一:案例学习
(一)西瓜书
(二)https://zhuanlan.zhihu.com/p/27126737(看这个即可了解AdaBoost算法原理)
二:代码实现
(一)数据加载
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): #获取数据 data_X = np.array([ [1,2.1], # [2,1.1], #1.5 1.6 [1.5,1.6], [1.3,1], [1,1], [2,1] ]) data_Y = np.array([1,1,-1,-1,1]) return data_X,data_Y


plt.figure() cls_data_1 = data_X[np.where(data_Y==1)] cls_data_2 = data_X[np.where(data_Y==-1)] plt.scatter(cls_data_1[:,0],cls_data_1[:,1],s=30,c="b") plt.scatter(cls_data_2[:,0],cls_data_2[:,1],s=30,c="y",marker='s') plt.show()

(二)单层决策树生成函数
#一:单层决策树生成函数 #1.根据输入的特征列、阈值、不等号,获取当前的数据的类别为-1、1 def stumpClassfiy(data_X,dimen,threshVal,threshIneq): #传入数据集,特征选取维度,阈值,大于小于 classArr = np.ones((data_X.shape[0],1)) if threshIneq == "lt": classArr[np.where(data_X[:,dimen]<=threshVal)] = -1 #因为这里是小于等于,所以我们阈值到最大值,即可划分所有的数据集。见下方2 else: classArr[np.where(data_X[:,dimen]>threshVal)] = -1 return classArr #2.基于数据的权重向量D,来找来找数据集上的最佳的单层决策树 def buildStump(data_X,data_Y,D): m,n = data_X.shape numSteps = 10 #设置步数,用来进行阈值选取 bestStump = {} #使用字典来保存多个返回值,包括阈值选取,特征列选取,不等号选取 bestClasEst = np.zeros((m,1)) #用来保存最优的类别划分 minError = np.inf #保存最小误差(判断错误点的权重和) for i in range(n): #循环所有的特征列 rangeMin = np.min(data_X[:,i]) rangeMax = np.max(data_X[:,i]) #获取当前列的最大、最小值,根据上面设置的步数,在下面获取步长 stepSize = (rangeMax - rangeMin) / numSteps for j in range(-1,numSteps+1): #循环步数,来获取阈值(从最小值-一个步长,到最大值) #获取阈值threshVal threshVal = rangeMin + j*stepSize for ineq in ['lt','gt']: #因为在不同位置,我们选取大于或者等于得到的误差和是不同的,所以我们需要进行遍历,从而找出最优值 #获取预测的类别 predictClass = stumpClassfiy(data_X,i,threshVal,ineq) #判断预测的类别和实际的类别是否相等,从而获取错误信息 errArr = np.ones((m,1)) # print(predictClass.shape,data_Y.shape) errArr[predictClass==data_Y] = 0 #相等则为0,不计算误差 #获取加权后的误差 weightError = D.T@errArr #注意转置,因为我们在adaboost训练函数传入的是列向量 if weightError < minError: minError = weightError bestClasEst = predictClass bestStump['dimen'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = ineq return bestStump,minError,bestClasEst #因为后面更新α时,需要使用到误差的权重。更新权重的时候要使用到
(三)基于单层决策树实现的AdaBoost训练过程
#二:基于单层决策树实现的AdaBoost训练过程 def adaBoostTrains(data_X,data_Y,numIt=40): #后面表示迭代次数,当然如果在迭代次数内,实现误差为0,则退出 weakClassArr = [] #用来保存返回的数据 m,n = data_X.shape D = np.array(np.ones((m,1))/m) #初始化权重向量 aggClassEst = np.zeros((m,1)) #错误率计算 for i in range(numIt): #进行迭代 bestStump, minError, bestClasEst =buildStump(data_X,data_Y,D) print("D:",D) print("classEst",bestClasEst) alpha = 1/2*np.log((1-minError)/max(minError,1e-16)) #确保没有出错时,保证没有除0溢出 print("alpha:",alpha) bestStump['alpha'] = alpha #因为后面还需要alpha,所以这里保存 weakClassArr.append(bestStump) #将本次最情况的分类保存 #重新计算权重 expon = np.multiply(-1*alpha*data_Y,bestClasEst) #看公式 D = np.multiply(D,np.exp(expon)) D = D / np.sum(D) #进行归一化 aggClassEst += alpha*bestClasEst #错误率累加计算 print("aggClassEst:",aggClassEst) arrErrors = np.multiply(np.sign(aggClassEst)!=data_Y,np.ones((m,1))) #计算错误数目 errorRate = arrErrors.sum() / m #计算错误率 print("error rate:",errorRate) if errorRate == 0: break return weakClassArr
(四)实现预测函数
#三:实现预测功能 def adaClassify(data_sim,classfierArr): #传入测试数据和分类器 #将所有的分类器的权重和即可得到最后结果 m,n = data_sim.shape aggClassEst = np.zeros((m,1)) for i in range(len(classfierArr)): classEst = stumpClassfiy(data_sim,classfierArr[i]['dimen'],classfierArr[i]['thresh'],classfierArr[i]['ineq']) aggClassEst += classEst*classfierArr[i]['alpha'] #累加权重 print(aggClassEst) return np.sign(aggClassEst)
(五)结果测试
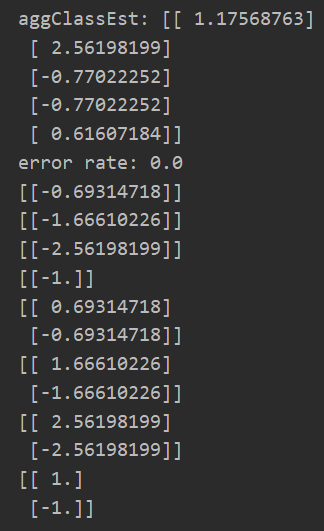
