一:视频为什么可以被压缩
视频信息之所以存在大量可以被压缩的空间,是因为其中本身就存在大量的数据冗余。
其主要类型有以下四种:
时间冗余:视频相邻的两帧之间内容相似,或者帧直接存在运动关系
空间冗余:视频的某一帧内部的相邻像素存在相似性,或者变化的相关性
编码冗余:视频中不同数据出现的概率不同(所以我们可以进行压缩编码)
视觉冗余:观众的视觉系统对视频中不同的部分敏感度不同,比如YUV中对Y亮度更加敏感
针对这些不同类型的冗余信息,在各种视频编码的标准算法中都有不同的技术专门应对,以通过不同的角度提高压缩的比率。
二:视频编码标准化组织
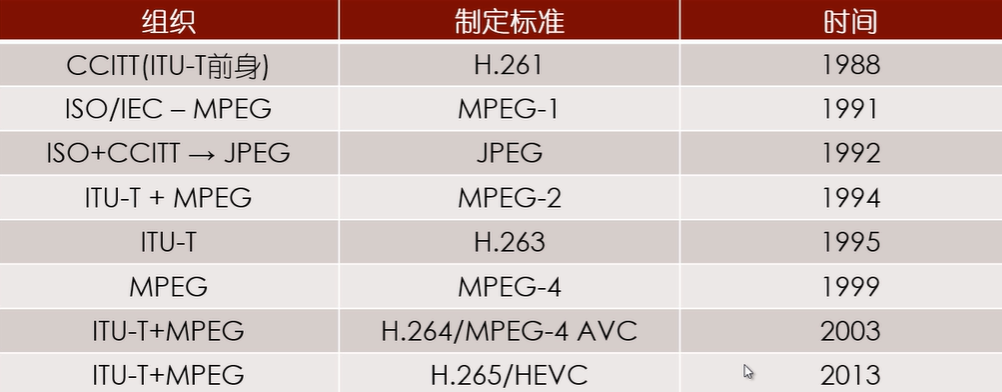
从事视频编码算法的标准化组织主要有两个,ITU-T和ISO
ITU-T,全称International Telecommunications Union - Telecommunication Standardization Sector,即国际电信联盟——电信标准分局。该组织下设的VCEG(Video Coding Experts Group)主要负责面向实时通信领域的标准制定,主要制定了H.261/H263/H263+/H263++等标准。
ISO,全称International Standards Organization,即国际标准化组织。该组织下属的MPEG(Motion Picture Experts Group),即移动图像专家组主要负责面向视频存储、广播电视、网络传输的视频标准,主要制定了MPEG-1/MPEG-4等。
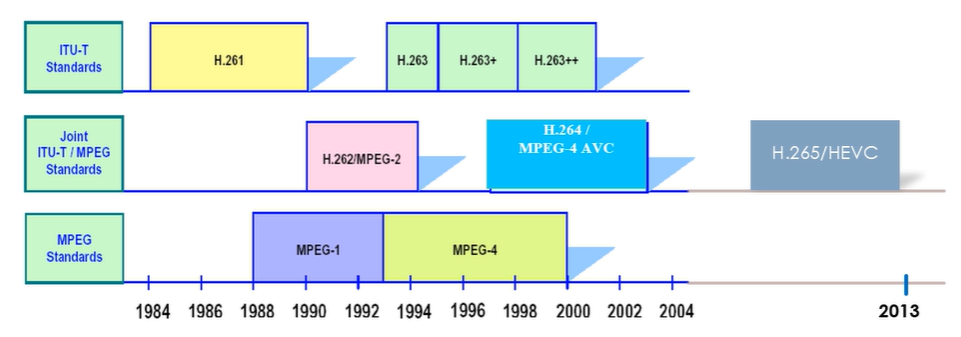
实际上,真正在业界产生较强影响力的标准均是由两个组织合作产生的。比如MPEG-2、H.264/AVC和H.265/HEVC等。
三:主流视频编解码标准的发展
(一)视频编解码标准发展总括
视频编码标准主要由前面提到的两个国际组织负责制定:国际电信联盟ITU-T和国际标准化组织ISO。
目前影响力最强的视频编码标准基本均出自这两个组织:
除了上述两个组织之外,其他比较有影响力的标准还有:
Google:VP8/VP9;
Microsoft : VC-1;
国产自主标准:AVS/AVS+/AVS2;
(二)H261标准(基于波形的混合编码的开始)
从H.261开始,视频编码方法采用了沿用至今的基于波形的混合编码方法。
H.261标准主要目标是用于视频会议和可视电话等高实时性、低码率的视频图像传输场合。
H261中CIF的由来:
在H.261标准产生的时代,由于各国的电视制式不一致,因此不能直接互通。为了解决数据源格式不兼容的问题,H.261定义了一种公共中间格式CIF(Common Intermediate Format)。
编码的目标格式首选转换为CIF格式进行编码和传输,接收端进行解码后再转换为各自的格式。
H.261规定的CIF格式视频的亮度分辨率为352×288,QCIF格式的亮度分辨率为176×144。
H261视频编解码器结构:
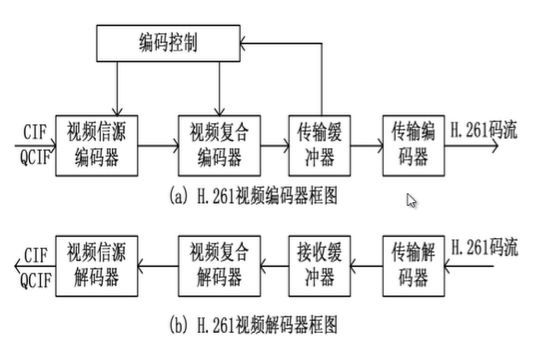
