Redis 数据结构
Redis 常用的数据类型主要有以下五种:
-
String
-
Hash
-
List
-
Set
-
Sorted set
Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。
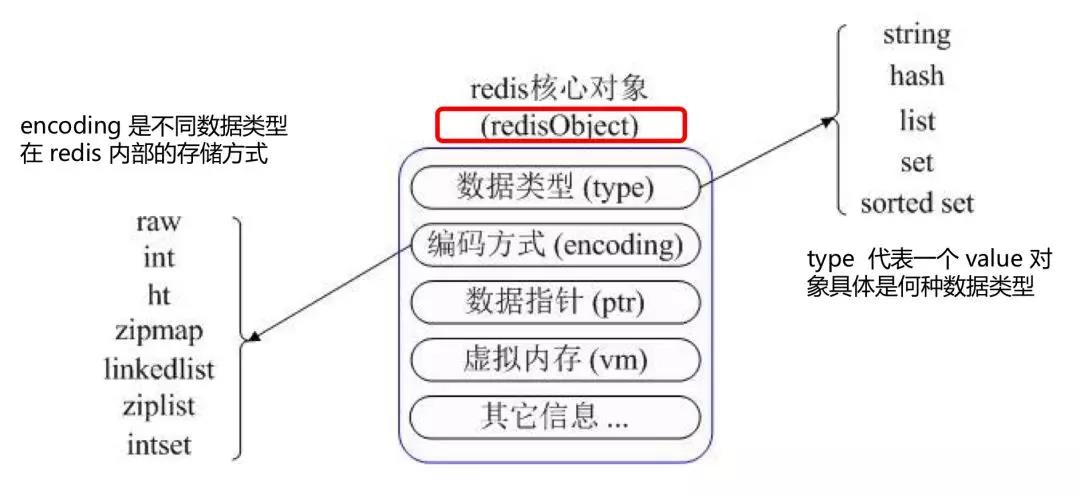
String 在 redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr,decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为int。
list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht。
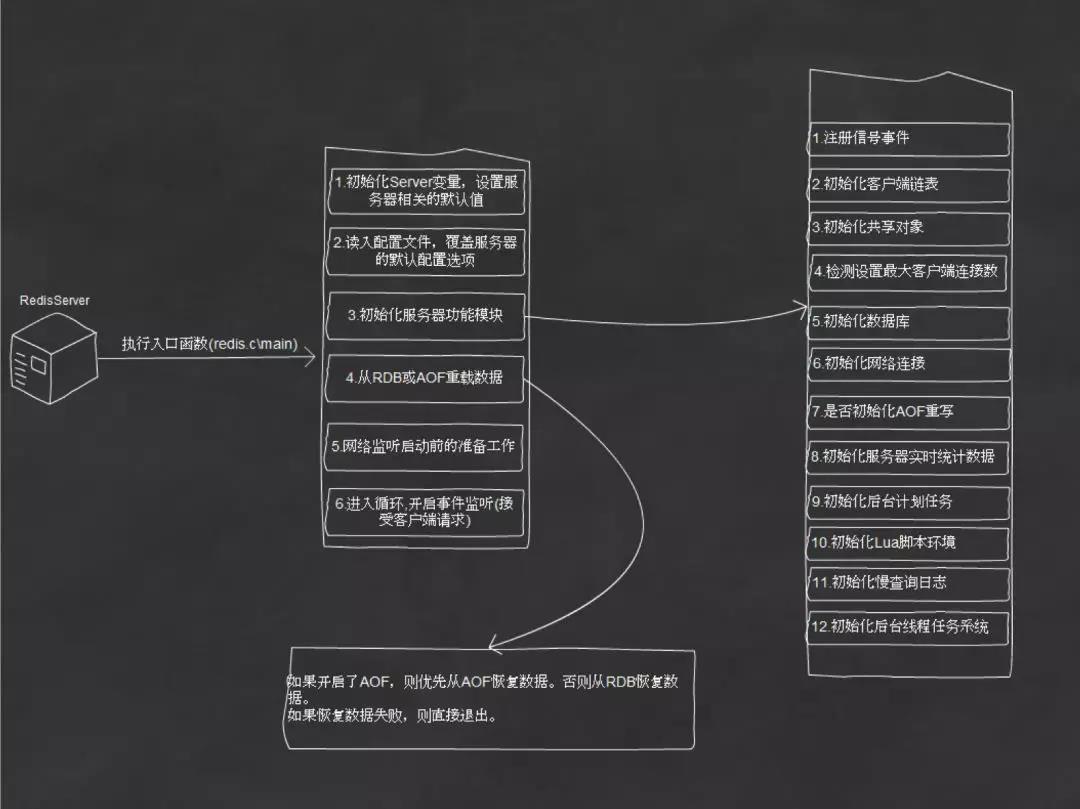
Redis 存储
Redis 提供了一系列不同的持久性选项:
-
RDB 持久性以指定的时间间隔执行数据集的时间点快照。
-
AOF 持久性会记录服务器接收到的每个写入操作,这些操作将在服务器启动时再次执行,重建原始数据集。使用与Redis协议本身相同的格式以追加方式记录命令。
RDB的优点:
-
RDB是Redis数据的非常紧凑的单文件时间点表示。
-
RDB文件非常适合备份。
RDB的缺点:
-
快照不是非常耐用。如果运行Redis的计算机停止运行,电源线出现故障,或者意外地终止了您的实例,写入Redis的最新数据将丢失。
-
为了使用子进程在磁盘上保留RDB,RDB需要经常fork。如果数据集很大,Fork会很费时,并且可能导致Redis在几毫秒内停止服务客户端,或者如果数据集非常大并且CPU性能不佳,甚至会持续一秒。
Redis 需要将数据集转储到磁盘时,会发生以下情况:
-
Redis fork。我们现在有一个子进程和一个父进程。
-
子进程开始将数据集写入临时RDB文件。
-
当子进程写完新的RDB文件后,它会替换旧的。
