-
一、scrapy框架的简介和基础使用
-
二、scrapy框架--parse方法解析示例
-
三、scrapy框架--基于终端指令的持久化存储
-
四、scrapy框架--基于管道的持久化存储
-
五、scrapy框架--基于MySQL数据库的持久化存储
-
六、scrapy框架--基于redis的持久化存储
-
七、scrapy框架--将爬取到的数据分别存储在本地磁盘、redis、MySQL中
-
八、scrapy框架--多个url数据爬取(请求手动发送)
-
九、scrapy框架--核心组件
-
十、scrapy框架--发送post请求
-
十一、scrapy框架--session的使用
-
十二、scrapy框架--代理的使用
-
十三、scrapy框架--日志等级
-
十四、scrapy框架--请求传参
-
十五、scrapy框架--CrawlSpider的使用
-
十六、scrapy框架--分布式爬虫RedisCrawlSpider
-
十七、scrapy框架--分布式爬虫RedisSpider
-
十八、scrapy框架--UA池、代理池
-
十九、scrapy框架--综合应用(爬网易新闻)
-
二十、scrapy框架--总结
===============================================
一、scrapy框架的简介和基础使用
a)概念:为了爬取网站数据而编写的一款应用框架,出名,强大。
框架其实就是一个集成了相应功能且具有很强通用性的项目模板。
(高性能的异步下载,解析,持久化...)
b) 安装:
i. linux mac --pip install scrapy
ii. windows
-step1: pip install wheel
-step2: 下载并安装twisted: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install 下载好的t框架.whl
-step3: pip install pywin32
-step4: pip install scrapy
c) 测试安装是否成功:
命令终端输入“scrapy”后出现scrapy版本号
d) 基础使用:使用流程
i. 创建一个工程,在某目录的命令行:scrapy startproject 工程名称
ii. 在工程目录下创建一个爬虫文件:
-step1: cd 工程名称
-step2: scrapy genspider 爬虫文件名称 起始url
例如:scrapy genspider first www.qiushibaike.com
------------------------------------------------------------------------
附:目录结构说明
spiders 爬虫目录,如:创建文件,编写爬虫解析规则
settings.py 配置文件,如:递归的层数,并发数,延迟下载等
pipelines 数据持久化处理
items.py 设置数据存储模板,用于结构化数据,如Django的Model
scrapy.cfg 项目的主配置信息(真正爬虫相关的配置信息在settings.py文件中)
------------------------------------------------------------------------
iii.对应的文件中编写爬虫程序来完成爬虫的相关操作


# -*- coding: utf-8 -*- import scrapy class FirstSpider(scrapy.Spider): # 爬虫文件的名称:用来定位到某一个爬虫文件,因为一个项目可以有多个爬虫文件 name = 'first' # 允许的域名:存放一系列域名,只能爬取该列表内的域名 # 一般可以注释掉,如果想爬取图片等就可能不在这个域名 allowed_domains = ['www.qiushibaike.com'] # 起始url:就是当前工程想爬取的url页面,必须在允许的域名内 start_urls = ['http://www.qiushibaike.com/'] # 解析方法:对获取的页面数据进行指定内容的解析,建议使用xpath进行解析 # 根据起始url发起请求,response是请求成功后拿到的响应对象 # parse方法返回值必须为迭代器或者None def parse(self, response): print(response.text)
iv. 配置文件settings.py的编写
第22行:ROBOTSTXT_OBEY = False # 不遵守robots协议
第19行:USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
v. 执行:scrapy crawl 爬虫文件的名称 --nolog
如果后面加--nolog不输出日志信息
当前的工程从爬虫文件开始执行,scrapy框架会向起始url列表中的url发起请求,请求成功后获取响应对象,传给parse方法,然后调用parse方法进行解析
二、scrapy框架--parse方法解析示例
--需求:解析糗百中段子的内容和作者
1.创建一个工程:scrapy startproject qiubaiPro
2.创建一个爬虫文件:
cd qiubaiPro/
scrapy genspider qiubai www.qiushibaike.com/text
3.编写代码(爬虫文件):
# -*- coding: utf-8 -*-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
# xpath解析到的内容被存储到了Selector对象中
# 可以用extract()方法获取Selector里的数据
# extract_first()等价于extract()[0]
author = div.xpath('./div/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
4.配置文件的编写:改19、22行
5.执行工程
三、scrapy框架--基于终端指令的持久化存储
i. 保证parse方法返回一个可迭代对象(存储解析到的页面内容)
# -*- coding: utf-8 -*-
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
data_list = []
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