H261信源编解码器结构:为后面编解码方法奠定了基础,都是基于此进行改进,没有太大变化
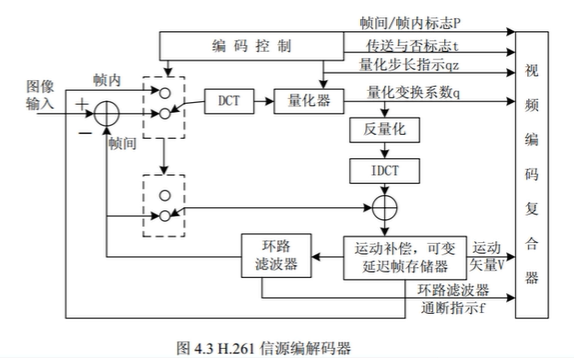
帧内编码/帧间编码判定:
根据帧与帧之间的相关性判定——相关性高使用帧间编码,相关性低使用帧内编码。
帧内编码:
对于帧内编码帧,直接使用DCT编码8×8的像素块。
帧间编码/运动估计:
使用以宏块为基础的运动补偿预测编码;
当前宏块从参考帧中查找最佳匹配宏块,并计算其相对偏移量(Vx, Vy)作为运动矢量;
编码器使用DCT、量化编码当前宏块和预测宏块的残差信号;
环路滤波器:
实际上是一个数字低通滤波器,滤除不必要的高频信息,以消除方块效应;
H261复合解码器结构:将不同层次的语法元素,编码为H261格式的码流
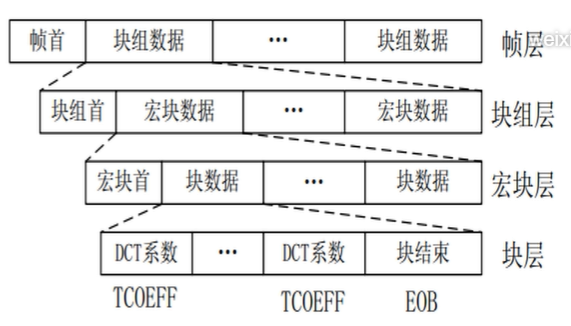
经过H.261码流复合器输出的码流,总共可以分为四层,从上到下分别为帧层、块组层、宏块层和块层。每一层按照不同的封装格式包含了头信息和下一层的结构。
帧层:
由帧首和块组数据构成;帧首包括帧起始码( PSC)、帧计数码( TR)、帧类型( PTYPE)等;
块组层:
由块组首和宏块数据组成;块组首包括组起始码( GBSC)、块组编号码( GN)、块组量化步长等;
宏块层(Macroblock,MB):
由宏块首和块数据构成;宏块首包括宏块地址码、宏块类型、宏块量化步长、运动矢量数据、编码模式等;
块层:
包括每个8×8块的DCT系数按之字形扫描后的熵编码码流,以块结束符结尾
(三)H263标准(H261改进标准)
同样以低码率视频通信为目标,但是具有更好的压缩效率。与H.261相比,H.263支持更多种分辨率的图像格式:
Sub-QCIF: 128×96 QCIF: 176×144 CIF:352×288
------下方清晰度更高----- 4CIF:704×576 16CIF:1480×1152
除了更多的分辨率选择之外,视频信源编码算法也相比H.261实现了多项改进:
运动矢量:相比于H.261,H.263的运动矢量分配更加灵活。在H.261中,每一个MB分配一个运动矢量;H.263中支持对每一个8×8像素块各自使用一个运动矢量。 MV精度:H.261只支持整数像素的运动矢量,在H.263中运动矢量精度为1/2像素。 双向预测模式:H.263的帧间编码帧除了P帧之外,也支持B帧,使用前后双向预测模式。 熵编码:采用了算术编码,以较高的运算复杂度换取更高的编码效率。
(四)MPEG-1标准(被MPEG-2淘汰)
MPEG-1是国际标准化组织ISO下属的移动图像专家组负责制定的早期视频压缩标准,主要用于视频信息的存储、广播电视和网络传输应用。
主要用于在VCD中存储音视频信息,保存的视频信息便使用MPEG-1标准进行压缩,其码率约为1.2~1.5Mb/s。
MPEG-1标准所支持的图像类型与H.263类似,支持I、B、P帧类型
I帧:帧内编码帧,采用帧内编码,可作为P/B帧的参考帧; P帧:前向预测帧,采用帧间编码,以I/P帧作为参考帧; B帧(非参考帧):双向预测帧,参考前后两个方向的参考帧;
