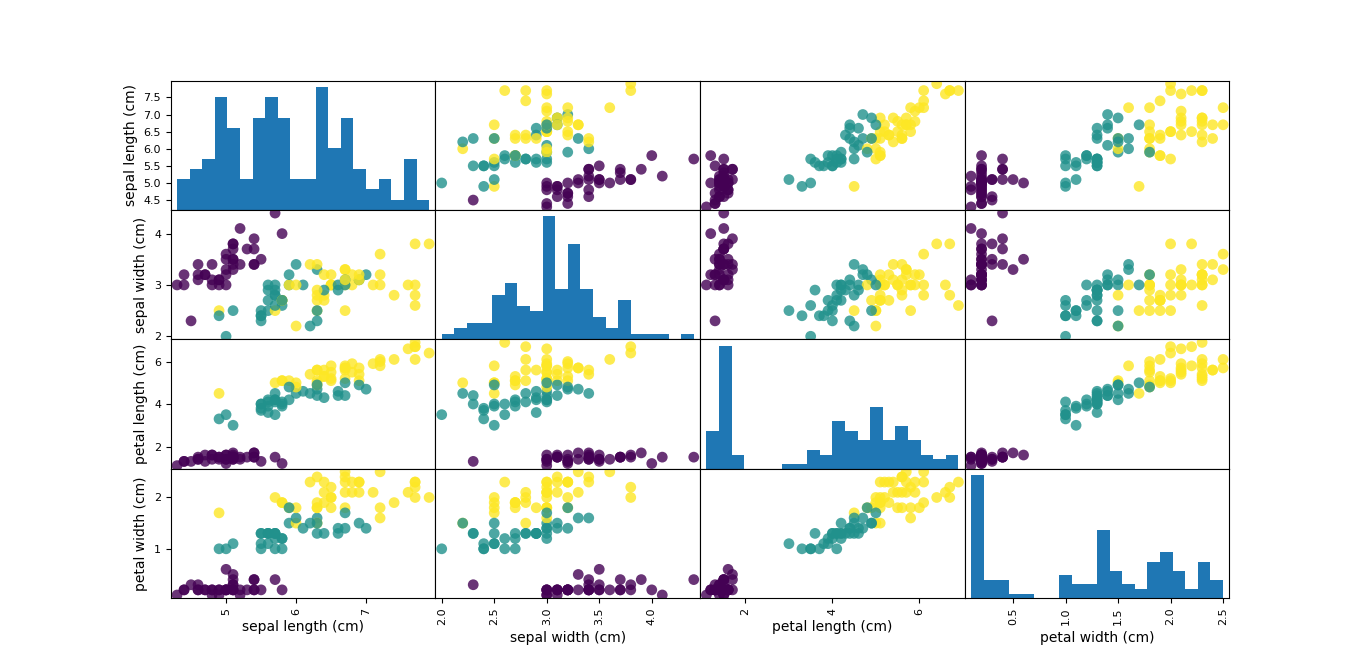
以 sklearn的iris样本为数据集
import matplotlib.pyplot as plt from scipy import sparse import numpy as np import matplotlib as mt import pandas as pd from IPython.display import display from sklearn.datasets import load_iris import sklearn as sk from sklearn.model_selection import train_test_split iris=load_iris() #print(iris) X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0) iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names) grr = pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=.8) plt.show()