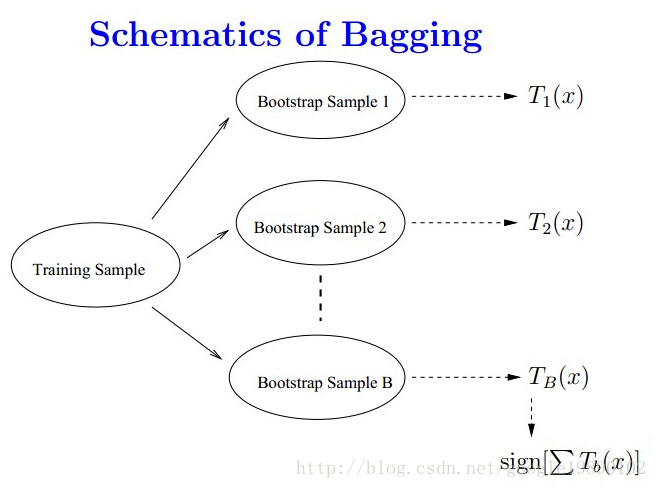
1.Bagging
Bagging又叫自助聚集,是一种根据均匀概率分布从数据中重复抽样(有放回)的算法
每个抽样生成的自助样本集上,训练一个基分类器;对训练过的分类器进行投票,将测试样本指派到得票最高的类中。
- 分类问题:采用投票的方法,得票最多的类别为最终的类别
- 回归问题:采用简单的平均方法
2.Adaboost
Adaboost算法有两个权重,一个是弱学习器的权重∂,一个是样本的权重D
核心思想就是一次次地对样本进行训练,每次训练完后都生成两个权重:
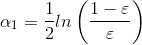
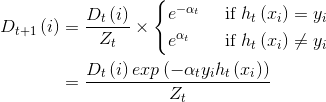

样本根据权重D进行更新,这样每轮学习后都可以学得一个模型hi,最后的模型就是:

每次对分类错误的样本和错误率高的学习器的权重加大
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
3.Stack
Stack的思想有点像神经网络
1.划分训练数据集为两个不相交的集合。
2. 在第一个集合上训练多个学习器。
3. 在第二个集合上测试这几个学习器
4. 把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器
这里弱学习器的结果作为高层学习器的样本的特征
sklearn中集成学习的函数:
sklearn.ensemble.xxx
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble