一:安装storm
(一)安装一个zookeeper集群
注意:需要先启动zookeeper集群才可以,不然后面容易出错
(二)上传storm的安装包,解压
(三)修改配置文件storm.yaml
#所使用的zookeeper集群主机
storm.zookeeper.servers:
- "hadoopH5"
- "hadoopH6"
- "hadoopH7"
#nimbus所在的主机名
nimbus.host: "hadoopH5"
可选配置:为worker进程配置端口号(端口数决定worker数)
supervisor.slots.ports
-6701
-6702
-6703
-6704
-6705
(四)启动storm
1.启动nimbus
nohup ./storm nimbus 1>/dev/null 2>&1 & 开启nimbus
nohup ./storm ui 1>/dev/null 2>&1 & 开启ui界面,通过web服务


2.启动supervisor
nohup ./storm supervisor 1>/dev/null 2>&1 &
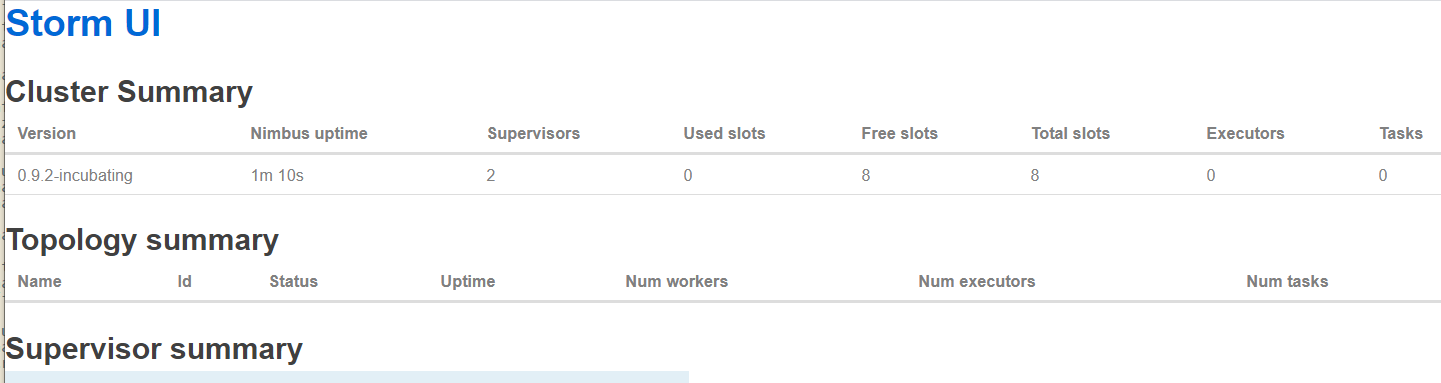
3.测试UI
二:storm程序编写
(一)程序实现功能
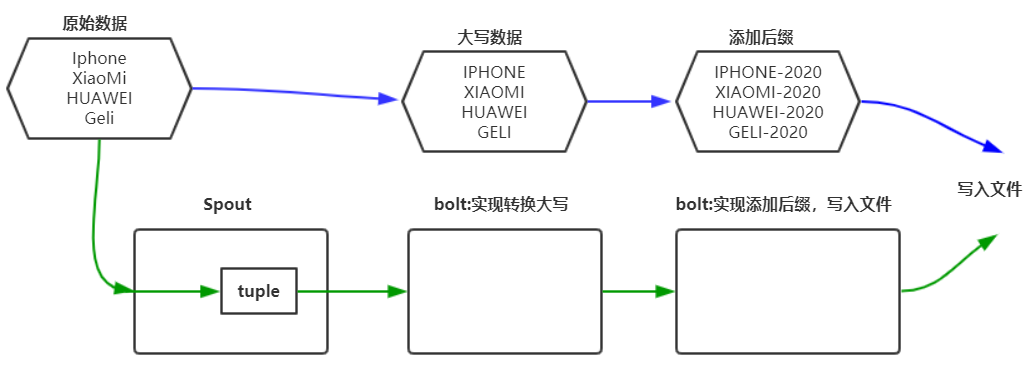
(二)代码实现
1.实现spout功能,进行源数据获取
package cn.storm.tl;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class RandomWordSpout extends BaseRichSpout{
//用于存放SpoutOutputCollector变量,在open初始化时赋值
private SpoutOutputCollector collector;
//数据模拟
String[] words = {"Iphone","XiaoMi","HUAWEI","Geli"};
//是spout组件核心逻辑
//不断向下一个组件中发送tuple消息
@Override
public void nextTuple() {
//一般从Kafka消息队列中获取数据,这里我们直接从数组中随机选取数据发送
Random random = new Random();
int index = random.nextInt(words.length);
String word=words[index];
//将数据封装为tuple,通过SpoutOutputCollector控制器实例对象,发送出去
collector.emit(new Values(word)); //values可以输出元组列表
//间隔时间,休眠500ms
Utils.sleep(500);
}
//进行初始化
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//进行初始化操作,collector用于发送数据
this.collector = collector;
}
//声明输出tuple元组数据的字段含义
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("phoneName")); //如果元组数据多个,可以使用list列表声明
}
}
2.实现大写转换bolt
package cn.storm.tl;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class UpperBolt extends BaseBasicBolt{
//处理业务逻辑
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先获取到上一个组件传递过来的数据,数据存放在tuple
String phoneName = tuple.getString(0); //tuple中只存放了一个值,下标为0
//将数据转为大写
String phoneName_upper = phoneName.toUpperCase();
//将转换完成的数据再次发送出去
collector.emit(new Values(phoneName_upper));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("phoneNameUpper"));
}
}
3.实现后缀添加,以及文件写入
package cn.storm.tl;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import javax.management.RuntimeErrorException;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class SuffixBolt extends BaseBasicBolt{
FileWriter fw = null;
//在bolt组件运行过程中,只会被调用一次,可以用于进行初始化操作
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
fw = new FileWriter("/home/hadoop/stormoutput/"+UUID.randomUUID());
}catch(IOException e) {
e.printStackTrace();
}
}
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//获取数据,进行修改
String upper_name = tuple.getString(0);
//进行修改
String suffix_phone = upper_name+"-2020";
//文件写入
try {
fw.write(suffix_phone);
fw.write('
');
