装饰器
装饰器: 本质是函数(装饰函数),就是为其他函数添加附加功能
原则:1. 不能修改被装饰器的函数的源代码与调用方式
知识储备:
1. 函数即"变量"
2. 高阶函数
a. 把一个函数名当实参传给另一个函数
b. 返回值中包含函数名
3. 嵌套函数
生成器
特点:
1. 只有调用时才会生成相应的数据
2. 只记录当前位置
3. 只有一个__next__()方法
( i*i for i in range(10) )
经典例子:生产者消费者(yield)
baozi = yield b 返回当前中断状态的值,外面收到的是b的值,baozi是外面返回回来的值
c.send(x) 发送x值传入到yield中的baozi
c.__next__()与c.send(x)区别:c.__next__()只唤醒yield中断状态,c.send(x)唤醒yield中断状态并且传入一个值
迭代器
迭代对象: 可直接作用于for循环的对象统称为可迭代对象:Iterable
可以被next()调用并不断返回下一个值的对象称为迭代器:Iterator
迭代器一定是迭代对象,迭代对象不一定是迭代器
迭代对象可以通过iter()转变为迭代器
In[2]: from collections import Iterable
In[3]: isinstance([],Iterable)
Out[3]: True
In[4]: from collections import Iterator
In[5]: isinstance([],Iterator)
Out[5]: False
In[6]: a = [1, 2, 3, 4]
In[7]: isinstance(a, Iterator)
Out[7]: False
In[8]: b = iter(a)
In[9]: isinstance(b, Iterator)
Out[9]: True
对于一个生成器它一定是一个迭代器,可以通过for loop进行访问其中的元素,但是一个迭代器却很明显的不一定是生成器
内置方法
In[2]: bin(255) ----》 数字转为二进制
Out[2]: '0b11111111'
In[4]: ascii([1,2,3]) ----》列表转字符串
Out[4]: '[1, 2, 3]'
a = bytes("abcde",encoding="utf-8")
print(a)
b = bytearray("abcde",encoding="utf-8") ---> 使字符变成字节数组,可更改
print(b[1])
b[1] = 100
print(b)
>>> b'abcde'
>>> 98
>>> bytearray(b'adcde')
>>> chr(98) ----> 数字转ascii码
"b"
>>> ord("B") ----》 ascii码转数字
66
code = "(1 + 2) * 5"
c = compile(code, "err.log",'eval') ---》 可执行的字符串代码转为可执行
print(c)
print(eval(c))
##################
<code object <module> at 0x00000260661F3ED0, file "", line 1>
15
#################
In[10]: divmod(5,2) ----》 两数相除,返回商和余数
Out[10]: (2, 1)
eval() 、exec() ----> 字符串转为可执行方法
匿名函数
calc = lambda n:print(n)
calc(5)
---> 5
calc = lambda n:3 if n<4 else n
filter() ---> 过滤
res = filter(lambda n:n>5, range(10))
for i in res:
print(i)
map() ----> 对传入的每个值进行处理
res = map(lambda n: n*n, range(10))
---》[i*2 for i in range(10)]
---》[lambda i:i*2 for i in range(10)]
for i in res:
print(i)
import functools
res = functools.reduce(lambda x,y: x+y, range(10))
print(res)
frozenset([1,2,3,4,5]) ---> 冻结集合,不可改
gloabs() ---> 打印全局变量
locals() ---> 打印局部变量
hex() ---> 16进制
oct() ----> 8进制
pow(3,5) ----> 3**5
round(1.345,2) ---> 保留2位小数
a = {6: 2,8: 0,1: 4, -5: 6}
print(sorted(a.items())) ----》 按key排序
---》 [(-5, 6), (1, 4), (6, 2), (8, 0)]
print(sorted(a.items(),key=lambda x:x[1])) ---》 按value排序
---》 [(8, 0), (6, 2), (1, 4), (-5, 6)]
json不能将函数序列化
json序列化: json.dumps(info) 写入文件
json反序列化: json.loads(f.read()) 读出文件
pickle与json用法相同,能处理共复杂的(函数等。。)
pickle 只能在python中用,json能在java中使用
pickle.dump(info,f) == f.write(pickle.dumps(info))
pickle.load(f) == pickle.loads(f.read())
os.path.abspath(__file__) 返回绝对路径
os.path.dirname() 返回目录
sys.path.append() 添加环境路径
if [True for line in context if name in line]: # 查name是否在line中
print("ok")
Python 判断列表的包含关系
有两个列表,在python里如何判定其中一个是另一个的子集?比如
>>> A = [2, 3, 4]
>>> B = [0, 1, 2, 3, 4, 5]
>>> A in B
False
>>> C = [0, [2, 3, 4], 2, 3, 4, 5]
>>> A in C
True
A作为一个列表,不是B的元素,而C里面确实有一个列表,只有这种情况下,in运算才能返回True。其实,两个列表的包含关系,可以用for逐个判定
>>> A = [2, 3, 4]
>>> B = [0, 1, 2, 3, 4, 5]
>>> any([A==B[i:i+len(A)] for i in range(0,len(B)-len(A)+1)])
True
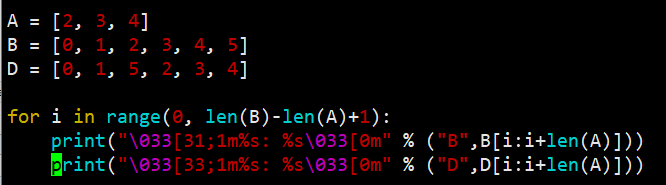

分析
首先从B的第i个元素开始,提取长度与A等长的子列表,记作C:B[i:i+len(A)]
C只需要滑过整个B即可,所以i的范围不需要到整个B的长度,只需要到len(B)-len(A)+1,滑动的过程中,逐次比较C是否与A相等,得到True或者False的结果,放入结果列表,比如上面的例子里,这个结果是
[False, False, True, False]
当i为2时,C与A相等。只要有一次匹配相等,就可以判定A是B的子集。用any函数可以实现这种逻辑:只要列表元素至少有一个为真就返回True.
>>> any([False, False, True, False])
Truejson补充说明:
json编码支持的基本类型有:None, bool, int, float, string, list, tuple, dict.
对于字典,json会假设key是字符串(字典中的任何非字符串key都会在编码时转换为字符串),要符合JSON规范,应该只对python列表和字典进行编码。此外,在WEB应用中,把最顶层对象定义为字典是一种标准做法。
json编码的格式几乎和python语法一致,略有不同的是:True会被映射为true,False会被映射为false,None会被映射为null,元组()会被映射为列表[],因为其他语言没有元组的概念,只有数组,也就是列表。