在MPEG-1中图像的显示顺序为:
![]()
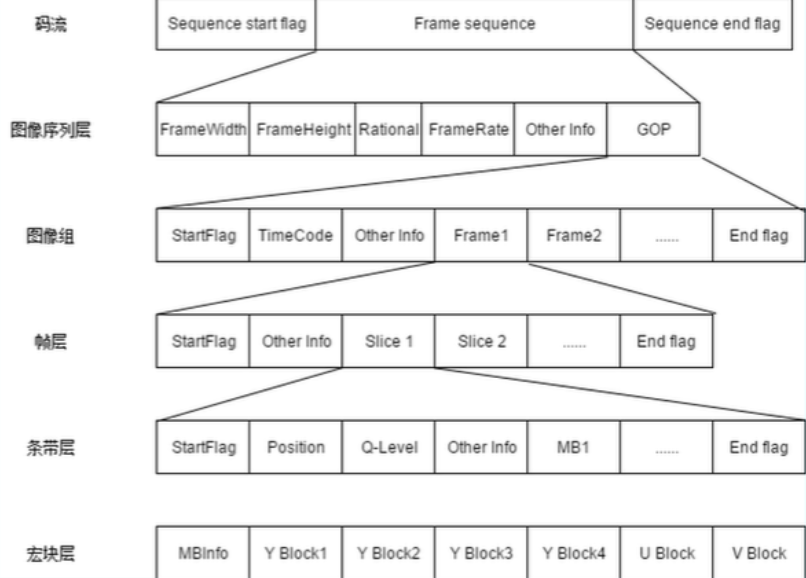
在码流的结构上,MPEG-1采用了与H.261类似的分层码流结构。
MPEG-1相比于H.261增加了条带层,每一个宏块所有的编码操作只能在一个条带内实现,条带层可以有效防止编码错误在一帧内扩散。
MPEG-1标准的码流结构如下图所示:
(五)MPEG-2标准(兼容MPEG-1)
MPEG-2标准是ITU-T和ISO合作制定的编码标准,其视频部分也称作H.262标准,其标准编号为ISO-13818。
ISO-13818是一系列标准的集合,包括了系统、视频、音频、一致性、参考软件等10个部分。
MPEG-2标准在数字电视广播和音视频媒体容器等场合得到了广泛应用,常见的DVD视盘采用的就是MPEG-2视频编码方法。(DVD可以播放VCD,因为MPEG-2兼容了MPEG-1)
MPEG-2格式的主要改进之处之一是支持支持逐行或者隔行扫描视频,使用基于帧或场的编码。
在MPEG-2中,为适应隔行扫描视频信号的特点,在DCT、预测和运动估计算法中对帧和场进行了不同的处理。
另一方面,MPEG-2根据不同的编码工具定义了5个Profile:
简单SP、主要MP、SNR可分级SNP、空间可分级SSP和高级HP。
根据视频分辨率的不同定义了4个Level:
低级LL、主级ML、高-1440级High1440和高级HL。
MPEG-2的码流分为三层:
基本流:ES,由视频编码的视频基本流和音频编码的音频基本流构成
打包基本流:PES,为音视频ES分别打包
传输流、节目流:TS/PS,若干个PES进行复用后输出,分别用于传输和存储
在MPEG-2的ES流层中,其码流结构采用了类似MPEG-1码流结构的分层封装的方法:
图像序列层:包括若干GOP,序列头包含起始码和序列参数等;
图像组(GOP)层:包括若干图像,GOP头包括起始码、GOP标识等;
图像层:包括若干个Slice,图像头中包括起始码和图像参数等;
片(Slice)层:最小的同步单位,包括若干宏块,Slice头中包括起始码、片地址、量化步长等信息;
宏块(Macroblock)层:由4个亮度块和2个色度块组成,宏块头包括地址、类型、MV等信息
(六)MPEG-4标准(在H264出来后,才被广泛应用)
同前任的MPEG-1和MPEG-2相比,MPEG-4更注重多媒体系统的交互性、灵活性和可扩展性。
MPEG-4的标准编号为ISO-14496,也包括多个部分,如系统、视觉信息、音频、一致性等。
MPEG-4中最为显著的特点是采用了基于对象的编码。
在MPEG-4中,一个视频对象主要定义为画面中分割出来的不同物体,每个物体由三类信息描述:运动信息、轮廓信息和纹理信息。
MPEG-4通过编码这三类信息来实现对视频对象的编码。
四:视频压缩编码的分类
主要可以分为以下两种大类别:基于波形的编码和基于内容的编码
(一)基于波形的编码(主流)
特点:编码的数据是针对于每一帧图像包含的像素值,即采样像素的波形。
