一:实验数据
对上一篇文章中的数据进行排序处理:
13480253104 180 200 380
13502468823 102 7335 7437
13560439658 5892 400 6292
13600217502 186852 200 187052
13602846565 12 1938 1950
13660577991 9 6960 6969
13719199419 0 200 200
13726230503 2481 24681 27162
13760778710 120 200 320
13823070001 180 200 380
13826544101 0 200 200
13922314466 3008 3720 6728
13925057413 63 11058 11121
13926251106 0 200 200
13926435656 1512 200 1712
15013685858 27 3659 3686
15920133257 20 3156 3176
15989002119 3 1938 1941
18211575961 12 1527 1539
18320173382 18 9531 9549
84138413 4116 1432 5548
二:MapReduce程序编写
(一)自定义数据结构FlowBean编写
package cn.hadoop.mr.wc;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean> {
private String phoneNB;
private long up_flow;
private long down_flow;
private long sum_flow;
public FlowBean() {} //无参构造函数,用于反序列化时使用
public FlowBean(String phoneNB, long up_flow, long down_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.down_flow = down_flow;
this.sum_flow = up_flow + down_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getDown_flow() {
return down_flow;
}
public void setDown_flow(long down_flow) {
this.down_flow = down_flow;
}
public long getSum_flow() {
return up_flow + down_flow;
}
//用于序列化
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(down_flow);
out.writeLong(up_flow+down_flow);
}
//用于反序列化
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
phoneNB = in.readUTF();
up_flow = in.readLong();
down_flow = in.readLong();
sum_flow = in.readLong();
}
@Override
public int compareTo(FlowBean o) { //用于排序操作
return sum_flow > o.sum_flow ? -1 : 1; //返回值为-1,则排在前面
}
@Override
public String toString() {
return "" + up_flow + " " + down_flow + " "+ sum_flow;
}
}
(二)Map程序编写
package cn.hadoop.rs;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import cn.hadoop.mr.wc.FlowBean;
public class ResSortMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, FlowBean, NullWritable>.Context context)
throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//进行文本分割
String[] fields = StringUtils.split(line, ' ');
//数据获取
String phoneNB = fields[0];
long up_flow = Long.parseLong(fields[1]);
long down_flow = Long.parseLong(fields[2]);
context.write(new FlowBean(phoneNB, up_flow, down_flow), NullWritable.get());
}
}
(三)Reduce程序编写
package cn.hadoop.rs;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import cn.hadoop.mr.wc.FlowBean;
//会在reduce接收数据时,对key进行排序
public class ResSortReducer extends Reducer<FlowBean, NullWritable, Text, FlowBean>{
@Override
protected void reduce(FlowBean key, Iterable<NullWritable> values,
Reducer<FlowBean, NullWritable, Text, FlowBean>.Context context) throws IOException, InterruptedException {
String phoneNB = key.getPhoneNB();
context.write(new Text(phoneNB), key);
}
}
注意:排序比较会在Reduce接收到key时进行排序,所以我们需要对输入的key进行处理
(四)主函数进行调用
package cn.hadoop.rs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.hadoop.mr.wc.FlowBean;
public class ResSortRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ResSortRunner.class);
job.setMapperClass(ResSortMapper.class);
job.setReducerClass(ResSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
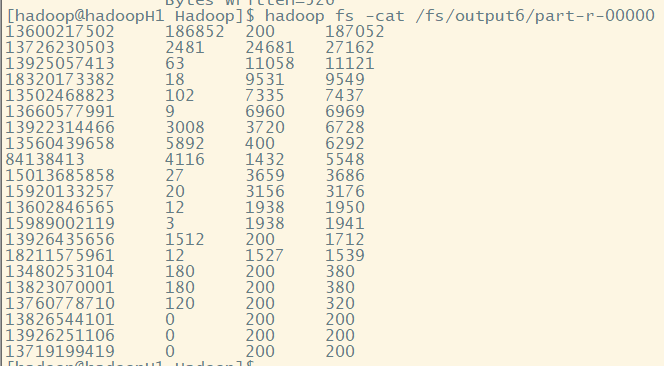
(五)结果测试
hadoop jar rs.jar cn.hadoop.rs.ResSortRunner /fs/output1 /fs/output6
三:实现将两个job在main中一次执行
(一)修改main方法,实现连续调用两个job
package cn.hadoop.rs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.hadoop.fs.FlowSumMapper;
import cn.hadoop.fs.FlowSumReducer;
import cn.hadoop.fs.FlowSumRunner;
import cn.hadoop.mr.wc.FlowBean;
public class ResSortRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf1 = new Configuration();
Job job1 = Job.getInstance(conf1);
job1.setJarByClass(FlowSumRunner.class);
job1.setMapperClass(FlowSumMapper.class);
job1.setReducerClass(FlowSumReducer.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(FlowBean.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job1, new Path(args[0]));
FileOutputFormat.setOutputPath(job1, new Path(args[1]));
if(!job1.waitForCompletion(true)) {
System.exit(1);
}
Configuration conf2 = new Configuration();
Job job2 = Job.getInstance(conf2);
job2.setJarByClass(ResSortRunner.class);
job2.setMapperClass(ResSortMapper.class);
job2.setReducerClass(ResSortReducer.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(FlowBean.class);
job2.setMapOutputKeyClass(FlowBean.class);
job2.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job2, new Path(args[1]));
FileOutputFormat.setOutputPath(job2, new Path(args[2]));
System.exit(job2.waitForCompletion(true)?0:1);
}
}
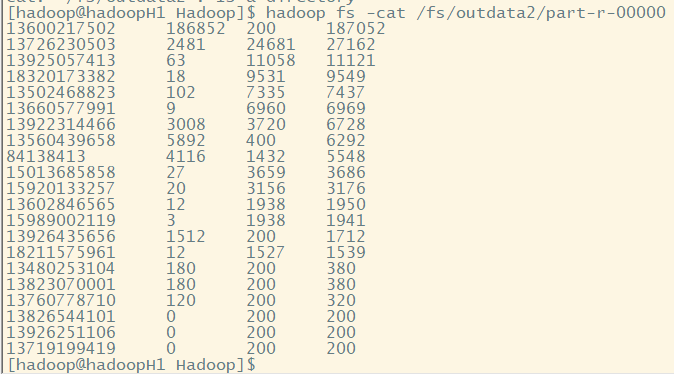
(二)实验测试,结果查看
hadoop jar rs.jar cn.hadoop.rs.ResSortRunner /fs/input /fs/outdata1 /fs/outdata2
(三)补充:使用时,不推荐这种方法。中间结果单独输出,使用shell将各个程序串联,灵活性更大,更容易调试