Cassandra 提供了三种集合类型,分别是Set,List,Map
Set: 非重复集,存储了一组类型相同的不重复元素,当被查询时会返回排好序的结果,但是内部构成是无序的值,应该是在查询时对结果进行了排序。
List: 列表,查询时会按照元素在list中的index顺序来返回结果,可以存储多个重复的值。
Map:哈希Key-Value键值对,提供了名字到值的映射
-- 开始工作: bin/cqlsh localhost -- 查看所有的键空间: DESCRIBE keyspaces -- 使用创建的键空间: USE myks; -- 查看已有表: describe tables; -- 查看表结构: describe table user_status_updates;
Set
-- 修改表结构,增加一个列,用于存储评星用户记录 ALTER TABLE "user_status_updates" ADD "starred_by_users" text; -- 查询出一个空记录 SELECT "starred_by_users" FROM "user_status_updates" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 修改记录,增加评星用户 UPDATE "user_status_updates" SET "starred_by_users" = '["bob"]' WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 事实上,可以直接定义列的类型为集合列,而不是定义为Text类型 ALTER TABLE "user_status_updates" DROP "starred_by_users"; -- 注意一下:SET<text>类型 ALTER TABLE "user_status_updates" ADD "starred_by_userss" SET<text>; -- 修改记录方法1,增加评星用户,这次是集合,使用{}来存储多条数据 UPDATE "user_status_updates" SET "starred_by_userss" = {'bob'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 修改记录方法2,用+ UPDATE "user_status_updates" SET "starred_by_userss" = "starred_by_userss" + {'carol'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "starred_by_userss" = "starred_by_userss" + {'dave'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 修改记录方法2,用- UPDATE "user_status_updates" SET "starred_by_userss" = "starred_by_users" - {'dave'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "starred_by_userss" = "starred_by_userss" + {'carol'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 多加几个为了测试排序 UPDATE "user_status_updates" SET "starred_by_userss" = "starred_by_userss" + {'alice'} WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; SELECT "starred_by_userss" FROM "user_status_updates" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02;
查询结果发现,是经过了排序:
starred_by_userss
-----------------------------------
{'alice', 'bob', 'carol', 'dave'}
集合列表List
和上面的差不多,区别是允许重复,并且没有排序。
ALTER TABLE "user_status_updates" ADD "shared_by" LIST<text>; UPDATE "user_status_updates" SET "shared_by" = ['bob'] WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by" = "shared_by" + ['carol'] WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by" = ['dave'] + "shared_by" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by"[1] = 'robert' WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by"[3] = 'maurice' WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by" = "shared_by" - ['carol'] WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; --删除记录的方法是按照index顺序下标进行删除 DELETE "shared_by"[0] FROM "user_status_updates" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; UPDATE "user_status_updates" SET "shared_by" = "shared_by" + ['arol'] WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 查询 SELECT "shared_by" FROM "user_status_updates" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02;
查询结果发现,没有排序:
shared_by
----------------------------
['dave', 'robert', 'arol']
Map
存储键值对,键是唯一和无序的。