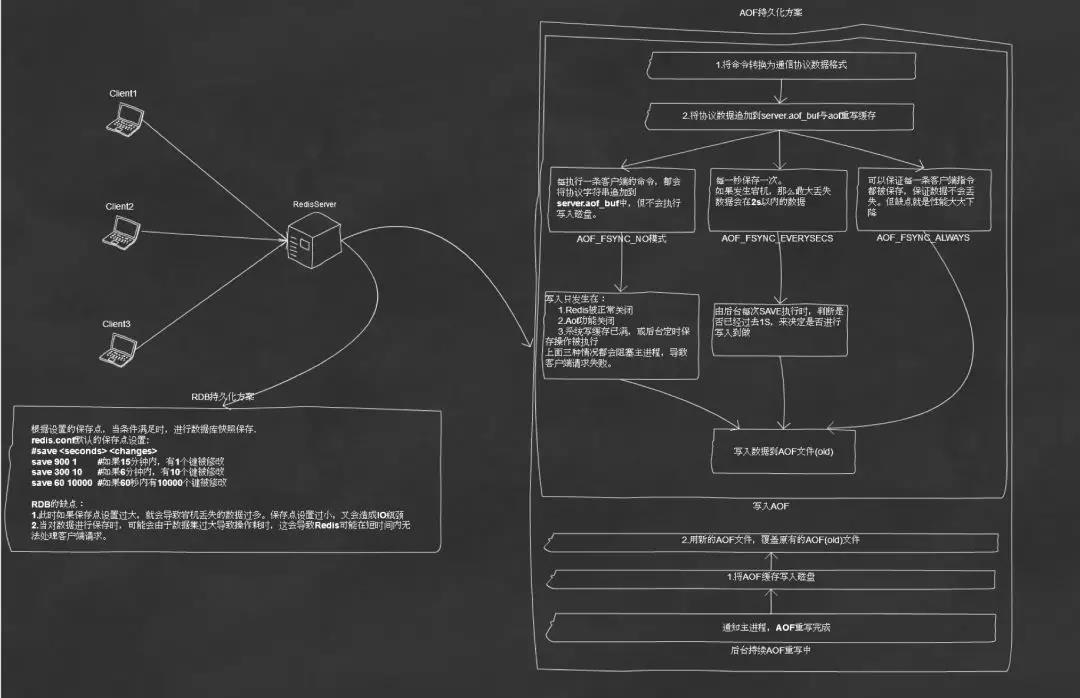
AOF的优势:
AOF日志是一种只能追加的日志,因此如果发生停电,也不会出现问题。
AOF的缺点:
-
AOF文件通常比相同数据集的等效RDB文件大。
-
根据确切的fsync策略,AOF可能比RDB慢。
Redis将在磁盘上同步数据的次数。有三种选择:
-
每当一个新命令被附加到AOF时,fsync。非常非常缓慢,非常安全。
-
每秒fsync。足够快(在2.4可能与快照一样快),并且如果发生灾难,您可能会丢失1秒的数据。
-
永远不要fsync,只需将您的数据交给操作系统即可。更快,不安全的方法。
日志重写使用已用于快照的相同的写入时复制技巧。这是如何工作的:
-
Redis fork,所以现在我们有子进程和一个父进程。
-
子进程开始在临时文件中写入新的AOF
-
父进程将所有新的更改累积到内存缓冲区中
-
当子进程完成重写文件时,父进程获取信号,并在子进程生成的文件末尾追加内存缓冲区的内容。
-
Redis自动将旧文件重命名为新文件,并开始将新数据附加到新文件中。
Redis 事务
Redis 提供的事务机制与传统的数据库事务有些不同,传统数据库事务必须维护以下特性:原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability),简称ACID。
原子性(Atomicity)
Redis 本身提供的所有 API 都是原子操作。
但 Redis 在事务执行过程的错误情况做出了权衡取舍,那就是放弃了回滚。
Redis 官方文档对此给出的解释是:
1、Redis 操作失败的原因只可能是语法错误或者错误的数据库类型操作,这些都是在开发层面能发现的问题不会进入到生产环境,因此不需要回滚。
2、Redis 内部设计推崇简单和高性能,因此不需要回滚能力。
一致性(Consistency)
一致性意味着事务结束后系统的数据依然保证一致。
Redis 舍弃了回滚的设计,基本上也就舍弃对数据一致性的有效保证。
隔离性(Isolation)
隔离性保证了在事务完成之前,该事务外部不能看到事务里的数据改变。
Redis 采用单线程设计,隔离性得到保证。
持久性(Durability)
Redis 一般情况下都只进行内存计算和操作,持久性无法保证。
但 Redis 也提供了2种数据持久化模式,RDB 和 AOF,RDB 的持久化操作与命令操作是不同步的,无法保证事务的持久性。而 AOF 模式意味着每条命令的执行都需要进行系统调用操作磁盘写入文件,可以保证持久性,但会大大降低 Redis 的访问性能。
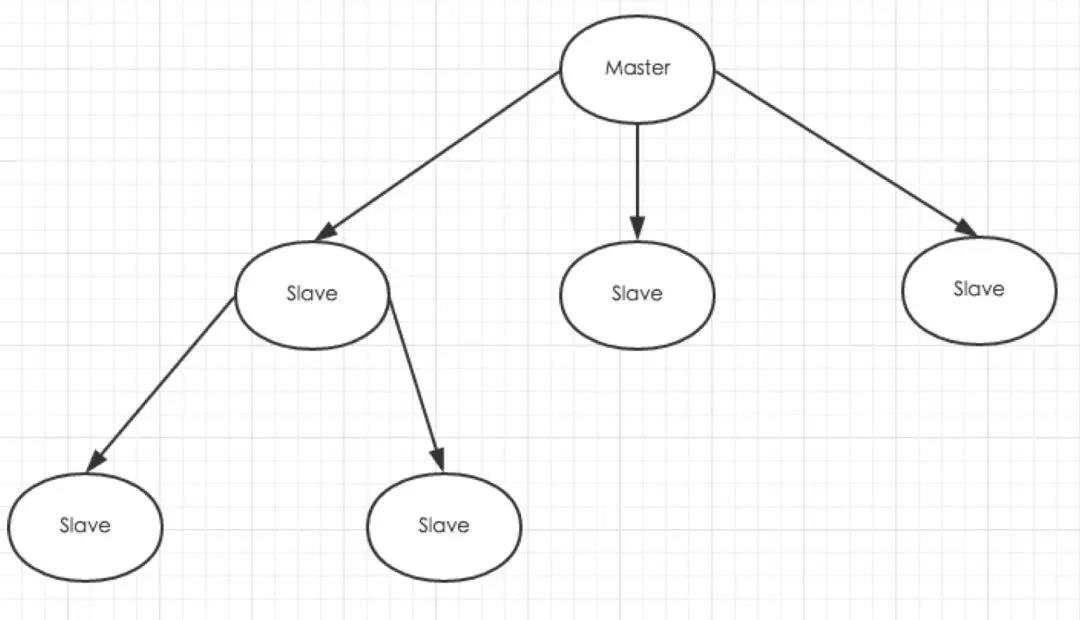
Redis 主从
Redis的主从结构可以采用一主多从或者级联结构:
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。

Redis 场景
常见的 NoSQL 方案分为 4 类。
-
K-V 存储:解决关系数据库无法存储数据结构的问题,以 Redis 为代表。
-
文档数据库:解决关系数据库强 schema 约束的问题,以 MongoDB 为代表。
-
列式数据库:解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表。
-
全文搜索引擎:解决关系数据库的全文搜索性能问题,以 Elasticsearch 为代表。
缓存的架构设计要点:
缓存穿透是指缓存没有发挥作用,业务系统虽然去缓存查询数据,但缓存中没有数据,业务系统需要再次去存储系统查询数据。
通常情况下有两种情况:
-
1、存储数据不存在
-
2、缓存数据生成耗费大量时间或者资源
缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。
缓存热点的解决方案就是复制多份缓存副本,将请求分散到多个缓存服务器上,减轻缓存热点导致的单台缓存服务器压力。

首页分流加载