data_X,data_Y = loadSimpData() # print(adaBoostTrains(data_X,np.array([data_Y]).T)) classfierArr = adaBoostTrains(data_X,np.array([data_Y]).T) print(adaClassify(np.array([[0,0]]),classfierArr)) print(adaClassify(np.array([[5,5],[0,0]]),classfierArr))
(六)全部代码
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): #获取数据 data_X = np.array([ [1,2.1], # [2,1.1], #1.5 1.6 [1.5,1.6], [1.3,1], [1,1], [2,1] ]) data_Y = np.array([1,1,-1,-1,1]) return data_X,data_Y #一:单层决策树生成函数 #1.根据输入的特征列、阈值、不等号,获取当前的数据的类别为-1、1 def stumpClassfiy(data_X,dimen,threshVal,threshIneq): #传入数据集,特征选取维度,阈值,大于小于 classArr = np.ones((data_X.shape[0],1)) if threshIneq == "lt": classArr[np.where(data_X[:,dimen]<=threshVal)] = -1 #因为这里是小于等于,所以我们阈值到最大值,即可划分所有的数据集。见下方2 else: classArr[np.where(data_X[:,dimen]>threshVal)] = -1 return classArr #2.基于数据的权重向量D,来找来找数据集上的最佳的单层决策树 def buildStump(data_X,data_Y,D): m,n = data_X.shape numSteps = 10 #设置步数,用来进行阈值选取 bestStump = {} #使用字典来保存多个返回值,包括阈值选取,特征列选取,不等号选取 bestClasEst = np.zeros((m,1)) #用来保存最优的类别划分 minError = np.inf #保存最小误差(判断错误点的权重和) for i in range(n): #循环所有的特征列 rangeMin = np.min(data_X[:,i]) rangeMax = np.max(data_X[:,i]) #获取当前列的最大、最小值,根据上面设置的步数,在下面获取步长 stepSize = (rangeMax - rangeMin) / numSteps for j in range(-1,numSteps+1): #循环步数,来获取阈值(从最小值-一个步长,到最大值) #获取阈值threshVal threshVal = rangeMin + j*stepSize for ineq in ['lt','gt']: #因为在不同位置,我们选取大于或者等于得到的误差和是不同的,所以我们需要进行遍历,从而找出最优值 #获取预测的类别 predictClass = stumpClassfiy(data_X,i,threshVal,ineq) #判断预测的类别和实际的类别是否相等,从而获取错误信息 errArr = np.ones((m,1)) # print(predictClass.shape,data_Y.shape) errArr[predictClass==data_Y] = 0 #相等则为0,不计算误差 #获取加权后的误差 weightError = D.T@errArr #注意转置,因为我们在adaboost训练函数传入的是列向量 if weightError < minError: minError = weightError bestClasEst = predictClass bestStump['dimen'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = ineq return bestStump,minError,bestClasEst #因为后面更新α时,需要使用到误差的权重。更新权重的时候要使用到 #二:基于单层决策树实现的AdaBoost训练过程 def adaBoostTrains(data_X,data_Y,numIt=40): #后面表示迭代次数,当然如果在迭代次数内,实现误差为0,则退出 weakClassArr = [] #用来保存返回的数据 m,n = data_X.shape D = np.array(np.ones((m,1))/m) #初始化权重向量 aggClassEst = np.zeros((m,1)) #错误率计算 for i in range(numIt): #进行迭代 bestStump, minError, bestClasEst =buildStump(data_X,data_Y,D) print("D:",D) print("classEst",bestClasEst) alpha = 1/2*np.log((1-minError)/max(minError,1e-16)) #确保没有出错时,保证没有除0溢出 print("alpha:",alpha) bestStump['alpha'] = alpha #因为后面还需要alpha,所以这里保存 weakClassArr.append(bestStump) #将本次最情况的分类保存 #重新计算权重 expon = np.multiply(-1*alpha*data_Y,bestClasEst) #看公式 D = np.multiply(D,np.exp(expon)) D = D / np.sum(D) #进行归一化 aggClassEst += alpha*bestClasEst #错误率累加计算 print("aggClassEst:",aggClassEst) arrErrors = np.multiply(np.sign(aggClassEst)!=data_Y,np.ones((m,1))) #计算错误数目 errorRate = arrErrors.sum() / m #计算错误率 print("error rate:",errorRate) if errorRate == 0: break return weakClassArr #三:实现预测功能 def adaClassify(data_sim,classfierArr): #传入测试数据和分类器 #将所有的分类器的权重和即可得到最后结果 m,n = data_sim.shape aggClassEst = np.zeros((m,1)) for i in range(len(classfierArr)): classEst = stumpClassfiy(data_sim,classfierArr[i]['dimen'],classfierArr[i]['thresh'],classfierArr[i]['ineq']) aggClassEst += classEst*classfierArr[i]['alpha'] #累加权重 print(aggClassEst) return np.sign(aggClassEst) data_X,data_Y = loadSimpData() # print(adaBoostTrains(data_X,np.array([data_Y]).T)) classfierArr = adaBoostTrains(data_X,np.array([data_Y]).T) print(adaClassify(np.array([[0,0]]),classfierArr)) print(adaClassify(np.array([[5,5],[0,0]]),classfierArr))