相关度评分背后的理论
Lucene(或 Elasticsearch)使用 布尔模型(Boolean model) 查找匹配文档,并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
不要紧张!这些概念并没有像它们字面看起来那么复杂,尽管本小节提到了算法、公式和数学模型,但内容还是让人容易理解的,与理解算法本身相比,了解这些因素如何影响结果更为重要。
布尔模型
布尔模型(Boolean Model) 只是在查询中使用 AND 、 OR 和 NOT (与、或和非)这样的条件来查找匹配的文档,以下查询:
full AND text AND search AND (elasticsearch OR lucene)
会将所有包括词 full 、 text 和 search ,以及 elasticsearch 或 lucene 的文档作为结果集。
这个过程简单且快速,它将所有可能不匹配的文档排除在外。
词频/逆向文档频率(TF/IDF)
当匹配到一组文档后,需要根据相关度排序这些文档,不是所有的文档都包含所有词,有些词比其他的词更重要。一个文档的相关度评分部分取决于每个查询词在文档中的 权重 。
词的权重由三个因素决定,在 什么是相关 中已经有所介绍,有兴趣可以了解下面的公式,但并不要求记住。
词频
词在文档中出现的频度是多少?频度越高,权重 越高 。 5 次提到同一词的字段比只提到 1 次的更相关。词频的计算方式如下:
tf(t in d) = √frequency
词 t 在文档 d 的词频( tf )是该词在文档中出现次数的平方根。
如果不在意词在某个字段中出现的频次,而只在意是否出现过,则可以在字段映射中禁用词频统计:
PUT /my_index { "mappings": { "doc": { "properties": { "text": { "type": "string", "index_options": "docs" } } } } }
将参数 index_options 设置为 docs 可以禁用词频统计及词频位置,这个映射的字段不会计算词的出现次数,对于短语或近似查询也不可用。要求精确查询的 not_analyzed 字符串字段会默认使用该设置。
逆向文档频率
词在集合所有文档里出现的频率是多少?频次越高,权重 越低 。常用词如 and 或 the 对相关度贡献很少,因为它们在多数文档中都会出现,一些不常见词如 elastic 或 hippopotamus 可以帮助我们快速缩小范围找到感兴趣的文档。逆向文档频率的计算公式如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
字段长度归一值
字段的长度是多少?字段越短,字段的权重 越高 。如果词出现在类似标题 title 这样的字段,要比它出现在内容 body 这样的字段中的相关度更高。字段长度的归一值公式如下:
norm(d) = 1 / √numTerms
字段长度归一值( norm )是字段中词数平方根的倒数。
字段长度的归一值对全文搜索非常重要,许多其他字段不需要有归一值。无论文档是否包括这个字段,索引中每个文档的每个 string 字段都大约占用 1 个 byte 的空间。对于 not_analyzed 字符串字段的归一值默认是禁用的,而对于 analyzed 字段也可以通过修改字段映射禁用归一值:
PUT /my_index { "mappings": { "doc": { "properties": { "text": { "type": "string", "norms": { "enabled": false } } } } } }
这个字段不会将字段长度归一值考虑在内,长字段和短字段会以相同长度计算评分。
对于有些应用场景如日志,归一值不是很有用,要关心的只是字段是否包含特殊的错误码或者特定的浏览器唯一标识符。字段的长度对结果没有影响,禁用归一值可以节省大量内存空间。
结合使用
以下三个因素——词频(term frequency)、逆向文档频率(inverse document frequency)和字段长度归一值(field-length norm)——是在索引时计算并存储的。最后将它们结合在一起计算单个词在特定文档中的 权重 。
前面公式中提到的 文档 实际上是指文档里的某个字段,每个字段都有它自己的倒排索引,因此字段的 TF/IDF 值就是文档的 TF/IDF 值。
当用 explain 查看一个简单的 term 查询时(参见 explain ),可以发现与计算相关度评分的因子就是前面章节介绍的这些:
PUT /my_index/doc/1 { "text" : "quick brown fox" } GET /my_index/doc/_search?explain { "query": { "term": { "text": "fox" } } }
以上请求(简化)的 explanation 解释如下:
weight(text:fox in 0) [PerFieldSimilarity]: 0.15342641
result of:
fieldWeight in 0 0.15342641
product of:
tf(freq=1.0), with freq of 1: 1.0
idf(docFreq=1, maxDocs=1): 0.30685282
fieldNorm(doc=0): 0.5
- 词 fox 在文档的内部 Lucene doc ID 为 0 ,字段是 text 里的最终评分。
- 词 fox 在该文档 text 字段中只出现了一次。
- fox 在所有文档 text 字段索引的逆向文档频率。
- 该字段的字段长度归一值。
当然,查询通常不止一个词,所以需要一种合并多词权重的方式——向量空间模型(vector space model)。
向量空间模型
向量空间模型(vector space model) 提供一种比较多词查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors) 的形式表示:
向量实际上就是包含多个数的一维数组,例如:
[1,2,5,22,3,8]
在向量空间模型里,向量空间模型里的每个数字都代表一个词的 权重 ,与 词频/逆向文档频率(term frequency/inverse document frequency) 计算方式类似。
尽管 TF/IDF 是向量空间模型计算词权重的默认方式,但不是唯一方式。Elasticsearch 还有其他模型如 Okapi-BM25 。TF/IDF 是默认的因为它是个经检验过的简单又高效的算法,可以提供高质量的搜索结果。
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5) ,如图 Figure 27, “表示 “happy hippopotamus” 的二维查询向量” 。
查询向量绘点图
Figure 27. 表示 “happy hippopotamus” 的二维查询向量

现在,设想我们有三个文档:
- I am happy in summer 。
- After Christmas I’m a hippopotamus 。
- The happy hippopotamus helped Harry 。
可以为每个文档都创建包括每个查询词—— happy 和 hippopotamus ——权重的向量,然后将这些向量置入同一个坐标系中,如图 Figure 28, ““happy hippopotamus” 查询及文档向量” :
- 文档 1: (happy,____________) —— [2,0]
- 文档 2: ( ___ ,hippopotamus) —— [0,5]
- 文档 3: (happy,hippopotamus) —— [2,5]
查询及文档向量绘点图
Figure 28. “happy hippopotamus” 查询及文档向量
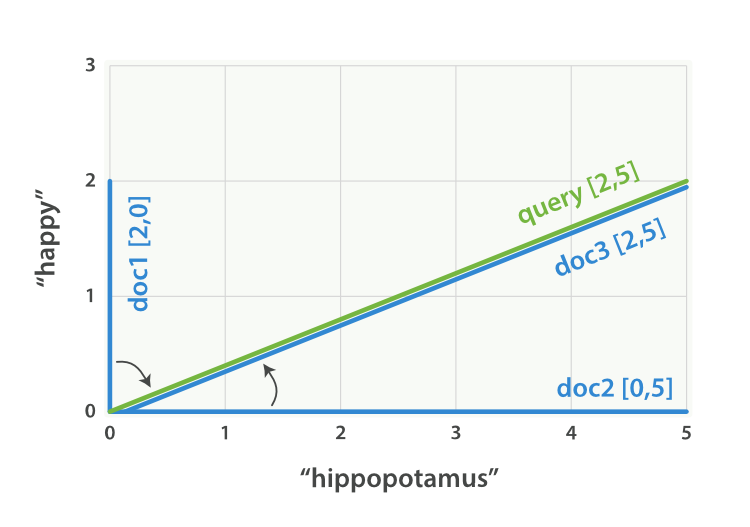
向量之间是可以比较的,只要测量查询向量和文档向量之间的角度就可以得到每个文档的相关度,文档 1 与查询之间的角度最大,所以相关度低;文档 2 与查询间的角度较小,所以更相关;文档 3 与查询的角度正好吻合,完全匹配。
在实际中,只有二维向量(两个词的查询)可以在平面上表示,幸运的是, 线性代数 ——作为数学中处理向量的一个分支——为我们提供了计算两个多维向量间角度工具,这意味着可以使用如上同样的方式来解释多个词的查询。
关于比较两个向量的更多信息可以参考 余弦近似度(cosine similarity)。
现在已经讲完评分计算的基本理论,我们可以继续了解 Lucene 是如何实现评分计算的。
权重提升
在 语句优先级(Prioritizing Clauses) 中,我们解释过如何在搜索时使用 boost 参数让一个查询语句比其他语句更重要。例如:
