问题一:一个文件含有5亿行,每行是一个随机整数,需要对该文件所有整数排序。
分治(Divide&Conquer),参考大数据算法:对5亿数据进行排序
对这个一个500000000行的 total.txt 进行排序,该文件大小 4.6G。
每读10000行就排序并写入到一个新的子文件里(这里使用的是快速排序)。
1.分割 & 排序
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('
'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)
会生成 50000 个小文件,每个小文件大小约在 96K左右。
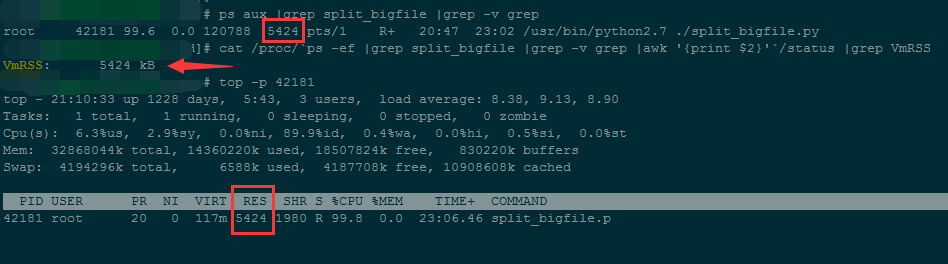
程序在执行过程中,内存占用一直处在 5424kB 左右
整个文件分割完耗时 94146 秒。
2.合并
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('
'.join([ str(i) for i in nums ]) + '
')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now))
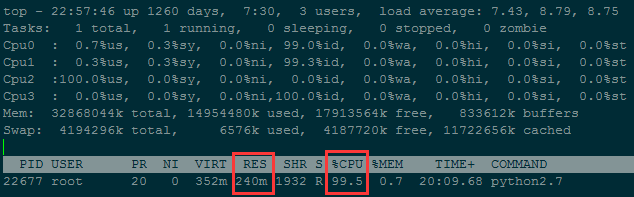
程序在执行过程中,内存占用一直处在 240M左右

跑了38个小时左右,才合并完不到5千万行数据...
虽然降低了内存使用,但时间复杂度太高了;可以通过减少文件数(每个小文件存储行数增加)来进一步降低内存使用。
问题二:一个文件有一千亿行数据,每行是一个IP地址,需要对IP地址进行排序。
IP地址转换成数字
# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'
x03Qx96'
In [73]: struct.unpack("!I", socket.inet_aton(ip)) # !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:
问题三:有一个1.3GB的文件(共一亿行),里面每一行都是一个字符串,请在文件中找出重复次数最多的字符串。
基本思想:迭代读大文件,把大文件拆分成多个小文件;最后再归并这些小文件。
拆分的规则:
迭代读大文件,内存中维护一个字典,key是字符串,value是该字符串出现的次数;
当字典维护的字符串种类达到10000(可自定义)的时候,把该字典按照key从小到大排序,然后写入小文件,每行是 key value;
然后清空字典,继续往下读,直到大文件读完。
归并的规则:
首先获取全部小文件的文件描述符,然后各自读出第一行(即每个小文件字符串ascii值最小的字符串),进行比较。
找出ascii值最小的字符串,如果有重复的,这把各自出现的次数累加起来,然后把当前字符串和总次数存储到内存中的一个列表。
然后把最小字符串所在的文件的读指针向下移,即从对应小文件里再读出一行进行下一轮比较。
当内存中的列表个数达到10000时,则一次性把该列表内容写到一个最终文件里存储到硬盘上。同时清空列表,进行之后的比较。
一直到读完全部的小文件,那么最后得到的最终文件就是一个按照字符串ascii值升序排序的大的文件,每一行的内容就是 字符串 重复次数,
最后迭代去读这个最终文件,找出重复次数最多的即可。
1. 分割
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def split_bfile(bfile):
count = 0
d = {}
for line in readline_by_yield(bfile):
line = line.strip()
if line not in d:
d[line] = 0
d[line] += 1
if 10000 == len(d):
text = ''
for string in sorted(d):
text += '{} {}
'.format(string,d[string])
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write(text.strip())
d.clear()
count += 1
text = ''
for string in sorted(d):
text += '{} {}
'.format(string,d[string])
with open('subfile/subfile_end.txt','w') as wf:
wf.write(text.strip())
split_bfile('bigfile.txt')
2. 归并
import os
import json
import time
import traceback
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行
tmp_strings = []
tmp_count = []
for fd in fds:
line = fd.readline()
string,count = line.strip().split(' ')
tmp_strings.append(string)
tmp_count.append(int(count))
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
result = []
need2del = []
while True:
min_str = min(tmp_strings)
str_idx = [i for i,v in enumerate(tmp_strings) if v==min_str]
str_count = sum([ int(tmp_count[idx]) for idx in str_idx ])
result.append('{} {}
'.format(min_str,str_count))
for idx in str_idx:
next = fds[idx].readline() # IndexError: list index out of range
# 文件读完了
if not next:
need2del.append(idx)
else:
next_string,next_count = next.strip().split(' ')
tmp_strings[idx] = next_string
tmp_count[idx] = next_count
# 暂存区保存10000个记录,一次性写入硬盘,然后清空继续读。
if 10000 == len(result):
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []
# 注意: 文件读完需要删除文件描述符的时候, 需要逆序删除
need2del.reverse()
for idx in need2del:
del fds[idx]
del tmp_strings[idx]
del tmp_count[idx]
need2del[:] = []
if 0 == len(fds):
break
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []
归并结果分析:
| 分割时内存中维护的字典大小 | 分割的小文件个数 | 归并时需维护的文件描述符个数 | 归并时内存占用 | 归并耗时 | |
| 第一次 | 10000 | 9000 | 9000 ~ 0 | 200M | 归并速度慢,暂未统计完成时间 |
| 第二次 | 100000 | 900 | 900 ~ 0 | 27M | 归并速度快,只需2572秒 |
3. 查找出现次数最多的字符串及其次数
import time
def read_line(filepath):
with open(filepath,'r') as rf:
for line in rf:
yield line
start_ts = time.time()
max_str = None
max_count = 0
for line in read_line('merged.txt'):
string,count = line.strip().split(' ')
if int(count) > max_count:
max_count = int(count)
max_str = string
print(max_str,max_count)
print('Runtime {}'.format(time.time()-start_ts))
归并后的文件共9999788行,大小是256M;执行查找耗时27秒,内存占用6480KB。