dict = {"author":author, "content":content}
data_list.append(dict)
return data_list
ii. 使用终端指令完成数据存储到指定磁盘文件
scrapy crawl 爬虫文件名称 -o 磁盘文件.csv --nolog
四、scrapy框架--基于管道的持久化存储
i. items.py:存储解析到的页面数据
ii. pipelines:处理持久化存储的相关操作
iii. 代码实现流程:
0. 给items对象加属性
1. 将解析到的页面数据存储到items对象
2. 使用yield关键字将items提交给管道文件进行处理
3. 在管道文件中编写代码完成数据存储的操作
4. 在配置文件中开启管道操作
5. 执行
0:items加属性,取的时候只能item["author"] 不能item.author
import scrapy
class QiubaiproItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()
1. 将解析到的数据(author和content)存储到items对象
# -*- coding: utf-8 -*-
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
# 1,将解析到的数据(author和content)存储到items对象
item = QiubaiproItem()
item["author"] = author
item["content"] = content
# 2,将item对象提交给管道
yield item
3. 在管道文件中编写代码完成数据存储的操作
class QiubaiproPipeline(object):
fp = None
# 整个爬虫过程中,open方法只会在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./qiubai_pipe.text','w',encoding='utf8')
# 该方法可以接受爬虫文件中提交过来的item对象,并且对item对象中存储的页面数据进行持久化
# 参数item:接收到的item对象
# 每当爬虫文件yield一次item,该方法就会被执行一次
# 文件'qiubai_pipe.text'在整个过程只打开一次,关闭一次,文件中就不会只有一条记录
def process_item(self, item, spider):
# 取出item对象中的数据
author = item["author"]
content = item["content"]
# 持久化存储
self.fp.write(author+":"+content+"
")
return item
# close方法只会在爬虫结束的时候被调用一次
def close_spider(self,spider):
print('爬虫结束')
self.fp.close()
4. 在配置文件中开启管道操作
第68行:取消注释(数字表示优先级,这里只有一个所以没有谁先谁后)
ITEM_PIPELINES = {
'qiubaiPro.piplines.QiubaiproPipeline':300,
}
5.执行:scrapy crawl qiubai --nolog
五、scrapy框架--基于MySQL数据库的持久化存储
编码流程跟管道一样,只是第3步不同。
0. 给items对象加属性
1. 将解析到的页面数据存储到items对象
2. 使用yield关键字将items提交给管道文件进行处理
3. 在管道文件中编写代码完成数据存储的操作(连接数据库-》执行SQL语句-》提交事务)
4. 在配置文件中开启管道操作
5. 执行
import pymysql
class QiubaiproPipeline(object):
cursor = None
conn = None
def open_spider(self, spider):
print('开始爬虫')
# 1.连接数据库
self.conn = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='mysql8',
db='qiubai')
def process_item(self, item, spider):
# 2.执行SQL语句
sql = 'insert into qiubai values("%s","%s")'%(item["author"], item["content"])
self.cursor = self.conn.cursor()
try:
self.cursor.excute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
print('爬虫结束')
# 3.关闭连接
self.cursor.close()
self.conn.close()
六、scrapy框架--基于redis的持久化存储
编码流程跟管道一样。只是第3步不同
0. 给items对象加属性
1. 将解析到的页面数据存储到items对象
2. 使用yield关键字将items提交给管道文件进行处理
3. 在管道文件中编写代码完成数据存储的操作(连接redis-》存储数据)
4. 在配置文件中开启管道操作
5. 执行
import redis
class QiubaiproPipeline(object):
conn = None
def open_spider(self, spider):
print('开始爬虫')
# 1.连接redis
self.conn = redis.Redis(host='127.0.0.1', port=6379)
def process_item(self, item, spider):
# 2.存储数据
dict = {'author' : item["author"], 'content' : item["content"] }
self.conn.lpush('data', dict)
return item
七、scrapy框架--将爬取到的数据分别存储在本地磁盘、redis、MySQL中
1. 在管道文件中编写对应平台的管道类
在管道文件中定义三个类。如果下面自定义的两个类也被调用,那也可以写入
2. 在配置文件中对自定义的管道类进行生效操作