ALTER TABLE "users" ADD social_identities MAP<text,bigint>; UPDATE "users" SET "social_identities" = {'twitter': 353637} WHERE "username" = 'alice'; UPDATE "users" SET "social_identities"['instagram'] = 9839025, "social_identities"['yo'] = 25 WHERE "username" = 'alice'; UPDATE "users" SET "social_identities"['twitter'] = 2725634 WHERE "username" = 'alice'; DELETE "social_identities"['instagram'] FROM "users" WHERE "username" = 'alice'; INSERT INTO "users" ( "username", "email", "encrypted_password", "social_identities", "version" ) VALUES ( 'ivan', 'ivan@gmail.com', 0x48acb738ece5780f37b626a0cb64928b, {'twitter': 875958, 'instagram': 109550}, NOW() );
使用TTL
UPDATE users USING TTL <computed_ttl> SET todo['2012-10-1'] = 'find water' WHERE user_id = 'frodo'; INSERT INTO users (user_name, password) VALUES ('cbrown', 'ch@ngem4a') USING TTL 86400;
在设定的computed_ttl数值秒后,数据会自动删除。
使用集合类型要注意:
1.集合的每一项最大是64K。
2.保持集合内的数据不要太大,免得Cassandra 查询延时过长,只因Cassandra 查询时会读出整个集合内的数据,集合在内部不会进行分页,集合的目的是存储小量数据。
3.不要向集合插入大于64K的数据,否则只有查询到前64K数据,其它部分会丢失。
正确的查询姿势
如果查询条件where跟随集合列的时候会报错,是因为没有建立索引
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
-- 正确的查询姿势,先创建索引 CREATE INDEX ON "user_status_updates" ("starred_by_userss"); SELECT * FROM "user_status_updates" WHERE "starred_by_userss" CONTAINS 'alice'; -- map类型也是 CREATE INDEX ON "users" (KEYS("social_identities")); SELECT "username", "social_identities" FROM users WHERE "social_identities" CONTAINS KEY 'twitter'; SELECT "shared_by"[2] FROM "user_status_updates" WHERE "username" = 'alice' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; SELECT "social_identities"['twitter'] FROM "users" WHERE "username" = 'alice'; SELECT * FROM "user_status_updates" WHERE "username" = 'alice' ORDER BY "id" ASC LIMIT 2; DROP INDEX user_social_identities_idx; ALTER TABLE "users" DROP social_identities; ALTER TABLE "users" ADD social_identities set<text>;
元组和自定义类型
-- 元组
ALTER TABLE "users" ADD "education" frozen <tuple<text, int>>; ALTER TABLE "users" DROP "education"; ALTER TABLE "users" ADD "education" tuple<text, int>; UPDATE "users" SET "education" = ('Big Data University', 2019) WHERE "username" = 'alice'; UPDATE "users" SET "education" = ('Cassandra College', null, null) WHERE "username" = 'bob'; UPDATE "users" SET "education" = ('BDU') WHERE "username" = 'alice'; UPDATE "users" SET "education" = ('Big Data University', 2003) WHERE "username" = 'alice'; CREATE INDEX ON "users" ("education"); SELECT "username", "education" FROM users; SELECT "username", "education" FROM users WHERE "education" = ('Big Data University', 2003); -- 自定义类型 CREATE TYPE "education_information" ( "school_name" text, "graduation_year" int ); ALTER TABLE "users" DROP "education"; ALTER TABLE "users" ADD "education" frozen <"education_information">; UPDATE "users" SET "education" = { "school_name": 'Big Data University', "graduation_year": 2003 } WHERE "username" = 'alice'; CREATE INDEX ON "users" ("education"); SELECT "username", "education" FROM "users" WHERE "education" = { "school_name": 'Big Data University', "graduation_year": 2003 }; SELECT "username", "education"."school_name" FROM "users" WHERE "username" = 'alice'; ALTER TABLE "users" ADD "telephone_numbers" map<text, set<text>>; ALTER TABLE "users" ADD "telephone_numbers" map<text, frozen<set<text>>>; UPDATE "users" SET "telephone_numbers"['home'] = {'123456789', '123789456'} WHERE "username" = 'alice'; UPDATE "users" SET "telephone_numbers"['office'] = {'123654789', '123987456'} WHERE "username" = 'alice'; ALTER TABLE "users" ADD "education_history" set<frozen<"education_information">>; UPDATE "users" SET "education_history" = {{ "school_name": 'Big Data University', "graduation_year": 2003 },{ "school_name": 'Cassandra College', "graduation_year": 2005 }} WHERE "username" = 'alice';