fw.flush();
}catch(IOException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// TODO Auto-generated method stub
}
}
4.实现整个topology,提交任务给storm集群
package cn.storm.tl;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
/*
* 组织各个组件形成一个完整的处理流程,就是所谓的topology
* 并且将该topology提交给storm进行运行(一直运行,无退出)
*/
public class TopoMain {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
TopologyBuilder builder = new TopologyBuilder();
//将spout组件添加到topology中
builder.setSpout("randomspout", new RandomWordSpout(),4); //并发度:启动executor线程数4
//将大写转换bolt组件设置到topology中,并且指定它接收spout消息
builder.setBolt("upperbolt", new UpperBolt(),4).shuffleGrouping("randomspout");
//将添加后缀的bolt组件设置到topology,并指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new SuffixBolt(),4).shuffleGrouping("upperbolt");
//用builder创建一个topology
StormTopology topology = builder.createTopology();
//配置topology在集群运行时的参数
Config conf = new Config();
conf.setNumWorkers(4); //设置拓扑worker进程数
conf.setDebug(true);
conf.setNumAckers(0); //设置事务ack机制,类似于TCP机制
//将这个topology提交给storm集群运行
StormSubmitter.submitTopology("demotopo", conf, topology);
}
}
三:结果测试
(一)storm启动jar包
storm jar demotopo.jar cn.storm.tl.TopoMain
(二)查看supervisor节点
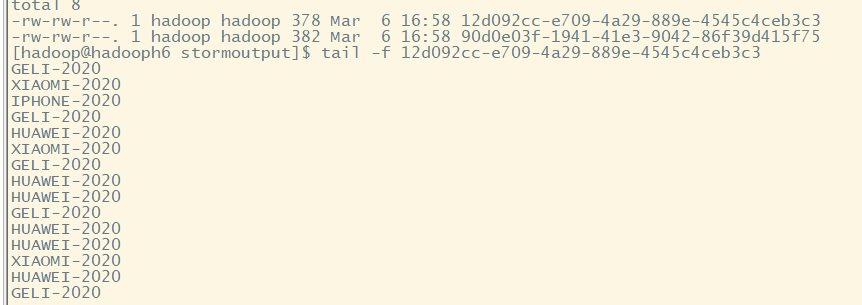
文件写入:使用tail -f查看动态文件数据
四:Storm体系结构
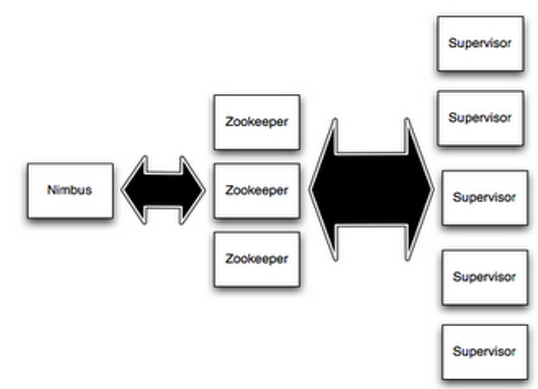
(一)Storm中的Nimbus和Supervisor
1.Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。
2.Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。
3.这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
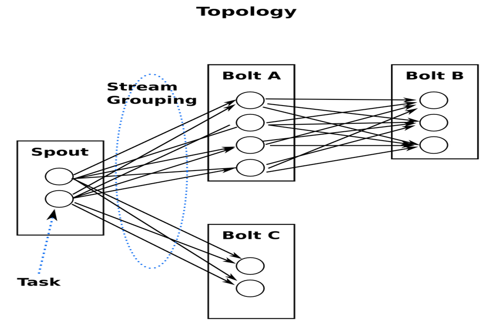
(二)Storm中的Topologies
一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:
(三)Storm中的Stream
消息流stream是storm里的关键抽象;
一个消息流是一个没有边界的tuple序列(消息流中包含无限的tuple), 而这些tuple序列会以一种分布式的方式并行地创建和处理;
通过对stream中tuple序列中每个字段命名来定义stream;
在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array;
可以自定义类型(只要实现相应的序列化器)。
(四)Storm中的Spouts
消息源spout是Storm里面一个topology里面的消息生产者;
一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple;
Spouts可以是可靠的也可以是不可靠的:如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple, 但是不可靠的消息源spouts一旦发出一个tuple就不能重发了;
消息源可以发射多条消息流stream:
使用OutputFieldsDeclarer.declareStream来定义多个stream,
然后使用SpoutOutputCollector来发射指定的stream。
(五)Storm中的Bolts
所有的消息处理逻辑被封装在bolts里面;
Bolts可以做很多事情:过滤,聚合,查询数据库等等。
Bolts可以简单的做消息流的传递,也可以通过多级Bolts的组合来完成复杂的消息流处理;比如求TopN、聚合操作等(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流:
使用OutputFieldsDeclarer.declareStream定义stream;
使用OutputCollector.emit来选择要发射的stream;
Bolts的主要方法是execute,:
它以一个tuple作为输入,使用OutputCollector来发射tuple;
通过调用OutputCollector的ack方法,以通知这个tuple的发射者spout;
Bolts一般的流程:
处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了;