方法:利用像素之间在时间与空间上的相关性,采用预测编码和变换编码结合的的基于块的混合编码方法(到目前任然是最主流的编解码方法)
代表:MPEG-1,MPEG-2,H264,H264等等
(二)基于内容的编码
特点:视频帧分成对应不同物体的区域,分别对其编码
方法:针对不同物体的形状、运动和纹理分别进行编码(运算复杂度太高,导致发展慢,不过CV方向发展挺多)
代表:MPEG-4
五:视频压缩编码的基本技术
为了专门处理视频信息中的多种冗余,视频压缩编码采用了多种技术来提高视频的压缩比率。其中常见的有预测编码、变换编码和熵编码等等
(一)预测编码:用于处理视频中的时间和空间域的冗余
预测编码通过传输预测像素值与实际像素值之差,利用时间或者空间相邻像素之间较强的相关性进行编码!
视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
1.帧内预测:
预测值与实际值位于同一帧内,用于消除图像的空间冗余;
帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据;
通常视频中的关键帧都采用帧内预测。
2.帧间预测:
帧间预测的实际值位于当前帧(预测的帧),参考值位于参考帧,用于消除图像的时间冗余;
帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。
通常在视频码流中,I帧全部使用帧内编码,P帧/B帧中的数据可能使用帧内或者帧间编码。
(二)变换编码
目前主流的视频编码算法(MPEG1,MPEG2,H264,H265)均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。
而造成信息损失的部分即在于变换量化这一部分:
在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频域,并计算其变换系数供后续的编码。
在视频编码算法中通常使用正交变换进行变换编码,常用的正交变换方法有:离散余弦变换(DCT)、离散正弦变换(DST)、K-L变换等。
(三)熵编码:主要用于消除视频信息中的统计冗余。
由于信源中每一个符号出现的概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。
通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。
在视频编码算法中常用的熵编码方法有变长编码和算术编码等,具体来说主要有上下文自适应的变长编码(CAVLC)和上下文自适应的二进制算术编码(CABAC),都是H264中常见的熵编码方法。
注意:变换编码和熵编码中包含有无损压缩技术
整数离散余弦变换(无损压缩技术): ----- 经过上面两种压缩后(帧内、帧间),数据已经很小了,但是还可以通过DCT变换,将有用数据集中,其他位置为0,进行压缩。可以减少复杂度,利于后面的无损压缩
CABAC压缩(无损压缩技术): ----- 根据上下文进行数据的压缩