GET /_search { "query": { "bool": { "should": [ { "match": { "title": { "query": "quick brown fox", "boost": 2 } } }, { "match": { "content": "quick brown fox" } } ] } } }
title 查询语句的重要性是 content 查询的 2 倍,因为它的权重提升值为 2 。
没有设置 boost 的查询语句的值为 1 。
查询时的权重提升 是可以用来影响相关度的主要工具,任意类型的查询都能接受 boost 参数。将 boost 设置为 2 ,并不代表最终的评分 _score 是原值的两倍;实际的权重值会经过归一化和一些其他内部优化过程。尽管如此,它确实想要表明一个提升值为 2 的句子的重要性是提升值为 1 语句的两倍。
在实际应用中,无法通过简单的公式得出某个特定查询语句的 “正确” 权重提升值,只能通过不断尝试获得。需要记住的是 boost 只是影响相关度评分的其中一个因子;它还需要与其他因子相互竞争。在前例中, title 字段相对 content 字段可能已经有一个 “缺省的” 权重提升值,这因为在 字段长度归一值 中,标题往往比相关内容要短,所以不要想当然的去盲目提升一些字段的权重。选择权重,检查结果,如此反复。
改变嵌套结构修改相关度
Elasticsearch 的查询表达式相当灵活,可以通过调整查询结构中查询语句的所处层次,从而或多或少改变其重要性,比如,设想下面这个查询:
quick OR brown OR red OR fox
可以将所有词都放在 bool 查询的同一层中:
GET /_search { "query": { "bool": { "should": [ { "term": { "text": "quick" }}, { "term": { "text": "brown" }}, { "term": { "text": "red" }}, { "term": { "text": "fox" }} ] } } }
这个查询可能最终给包含 quick 、 red 和 brown 的文档评分与包含 quick 、 red 、 fox 文档的评分相同,这里 Red 和 brown 是同义词,可能只需要保留其中一个,而我们真正要表达的意思是想做以下查询:
quick OR (brown OR red) OR fox
根据标准的布尔逻辑,这与原始的查询是完全一样的,但是我们已经在 组合查询(Combining Queries) 中看到, bool 查询不关心文档匹配的 程度 ,只关心是否能匹配。
上述查询有个更好的方式:
GET /_search { "query": { "bool": { "should": [ { "term": { "text": "quick" }}, { "term": { "text": "fox" }}, { "bool": { "should": [ { "term": { "text": "brown" }}, { "term": { "text": "red" }} ] } } ] } } }
现在, red 和 brown 处于相互竞争的层次, quick 、 fox 以及 red OR brown 则是处于顶层且相互竞争的词。
Not Quite Not (不完全的NOT)
在互联网上搜索 “Apple”,返回的结果很可能是一个公司、水果和各种食谱。我们可以在 bool 查询中用 must_not 语句来排除像 pie 、 tart 、 crumble 和 tree 这样的词,从而将查询结果的范围缩小至只返回与 “Apple” (苹果)公司相关的结果:
GET /_search { "query": { "bool": { "must": { "match": { "text": "apple" } }, "must_not": { "match": { "text": "pie tart fruit crumble tree" } } } } }
但谁又敢保证在排除 tree 或 crumble 这种词后,不会错失一个与苹果公司特别相关的文档呢?有时, must_not 条件会过于严格。
权重提升查询
boosting 查询 恰恰能解决这个问题。它仍然允许我们将关于水果或甜点的结果包括到结果中,但是使它们降级——即降低它们原来可能应有的排名:
GET /_search { "query": { "boosting": { "positive": { "match": { "text": "apple" } }, "negative": { "match": { "text": "pie tart fruit crumble tree" } }, "negative_boost": 0.5 } } }
它接受 positive 和 negative 查询。只有那些匹配 positive 查询的文档罗列出来,对于那些同时还匹配 negative 查询的文档将通过文档的原始 _score 与 negative_boost 相乘的方式降级后的结果。
为了达到效果, negative_boost 的值必须小于 1.0 。在这个示例中,所有包含负向词的文档评分 _score 都会减半。
忽略 TF/IDF
有时候我们根本不关心 TF/IDF ,只想知道一个词是否在某个字段中出现过。可能搜索一个度假屋并希望它能尽可能有以下设施:
- WiFi
- Garden(花园)
- Pool(游泳池)
这个度假屋的文档如下:
{ "description": "A delightful four-bedroomed house with ... " }
可以用简单的 match 查询进行匹配:
GET /_search { "query": { "match": { "description": "wifi garden pool" } } }
但这并不是真正的 全文搜索 ,此种情况下,TF/IDF 并无用处。我们既不关心 wifi 是否为一个普通词,也不关心它在文档中出现是否频繁,关心的只是它是否曾出现过。实际上,我们希望根据房屋不同设施的数量对其排名——设施越多越好。如果设施出现,则记 1 分,不出现记 0 分。
constant_score 查询
在 constant_score 查询中,它可以包含查询或过滤,为任意一个匹配的文档指定评分 1 ,忽略 TF/IDF 信息:
GET /_search { "query": { "bool": { "should": [ { "constant_score": { "query": { "match": { "description": "wifi" }} }}, { "constant_score": { "query": { "match": { "description": "garden" }} }}, { "constant_score": { "query": { "match": { "description": "pool" }} }} ] } } }
或许不是所有的设施都同等重要——对某些用户来说有些设施更有价值。如果最重要的设施是游泳池,那我们可以为更重要的设施增加权重:
GET /_search { "query": { "bool": { "should": [ { "constant_score": { "query": { "match": { "description": "wifi" }} }}, { "constant_score": { "query": { "match": { "description": "garden" }} }}, { "constant_score": { "boost": 2 "query": { "match": { "description": "pool" }} }} ] } } }
pool 语句的权重提升值为 2 ,而其他的语句为 1 。
按受欢迎度提升权重
设想有个网站供用户发布博客并且可以让他们为自己喜欢的博客点赞,我们希望将更受欢迎的博客放在搜索结果列表中相对较上的位置,同时全文搜索的评分仍然作为相关度的主要排序依据,可以简单的通过存储每个博客的点赞数来实现它:
PUT /blogposts/_doc/1 { "title": "About popularity", "content": "In this post we will talk about...", "votes": 6 }
在搜索时,可以将 function_score 查询与 field_value_factor 结合使用,即将点赞数与全文相关度评分结合:
GET /blogposts/_search { "query": { "function_score": { "query": { "multi_match": { "query": "popularity", "fields": [ "title", "content" ] } }, "field_value_factor": { "field": "votes" } } } }
- function_score 查询将主查询和函数包括在内。
- 主查询优先执行。
