一:机器学习定义
一个程序被认为能够从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了P的评判后,程序在处理T时的性能有所提升。
举例:下棋游戏中,经验e就是程序上万次的自我练习的经验,而任务t就是下棋。性能度量值p就是与新的对手比赛时赢的比赛的概率。
二:监督学习与非监督学习
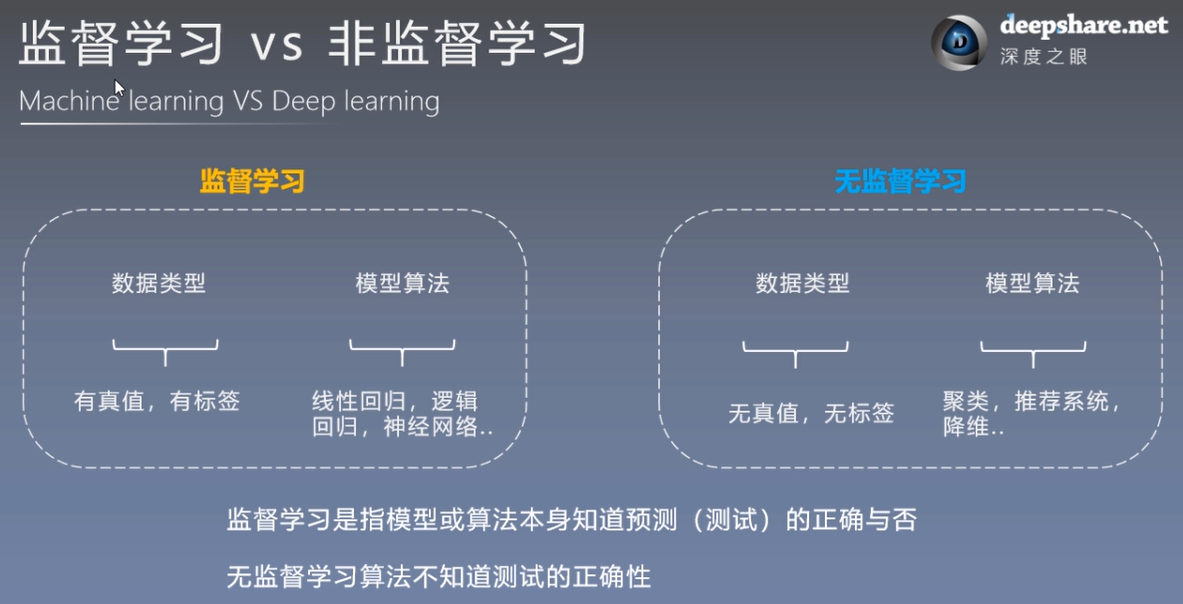
(一)监督学习---我们会教计算机做某事(每个样本都有对应的正确答案,如回归问题)
监督学习是指我们给算法一个数据集,其中包含了正确答案,在这个数据集中的每个样本,我们都给出了正确的结果,算法的目的就是给出更多的正确答案。

监督学习是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。在监督学习的过程中会提供对错指示,通过不断地重复训练,使其找到给定的训练数据集中的某种模式或规律,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入和输出,主要应用于分类和预测。
(二)无监督学习---我们让计算机自主学习(样本无对应答案,属于自主学习,如分类聚类问题)
只知道有这样一个数据集,不知道每个数据点含义。
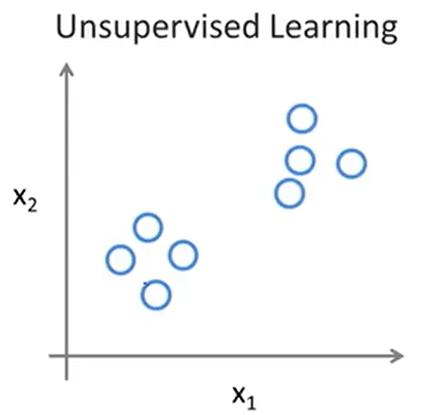
与监督学习不同,在非监督学习中,无须对数据集进行标记,即没有输出。其需要从数据集中发现隐含的某种结构,从而获得样本数据的结构特征,判断哪些数据比较相似。因此,非监督学习目标不是告诉计算机怎么做,而是让它去学习怎样做事情。

对于给定的数据集,无监督学习算法可能判定该数据集包含两个不同的簇;这就是聚类算法

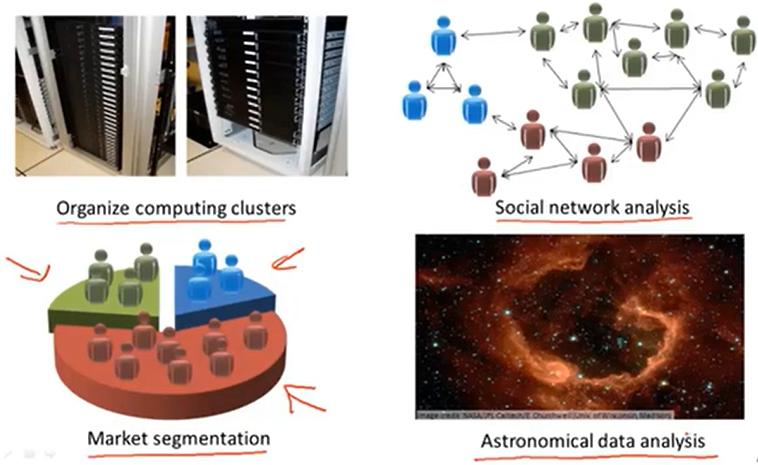
聚簇算法,例如:将有关同一主题的新闻显示在一起,或者应用在基因处理中。

其他应用: