机器学习中会遇到一些离散型数据,无法带入模型进行训练,所以要对其进行编码,常用的编码方式有两种:
1、特征不具备大小意义的直接独热编码(one-hot encoding)
2、特征有大小意义的采用映射编码(map encoding)
两种编码在sklearn.preprocessing包里有实现方法
映射编码就是用一个字典指定不同离散型数据对应哪些数字
import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'label1'], ['red', 'L', 13.5, 'label2'], ['blue', 'XL', 15.3, 'label2']]) # color、label不具备大小含义,size具有大小意义 df.columns = ['color', 'size', 'length', 'label'] size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping)
one-hot编码有两种形式:
1.one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
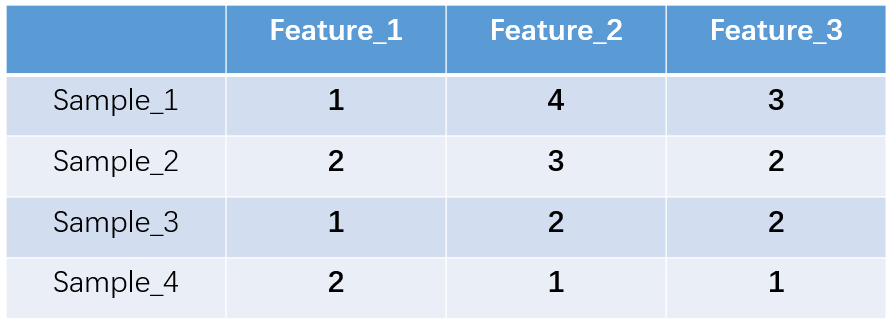
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:
这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,所以我们可以得到这些样本特征的新表示:
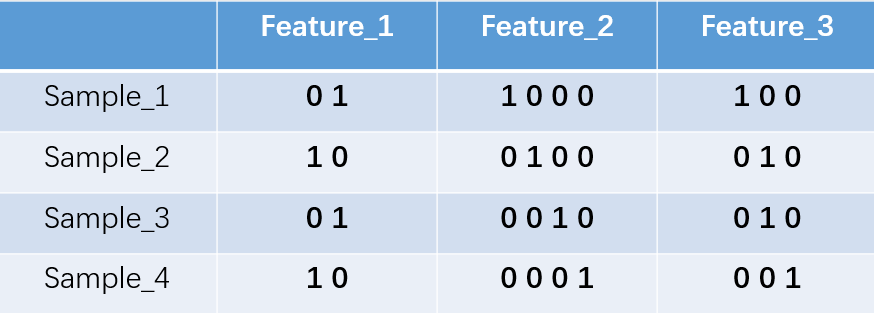
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
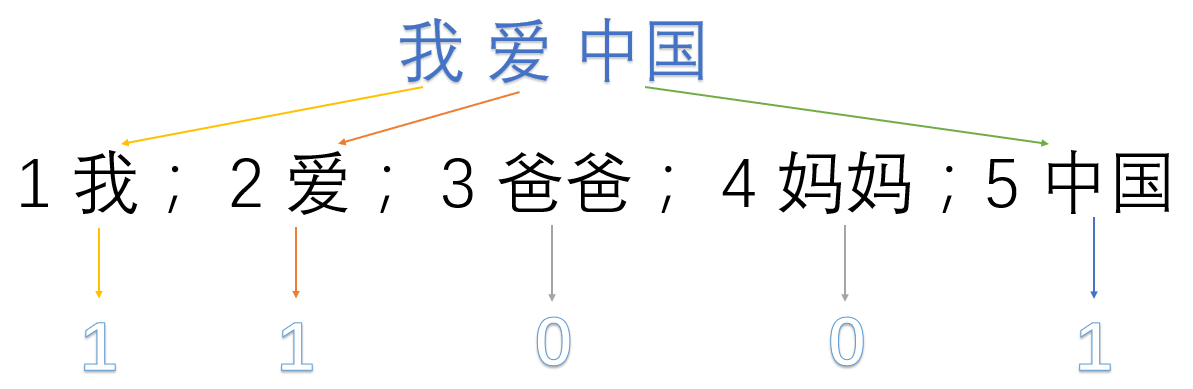
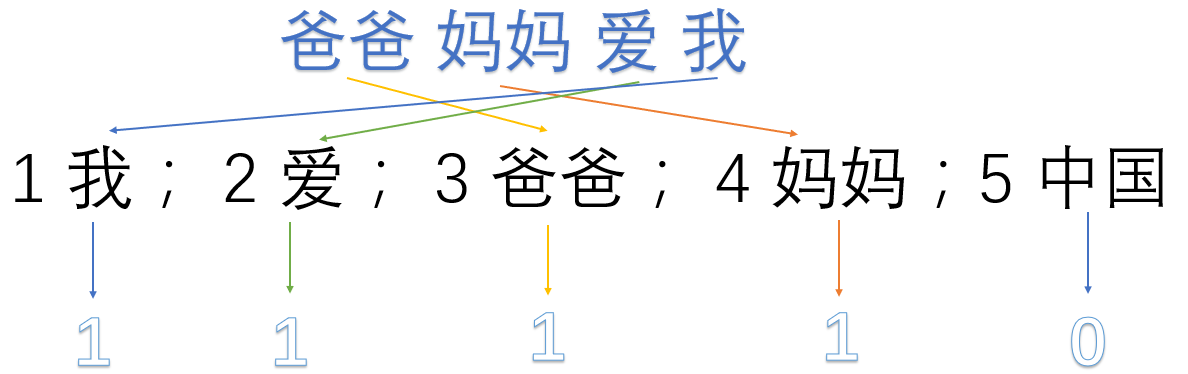
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
 ;
; ;
;
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

2.dummy encoding,哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

dummy encoding在pandas中有get_dummies()方法可以实现