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipeline': 300,
'qiubaiPro.pipelines.QiubaiByFiles': 400,
'qiubaiPro.pipelines.QiubaiByMysql': 500,
}
import redis
#实现将数据存储到redis中
class QiubaiproPipeline(object):
conn = None
def open_spider(self, spider):
print('开始爬虫')
# 1.连接redis
self.conn = redis.Redis(host='127.0.0.1', port=6379)
def process_item(self, item, spider):
# 2.存储数据
dict = {'author' : item["author"], 'content' : item["content"] }
self.conn.lpush('data', dict)
return item
#实现将数据存储到本地磁盘
class QiubaiByFiles(object):
def process_item(self, item, spider):
print('写入到本地磁盘')
return item
#实现将数据存储到mysql数据库
class QiubaiByMysql(object):
def process_item(self, item, spider):
print('写入到mysql')
return item
八、scrapy框架--多个url数据爬取(请求手动发送)
需求:爬取糗百所有页码的作者和文章
跟单个url爬取一样,只是标红部分不同
=========items.py============
import scrapy
class QiubaibypagesItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()
=========qiubai.py============
import scrapy
from qiubaiByPages.items import QiubaibypagesItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
start_urls = ['https://www.qiushibaike.com/text/']
# 设计一个通用的url模板
page_num = 1
url = 'https://www.qiushibaike.com/text/page/%d/'
def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div[@class="author clearfix"]/a[2]/h2//text()').extract_first()
content = div.xpath('.//div[@class="content"]/span//text()').extract_first()
# 创建一个item对象,将解析到的数据存储到item对象
item = QiubaibypagesItem()
item["author"] = author
item["content"] = content
# 将item对象提交给管道
yield item
# 请求的手动发送,13表示最后一页页码
if self.page_num <= 13:
print("爬取到了第%d页."%self.page_num)
self.page_num += 1
new_url = format(self.url % self.page_num)
yield scrapy.Request(url=new_url, callback=self.parse)
=========pipelines.py============
class QiubaibypagesPipeline(object):
fp = None
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./qiubai.txt','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(item["author"]+":"+item["content"]+" ")
return item
def close_spider(self,spider):
self.fp.close()
print('爬虫结束')
=========settings.py============
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'qiubaiByPages.pipelines.QiubaibypagesPipeline': 300,
}
九、scrapy框架--核心组件
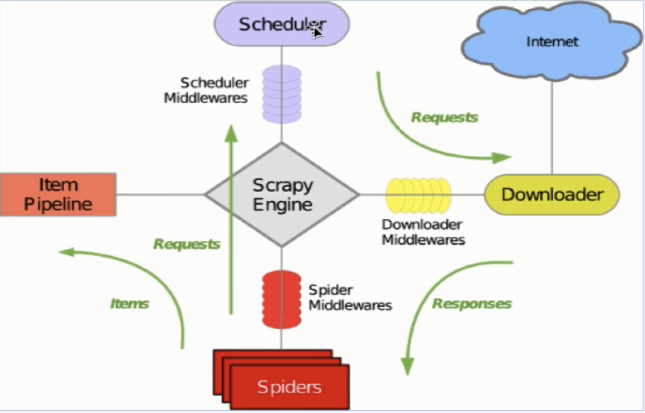
引擎接收到start_url列表中的请求对象,转交给调度器
请求被调度器装到队列里,由调度器调度请求给下载器
下载器从互联网下载后将结果转交给spiders
spiders接收到响应对象后,调度器调用parse方法对页面进行解析
spiders将解析结果封装到items,提交给管道
管道收到items后进行持久化
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
十、scrapy框架--发送post请求
发送post请求一定要对start_requests方法进行重写。
方式1.Request()方法中给method属性赋值
方式2.FormRequest()进行post请求的发送(推荐)
需求:给百度翻译发送post请求带参数
===========spiders=============
import scrapy
class PostdemoSpider(scrapy.Spider):
name = 'postDemo'
start_urls = ['https://fanyi.baidu.com/sug']
'''
之前一直是发的get请求:
覆盖父类的start_requests方法,对start_url列表中的元素进行get请求的发送
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
'''
'''
如何发起post请求?
1.将Request方法中的method参数赋值成post
2.FormRequest()可以发起post请求(推荐)
'''
def start_requests(self):
data = {
'kw' : 'dog',
}
for url in self.start_urls:
#formdata请求参数对应的字典
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
def parse(self, response):
print(response.text)
十一、scrapy框架--session的使用
第二次请求的时候,会自动携带第一次请求的cookie,在使用scrapy进行cookie操作的时候,不需要刻意管cookie
需求:爬取豆瓣的个人主页。先登录再查看主页
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['www.douban.com']
start_urls = ['https://www.douban.com/accounts/login']
# 登录发送post请求
def start_requests(self):
data = {
'source': 'index_nav',
'form_email': '18212345678',
'form_password': '123456'
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse)
#针对个人主页数据进行解析
def parse_second_page(self, response):
fp = open('second.html', 'w', encoding='utf8')
fp.write(response.text)
fp.close()
def parse(self, response):
#登录成功后的页面数据进行存储
fp = open('main.html', 'w', encoding='utf8')
fp.write(response.text)
#获取当前用户的个人主页
url = 'https://www.douban.com/people/18212345678/'
yield scrapy.Request(url=url,callback=self.parse_second_page)
fp.close()
十二、scrapy框架--代理的使用
原理:
#代理需要下载器的中间件,位于调度器和下载器之间
#拦截调度器发给下载器的请求,进行IP的更换
代码实现流程:
1.下载中间件类的自定义,重写process_request方法,拦截到请求后会调用该方法:
# 自定义一个下载中间件的类,在类中实现process_request方法
# 处理中间件拦截到的请求
class MyProxy(object):
def process_request(self, request, spider):
#进行请求IP的更换,IP为代理IP
request.meta['proxy'] = "http://120.76.77.152:9999"
2.配置文件中进行代理的开启
DOWNLOADER_MIDDLEWARES = {
'proxyPro.middlewares.MyProxy': 543,
}
十三、scrapy框架--日志等级
日志:运行爬虫时,会在控制台打印出一系列的信息
日志等级:
ERROR: 错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息(默认)
默认是输出调试信息。
如果只想让终端打印某个类型的信息,就在settings.py中添加LOG_LEVEL,
如果想将信息输出到文件就添加LOG_FILE:
LOG_LEVEL = 'ERROR'
LOG_FILE = 'log.txt'
十四、scrapy框架--请求传参
请求传参:解决的问题是爬取的数据不在同一个页面中
需求:将id97电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
=============爬虫文件=============
# -*- coding: utf-8 -*-
import scrapy
from moviePro.items import MovieproItem
class MovieSpider(scrapy.Spider):
name = 'movie'
start_urls = ['http://www.id97.com/movie/']
#用于解析二级子页面中的数据
def parse_by_second_page(self,response):
actor = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[2]/a/text()').extract_first()
language = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[6]/td[2]/a/text()').extract_first()
long_time = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/a/text()').extract_first()
#取出Request方法的meta参数传递过来的字典(response.meta)
item = response.meta['item']
item['actor'] = actor
item['language'] = language
item['long_time'] = long_time
#将item提交给管道
yield item
def parse(self, response):
#名称,类型,导演,语言,片长
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div')
for div in div_list:
name = div.xpath('.//div[@class="meta"]/h1/a/text()').extract_first()
kind = div.xpath('.//div[@class="otherinfo"]//text()').extract_first()
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first()
item = MovieproItem()
item['name'] = name
item['kind'] = kind
#要将其他数据存到item,就要进行请求传参(meta)
#需要对url发起请求,获取页面数据,进行指定数据解析,meta把item传给回调函数
#meta参数只能赋值给一个字典(将item对象先封装到字典)
yield scrapy.Request(url=url, callback=self.parse_by_second_page,meta={'item': item})
=============items文件============
import scrapy
class MovieproItem(scrapy.Item):
name = scrapy.Field()
kind = scrapy.Field()
actor = scrapy.Field()
language = scrapy.Field()
long_time = scrapy.Field()
十五、scrapy框架--CrawlSpider的使用