时间序列数据库
目前业界时间序列数据库可以分成两类,基于现有的数据库或者专门为时间序列数据写的数据库。
有很多时间序列数据库是基于 Cassandra 的, KairosDB 是其中比较早的一个。 InfluxDB 是专用于时间序列的数据库。
另外还有十几种时间序列数据库,都是基于Cassandra,见https://xephonhq.github.io/awesome-time-series-database/?language=All&backend=Cassandra
一个简单的时间序列数据结构
CREATE TABLE IF NOT EXISTS naive.metrics ( metric_name text, metric_timestamp timestamp, value int, PRIMARY KEY (metric_name, metric_timestamp)) INSERT INTO naive.metrics (metric_name, metric_timestamp, value) VALUES (cpu, 2017/03/17:13:24:00:20, 10.2) INSERT INTO naive.metrics (metric_name, metric_timestamp, value) VALUES (mem, 2017/03/17:13:24:00:20, 80.3)
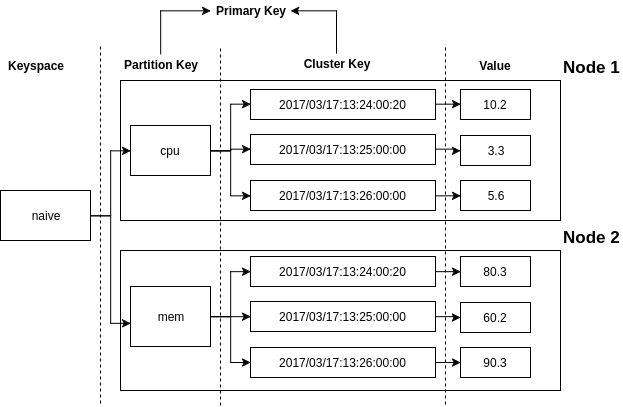
上图显示了使用 Cassandra 存储时间序列数据时 naive 的表结构, Cluster Key 存储时间戳,列的值存储实际的数值。 它 naive 之处在于序列和 Cassandra 的物理行是一一对应的。 当单一序列的数据点超过 Cassandra 的限制(20亿)时就会崩溃。
一个更加成熟的表结构是把一个时间序列按时间范围分区,(KairosDB 按照 3 周来划分,但是可以根据数据量进行不定长的划分)。 为了存储分区的信息,需要一张额外的表。 同时在 naive 里序列的名称只是一个简单的字符串,如果需要按照多种条件进行筛选的话,需要存储更多的键值对,并且对于这些键值对需要建立索引以提高查询速度。
更复杂的例子:
一个双分区列的例子,("status_update_username", "status_update_id")是联合分区列,observed_at是簇分区列,也是时间序列,类型为timeuuid
CREATE TABLE "status_update_views" ( "status_update_username" text, "status_update_id" timeuuid, "observed_at" timeuuid, "client_type" text, PRIMARY KEY ( ("status_update_username", "status_update_id"), "observed_at" ) ); -- 插入数据 INSERT INTO "status_update_views" ( "status_update_username", "status_update_id", "observed_at", "client_type" ) VALUES ( 'alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, 85a53d10-4cc3-11e4-a7ff-5f98e903bf02, 'web' ); -- 查询 SELECT "observed_at", "client_type" FROM "status_update_views" WHERE "status_update_username" = 'alice' AND "status_update_id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02 AND "observed_at" >= MINTIMEUUID('2014-10-05 00:00:00+0000') AND "observed_at" < MINTIMEUUID('2014-10-06 00:00:00+0000'); -- 查询计数 SELECT COUNT(1) FROM "status_update_views" WHERE "status_update_username" = 'alice' AND "status_update_id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02 AND "observed_at" >= MINTIMEUUID('2014-10-05 00:00:00+0000') AND "observed_at" < MINTIMEUUID('2014-10-06 00:00:00+0000');
计数表counter
有一些计数类型的应用,比如某个页面被点击了多少次,或9月的每一天,状态更新了多少次。一般地说,我们希望将每日总体视图计数存储在一个结构中,该结构允许我们在给定的时间范围内轻松检索计数。我们不需要存储关于每个视图事件的离散信息;只需知道每天发生了多少视图就足够了。Cassandra非常擅长做这个。
我个人认为这种高性能、低存储空间的计数应用交给Redis会更好,Cassandra有比较多的局限(http://rockthecode.io/blog/highly-available-counters-using-cassandra/),Cassandra还是做它擅长的列存储、时间序列就好了。
-- 注意,counter类型 -- year是分区列,date为簇列 CREATE TABLE "daily_status_update_views" ( "year" int, "date" timestamp, "total_views" counter, "web_views" counter, "mobile_views" counter, "api_views" counter, PRIMARY KEY (("year"), "date") ); SELECT "date", "total_views" FROM "daily_status_update_views" WHERE "year" = 2014 AND "date" >= '2014-09-01' AND "date" < '2014-09-30'; UPDATE "daily_status_update_views" SET "total_views" = "total_views" + 1, "web_views" = "web_views" + 1 WHERE "year" = 2014 AND "date" = '2014-10-05 