个伪分布式的单节点YARN环境,使用的hadoop版本如下:
hadoop-2.6.0-cdh5.7.0
官方的安装文档地址如下:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html1.下载并解压好hadoop-2.6.0-cdh5.7.0,这一步可以参考我之前写的一篇关于http://blog.51cto.com/13132636/2095339的文章,我这里就不再赘述了。
确保HDFS是否为正常启动状态
[root@web1 ~]# jps
3383 NameNode
3500 DataNode
3709 SecondaryNameNode
[root@web01~]# 2.编辑mapred-site.xml配置文件,在文件中增加如下内容:
[root@web01 sbin]# cd /usr/local/hadoop-2.6.0-cdh5.7.0/e
[root@web01 hadoop]#
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# cp mapred-site.xml.template mapred-site.xml # 拷贝模板文件
[root@web01] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>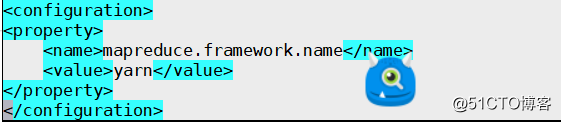
3.编辑yarn-site.xml配置文件,在文件中增加如下内容:
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim yarn-site.xml # 增加如下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>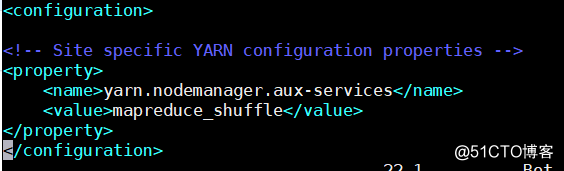
4.启动ResourceManager进程以及NodeManager进程:
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# cd ../../sbin/
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./start-yarn.shstarting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-nodemanager-localhost.out
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# jps
3984 NodeManager # 启动成功后可以看到多出了NodeManager
4947 DataNode
5252 Jps
5126 SecondaryNameNode
3884 ResourceManager # 和ResourceManager进程,这样才是正常的。
4813 NameNode
[root@web01 /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# netstat -lntp |grep javatcp 0 0 0.0.0.0:50090 0.0.0.0: LISTEN 5126/java
tcp 0 0 127.0.0.1:42602 0.0.0.0: LISTEN 4947/java
tcp 0 0 192.168.77.130:8020 0.0.0.0: LISTEN 4813/java
tcp 0 0 0.0.0.0:50070 0.0.0.0: LISTEN 4813/java
tcp 0 0 0.0.0.0:50010 0.0.0.0: LISTEN 4947/java
tcp 0 0 0.0.0.0:50075 0.0.0.0: LISTEN 4947/java
tcp 0 0 0.0.0.0:50020 0.0.0.0: LISTEN 4947/java
tcp6 0 0 :::8040 ::: LISTEN 5566/java
tcp6 0 0 :::8042 ::: LISTEN 5566/java
tcp6 0 0 :::8088 ::: LISTEN 5457/java
tcp6 0 0 :::13562 ::: LISTEN 5566/java
tcp6 0 0 :::8030 ::: LISTEN 5457/java
tcp6 0 0 :::8031 ::: LISTEN 5457/java
tcp6 0 0 :::8032 ::: LISTEN 5457/java
tcp6 0 0 :::48929 ::: LISTEN 5566/java
tcp6 0 0 :::8033 ::: LISTEN 5457/java
5..通过浏览器来访问ResourceManager,默认端口是8088,例如10.0.0.7:8088,就会访问到这样的一个页面上:
6.到此为止,我们的yarn环境就搭建完成了。