CrawlSpider的作用:
CrawlSpider会根据某一个提取规则提取全站所有链接,并提取链接的链接...一直到全部提取完。
问题:想对某个网站全站的数据进行爬取,例如爬取所有页码的数据
解决方案:
1.手动请求的发送, 递归
2.CrawlSpider(推荐)
CrawlSpider是Spider的一个子类。比Spider功能更强大(链接提取器,规则解析器)
1.创建一个基于CrawlSpider的爬虫文件:scrapy genspider -t crawl chouti dig.chouti.com/
2.使用方法:
==============爬虫文件=============
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ChoutiSpider(CrawlSpider):
name = 'chouti'
start_urls = ['https://dig.chouti.com//']
# 实例化一个链接提取器对象
# 链接提取器用来提取指定的链接
# allow参数:赋值一个正则表达式
# 链接提取器可以根据正则表达式在页面中提取指定的链接
# 会提取满足正则表达式的所有,一般用来提取链接,提取到的链接会全部交给规则解析器
link = LinkExtractor(allow=r'/all/hot/recent/d+')
rules = (
#实例化一个规则解析器对象
#规则解析器接收了链接提取器发送的链接后,就会对这些链接发起请求,获取链接对应的页面内容,然后根据指定的规则所有的页面数据进行解析
#callback:指定一个解析规则(方法/函数)
#fallow:表示是否将链接提取器继续作用到链接提取器提取出的页面数据中
#如果follow=True会产生大量重复链接,不影响,调度器会进行去重操作
Rule(link, callback='parse_item', follow=False),
)
def parse_item(self, response):
#链接提取器提取了多少个链接,parse_item方法就执行多少次
print(response)
十六、scrapy框架--分布式爬虫RedisCrawlSpider
分布式爬虫:
1.概念:多台机器上可以执行同一个爬虫程序,实现网站数据的分布式爬取
A机器爬取一部分内容,B机器爬取一部分内容,最后整合
2.原生的scrapy不能实现分布式爬虫,因为--
调度器和管道无法在A、B...多台机器共享,原生scrapy是五大组件配合进行网络数据的爬取
A、B两个机器都有单独的五大组件,这样执行结束后,都下载了单独的一份数据,都存储了单独的一份数据
3.scrapy-redis组件:专门为scrapy开发的一套组件,该组件可以让scrapy实现分布式。
4.分布式爬取流程
4.1*安装: pip install scrapy-redis
4.2*配置redis.conf: 两个位置
bind 127.0.0.1 #注释掉
protected-mode no #yes改为no,关闭保护模式
4.3*启动redis服务: ./redis-server ./redis-conf
4.4*启动redis客户端: ./redis-cli
4.5*创建工程: scrapy startproject redisPro
4.6*创建CrawlSpider: scrapy genspider -t crawl qiubai www.qiushibaike.com/pic
4.7*导入RedisCrawlSpider让爬虫类继承该RedisCrawlSpider
4.8*将start_url修改成redis_key='xxx' #表示调度器队列名称
4.9*编写parse_item
4.10*将管道和调度器配置成基于scrapy-redis组件可以共享的:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停,如果某台机器宕机,从宕机地方继续爬取
SCHEDULER_PERSIST = True
#如果redis服务器不在本机,需要进行如下配置
REDIS_HOST = '192.168.0.100' #本机的IP
REDIS_PORT = 6379
REDIS_PARAMS = {'password':'123456'}
4.11*执行爬虫文件,进入爬虫文件所在目录:scrapy runspider qiubai.py
4.12*启动redis客户端,将起始url扔进队列里:
lpush redis-key 起始url
lpush qiubai_spider https://www.qiushibaike.com/pic/
4.13*在其他电脑上同样执行:
scrapy runspider qiubai.py
lpush qiubai_spider https://www.qiushibaike.com/pic/
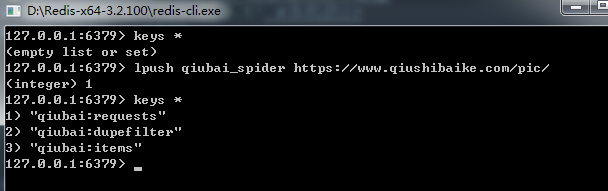
需求:爬取糗百全站的图片链接保存在redis,https://www.qiushibaike.com/pic/
====爬虫文件=========
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
from redisPro.items import RedisproItem
class QiubaiSpider(RedisCrawlSpider):
name = 'qiubai'
# 表示跟start_url含义一样,表示是调度器队列的名称
redis_key = 'qiubai_spider'
link = LinkExtractor(allow=r'/pic/page/d+')
rules = (
Rule(link, callback='parse_item', follow=True),
)
def parse_item(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
img_url = "https://"+div.xpath('.//div[@class="thumb"]/a/img/@src').extract_first()
item = RedisproItem()
item['img_url'] = img_url
# 使用分布式的管道
yield item
====items===========
import scrapy
class RedisproItem(scrapy.Item):
img_url = scrapy.Field()
====settings==========
# -*- coding: utf-8 -*-
BOT_NAME = 'redisPro'
SPIDER_MODULES = ['redisPro.spiders']
NEWSPIDER_MODULE = 'redisPro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停,如果某台机器宕机,从宕机地方继续爬取
SCHEDULER_PERSIST = True
#如果redis服务器不在本机,需要进行如下配置
REDIS_HOST = '192.168.0.100' #本机的IP
REDIS_PORT = 6379
=====pipelines========默认
class RedisproPipeline(object):
def process_item(self, item, spider):
return item
十七、scrapy框架--分布式爬虫RedisSpider