00:00:00+0000'; SELECT * FROM "daily_status_update_views"; -- 在尝试添加的时候会报错,原因是counter表只允许update,不准insert -- InvalidRequest: Error from server: code=2200 [Invalid query] message="INSERT statements are not allowed on counter tables, use UPDATE instead" INSERT INTO "daily_status_update_views" ("year", "date", "total_views") VALUES (2014, '2014-02-01 00:00:00+0000', 500); -- 正确的姿势 UPDATE "daily_status_update_views" SET "total_views" = "total_views" + 500 WHERE "year" = 2014 AND "date" = '2014-02-01 00:00:00+0000'; DELETE FROM "daily_status_update_views" WHERE "year" = 2014 AND "date" = '2014-02-01 00:00:00+0000'; UPDATE "daily_status_update_views" SET "total_views" = "total_views" + 100 WHERE "year" = 2014 AND "date" = '2014-02-01 00:00:00+0000'; -- 在尝试修改表定义的时候会报错,只能增加counter类型的列 -- ConfigurationException: Cannot add a non counter column (last_view_time) in a counter column family ALTER TABLE "daily_status_update_views" ADD "last_view_time" timestamp;
用户定义函数
比较简单,不多说了。感觉应用的地方不多。
CREATE OR REPLACE FUNCTION selectCity(location text) CALLED ON NULL INPUT RETURNS text LANGUAGE java AS ' if (location == null) return null; else return location.split(",")[0]; '; SELECT username, selectCity(location) FROM "users"; CREATE OR REPLACE FUNCTION selectCity(location text) RETURNS NULL ON NULL INPUT RETURNS text LANGUAGE java AS ' return location.split(",")[0]; '; INSERT INTO "status_update_views" ("status_update_username", "status_update_id", "observed_at", "client_type") VALUES ('alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, NOW(), 'web'); INSERT INTO "status_update_views" ("status_update_username", "status_update_id", "observed_at", "client_type") VALUES ('alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, NOW(), 'web'); INSERT INTO "status_update_views" ("status_update_username", "status_update_id", "observed_at", "client_type") VALUES ('alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, NOW(), 'mobile'); INSERT INTO "status_update_views" ("status_update_username", "status_update_id", "observed_at", "client_type") VALUES ('alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, NOW(), 'mobile'); INSERT INTO "status_update_views" ("status_update_username", "status_update_id", "observed_at", "client_type") VALUES ('alice', 76e7a4d0-e796-11e3-90ce-5f98e903bf02, NOW(), 'api'); CREATE OR REPLACE FUNCTION state_group_and_count (state map<text, int>, client_type text) CALLED ON NULL INPUT RETURNS map<text, int> LANGUAGE java AS ' Integer count = (Integer) state.get(client_type); if (count == null) count = 1; else count++; state.put(client_type, count); return state; '; CREATE OR REPLACE AGGREGATE group_and_count (text) SFUNC state_group_and_count STYPE map<text, int> INITCOND {}; SELECT status_update_username, status_update_id, group_and_count(client_type) FROM status_update_views WHERE status_update_username='alice' AND status_update_id=76e7a4d0-e796-11e3-90ce-5f98e903bf02; SELECT status_update_username, status_update_id, group_and_count(client_type) FROM status_update_views WHERE status_update_username='alice' AND status_update_id=76e7a4d0-e796-11e3-90ce-5f98e903bf02 AND "observed_at" >= MINTIMEUUID('2016-12-21 00:00:00+0000') AND "observed_at" < MINTIMEUUID('2016-12-22 00:00:00+0000');