storm提供了一个IBasicBolt会自动调用ack。
(六)Storm中的Stream groupings
定义一个topology的关键一步是定义每个bolt接收什么样的流作为输入;
stream grouping就是用来定义一个stream应该如何分配数据给bolts;
Storm里面有7种类型的stream grouping:
Shuffle Grouping——随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同;
Fields Grouping——按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts里的一个task, 而不同的userid则会被分配到不同的bolts里的task;
All Grouping——广播发送,对于每一个tuple,所有的bolts都会收到;
Global Grouping——全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task;
Non Grouping——不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行;
Direct Grouping——直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。
消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id);
Local or shuffle grouping——如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
(七)Storm中的Workers
一个topology可能会在一个或者多个worker(工作进程)里面执行;
每个worker是一个物理JVM并且执行整个topology的一部分;
比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks;
Storm会尽量均匀的工作分配给所有的worker;
(八)Storm中的Tasks
每一个spout和bolt会被当作很多task在整个集群里执行
每一个executor对应到一个线程,在这个线程上运行多个task
stream grouping则是定义怎么从一堆task发射tuple到另外一堆task
可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)

五:Topology运行机制
(一)运行机制
(1)Storm提交后,会把代码首先存放到Nimbus节点的inbox目录下,之后,会把当前Storm运行的配置生成一个stormconf.ser文件放到Nimbus节点的stormdist目录中,在此目录中同时还有序列化之后的Topology代码文件;
(2)在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的executor数目和task数目,默认情况下,一个Topology的task的总和是和executor的总和一致的。之后,系统根据worker的数目,尽量平均的分配这些task的执行。worker在哪个supervisor节点上运行是由storm本身决定的;
(3)任务分配好之后,Nimbes节点会将任务的信息提交到zookeeper集群,同时在zookeeper集群中会有workerbeats节点,这里存储了当前Topology的所有worker进程的心跳信息;
(4)Supervisor节点会不断的轮询zookeeper集群,在zookeeper的assignments节点中保存了所有Topology的任务分配信息、代码存储目录、任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行;
(5)一个Topology运行之后,就会不断的通过Spouts来发送Stream流,通过Bolts来不断的处理接收到的Stream流,Stream流是无界的。
(6)最后一步会不间断的执行,除非手动结束Topology。

(二)运行机制补充
有几点需要说明的地方: (1)每个组件(Spout或者Bolt)的构造方法和declareOutputFields方法都只被调用一次。 (2)open方法、prepare方法的调用是多次的。入口函数中设定的setSpout或者setBolt里的并行度参数指的是executor的数目,是负责运行组件中的task的线程 的数目,此数目是多少,上述的两个方法就会被调用多少次,在每个executor运行的时候调用一次。相当于一个线程的构造方法。 (3)nextTuple方法、execute方法是一直被运行的,nextTuple方法不断的发射Tuple,Bolt的execute不断的接收Tuple进行处理。只有这样不断地运行,才会产生无界的Tuple流,体现实时性。相当于线程的run方法。 (4)在提交了一个topology之后,Storm就会创建spout/bolt实例并进行序列化。之后,将序列化的component发送给所有的任务所在的机器(即Supervisor节 点),在每一个任务上反序列化component。 (5)Spout和Bolt之间、Bolt和Bolt之间的通信,是通过zeroMQ的消息队列实现的。 (6)上图没有列出ack方法和fail方法,在一个Tuple被成功处理之后,需要调用ack方法来标记成功,否则调用fail方法标记失败,重新处理这个Tuple。
(三)补充:终止Topology
通过在Nimbus节点利用如下命令来终止一个Topology的运行:
storm kill topologyName
kill之后,可以通过UI界面查看topology状态,会首先变成KILLED状态,在清理完本地目录和zookeeper集群中的和当前Topology相关的信息之后,此Topology就会彻底消失