先写Spider的代码,再修改为RedisSpider
基于RedisSpider实现的分布式爬虫(网易新闻)
a)代码修改(爬虫类)
1.导包:from scrapy_redis.spiders import RedisSpider
2.将爬虫类的父类修改为RedisSpider
3.注释掉start_url,添加一个redis_key属性(调度器队列名称)
b)修改redis数据库配置文件redis.conf
1.#bind 127.0.0.1
2.protected-mode no
c)项目中settings.py进行配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停,如果某台机器宕机,从宕机地方继续爬取
SCHEDULER_PERSIST = True
#如果redis服务器不在本机,需要进行如下配置
REDIS_HOST = '192.168.0.100' #本机的IP
REDIS_PORT = 6379
REDIS_PARAMS = {'password':'123456'}
d)启动redis服务端:
命令:redis-server 配置文件
e)执行爬虫文件:
进入到爬虫文件所在目录执行命令:scrapy runspider wangyi.py
f)向调度器的管道中扔一个起始url:
1.开启redis客户端
2.lpush wangyi https://news.163.com
十七、scrapy框架--selenium如何应用
selenium在scrapy中使用的原理分析:
- 用selenium在中间件中拦截下载器提交给引擎的response对象
- 对其进行篡改,用selenium发请求,将具有动态数据的响应对象替换原响应对象。
selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
-爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
start_urls = ['https://news.163.com/']
def __init__(self):
#实例化浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path=r'C:UsersAdministratorDownloadschromedriver.exe')
def closed(self, spider):
#必须在整个爬虫结束后,关闭浏览器
self.bro.quit()
-中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
-配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
十八、scrapy框架--UA池、代理池
原理:
- 使用下载中间件处理请求,对请求设置随机的User-Agent 或者设置随机的代理。
- 目的在于防止爬取网站的反爬虫策略。
操作流程:
- 在下载中间件中拦截请求
- 将拦截到的请求的请求头信息中的UA进行篡改伪装 或者 将拦截到的请求的IP修改成某一代理IP
- 在配置文件中开启下载中间件
代码展示UA池:
#导包
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
#UA池代码的编写(单独给UA池封装一个下载中间件的一个类)
class RandomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
#从列表中随机抽选出一个ua值
ua = random.choice(user_agent_list)
#ua值进行当前拦截到请求的ua的写入操作
request.headers.setdefault('User-Agent',ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
代码展示代理池:
#批量对拦截到的请求进行ip更换
#单独封装下载中间件类
class Proxy(object):
def process_request(self, request, spider):
#对拦截到请求的url进行判断(协议头到底是http还是https)
#request.url返回值:http://www.xxx.com
h = request.url.split(':')[0] #请求的协议头
if h == 'https':
ip = random.choice(PROXY_https)
request.meta['proxy'] = 'https://'+ip
else:
ip = random.choice(PROXY_http)
request.meta['proxy'] = 'http://' + ip
#可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
十九、scrapy框架--综合应用(爬网易新闻)
需求:
- 爬取网易新闻https://news.163.com/基于文字的新闻数据(“国内”、”国际“、”军事“、”航空“四个板块)
用到的知识点:
- 请求的手动发送
- 请求传参
- xpath解析
- UA池,代理池
- selenium在scrapy中的应用
代码展示
--爬虫类:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItem
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
start_urls = ['https://news.163.com/']
def __init__(self):
#实例化浏览器对象
self.bro = webdriver.Chrome(executable_path=r'C:UsersAdministratorDownloadschromedriver.exe')
def closed(self, spider):
self.bro.quit()
def parse(self, response):
#获取四个板块的a标签href属性
lis = response.xpath('//div[@class="ns_area list"]/ul/li')
indexs = [3,4,6,7]
li_list = [] #存储的四个板块的li标签对象
for index in indexs:
li_list.append(lis[index])
#获取四个板块中的超链接和文字标题
for li in li_list:
url = li.xpath('./a/@href').extract_first()
title = li.xpath('./a/text()').extract_first()
#对每一个板块的url发请求,获取页面数据(标题,缩略图,关键字,发布时间,url)
yield scrapy.Request(url=url, callback=self.parse_second, meta={'title': title})
def parse_second(self, response):
#这个div_list长度为0,xpath表达式没有问题,是动态加载的数据发送的请求拿不到。
#所以要用selenium去拿数据
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
#文章标题
head = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
#文章超链接
url = div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first()
#缩略图
img_url = div.xpath('./a/img/@src').extract_first()
#关键字
tag_list = div.xpath('.//div[@class="news_tag"]//text()').extract()
tags = "".join([tag.strip() for tag in tag_list])
item = WangyiproItem()
title = response.meta['title']
item['head'] = head
item['url'] = url
item['img_url'] = img_url
item['tag'] = tags
item['title'] = title
# 对url发请求,获取页面中存储的新闻内容
yield scrapy.Request(url=url, callback=self.get_content, meta={'item': item})
def get_content(self, response):
#获取请求传参的item
item = response.meta['item']
#解析出新闻内容
content_list = response.xpath('//div[@class="post_text"]/p/text()').extract()
content = "".join(content_list)
item['content'] = content
yield item
--items:
import scrapy
class WangyiproItem(scrapy.Item):
head = scrapy.Field()
url = scrapy.Field()
img_url = scrapy.Field()
tag = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
--管道:
class WangyiproPipeline(object):
def process_item(self, item, spider):
print("title:"+item['title']+"|content:"+item['content'])
return item
--中间件:
# -*- coding: utf-8 -*-
from scrapy import signals
import time
from scrapy.http import HtmlResponse
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
#单独给UA池封装一个下载中间件的类
class RandomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua = random.choice(user_agent_list)
request.headers.setdefault('User-Agent',ua)
#单独给代理池封装一个下载中间件的类
class Proxy(object):
def process_request(self, request, spider):
#判断协议头是http还是https的
h = request.url.split(':')[0]
if h=='https':
ip = random.choice(proxies_https)
request.meta['proxy'] = "https://"+ip
else:
ip = random.choice(proxies_http)
request.meta['proxy'] = "http://" + ip
class WangyiproDownloaderMiddleware(object):
def process_request(self, request, spider):
return None
#拦截响应:拦截下载器传给spider的响应对象
#request:响应对象所对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类实例
def process_response(self, request, response, spider):
#需要篡改response,使其包括动态加载的新闻内容
if request.url in ['http://news.163.com/domestic/','http://news.163.com/world/',
'http://war.163.com/','http://news.163.com/air/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0, document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(1)
page_text = spider.bro.page_source
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request)
else:
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
proxies_http=[
'173.82.219.113:3128',
'92.243.6.37:80',
]
proxies_https=[
'117.102.96.59:8080',
'213.234.28.94:8080',
'101.51.123.88:8080',
'158.58.131.214:41258',
]
--settings:
# -*- coding: utf-8 -*-
BOT_NAME = 'wangyiPro'
SPIDER_MODULES = ['wangyiPro.spiders']
NEWSPIDER_MODULE = 'wangyiPro.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.Proxy': 542, #代理池
'wangyiPro.middlewares.RandomUserAgent': 542, #UA池
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543, #selenium拦截
}
二十、scrapy框架--总结
1.接触过几种爬虫模块
- urllib
- requests
2.robots协议是什么
- requests模块没有使用硬性的语法对该协议进行生效
3.如何处理验证码
- 云打码平台
- 打码兔
4.掌握几种数据解析的方式
- 正则
- xpath
- bs4
5.如何爬取动态加载的页面数据
- selenium
- ajax请求
6.接触过哪些反爬机制?如何处理?
- robots协议
- UA
- 封IP
- 验证码
- 动态数据爬取
- 数据加密(挨着试解密方法)
- token(前台页面中查找)
7.在scrapy中接触过几种爬虫的类
- Spider
- CrawlSpider
- RedisCrawlSpider
- RedisSpider
8.如何实现分布式流程
- pip3 install scrapy-redis
- RedisCrawlSpider
- RedisSpider