- field_value_factor 函数会被应用到每个与主 query 匹配的文档。
- 每个文档的 votes 字段都 必须 有值供 function_score 计算。如果 没有 文档的 votes 字段有值,那么就 必须 使用 missing 属性 提供的默认值来进行评分计算。
在前面示例中,每个文档的最终评分 _score 都做了如下修改:
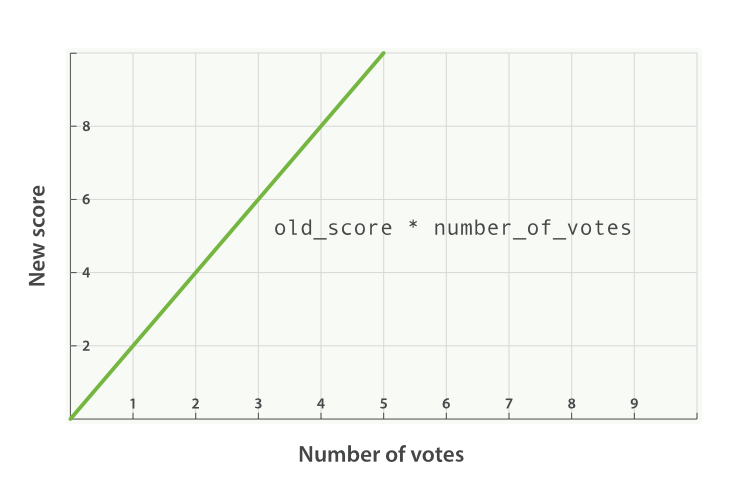
new_score = old_score * number_of_votes
然而这并不会带来出人意料的好结果,全文评分 _score 通常处于 0 到 10 之间,如下图 Figure 29, “受欢迎度的线性关系基于 _score 的原始值 2.0” 中,有 10 个赞的博客会掩盖掉全文评分,而 0 个赞的博客的评分会被置为 0 。
Linear popularity based on an original `_score` of `2.0`
Figure 29. 受欢迎度的线性关系基于 _score 的原始值 2.0
modifier
一种融入受欢迎度更好方式是用 modifier 平滑 votes 的值。换句话说,我们希望最开始的一些赞更重要,但是其重要性会随着数字的增加而降低。 0 个赞与 1 个赞的区别应该比 10 个赞与 11 个赞的区别大很多。
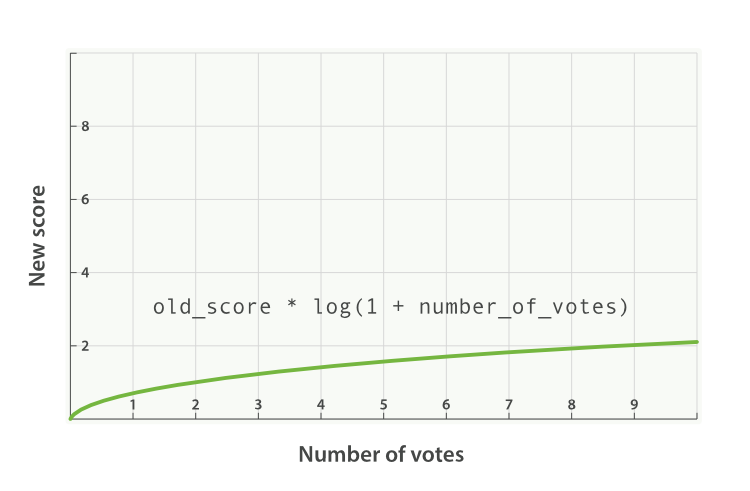
对于上述情况,典型的 modifier 应用是使用 log1p 参数值,公式如下:
new_score = old_score * log(1 + number_of_votes)
log 对数函数使 votes 赞字段的评分曲线更平滑,如图 Figure 30, “受欢迎度的对数关系基于 _score 的原始值 2.0” :
Logarithmic popularity based on an original `_score` of `2.0`
Figure 30. 受欢迎度的对数关系基于 _score 的原始值 2.0
带 modifier 参数的请求如下:
GET /blogposts/post/_search { "query": { "function_score": { "query": { "multi_match": { "query": "popularity", "fields": [ "title", "content" ] } }, "field_value_factor": { "field": "votes", "modifier": "log1p" } } } }
modifier 为 log1p 。
修饰语 modifier 的值可以为: none (默认状态)、 log 、 log1p 、 log2p 、 ln 、 ln1p 、 ln2p 、 square 、 sqrt 以及 reciprocal 。想要了解更多信息请参照: field_value_factor 文档.
factor
可以通过将 votes 字段与 factor 的积来调节受欢迎程度效果的高低:
GET /blogposts/post/_search { "query": { "function_score": { "query": { "multi_match": { "query": "popularity", "fields": [ "title", "content" ] } }, "field_value_factor": { "field": "votes", "modifier": "log1p", "factor": 2 } } } }
双倍效果。
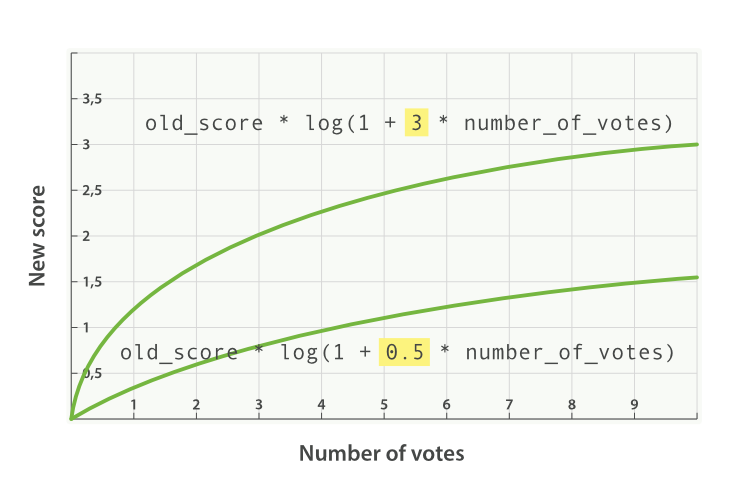
添加了 factor 会使公式变成这样:
new_score = old_score * log(1 + factor * number_of_votes)
factor 值大于 1 会提升效果, factor 值小于 1 会降低效果,
如图 Figure 31, “受欢迎度的对数关系基于多个不同因子” 。
boost_mode
或许将全文评分与 field_value_factor 函数值乘积的效果仍然可能太大,我们可以通过参数 boost_mode 来控制函数与查询评分 _score 合并后的结果,参数接受的值为:
- multiply
- 评分 _score 与函数值的积(默认)
- sum
- 评分 _score 与函数值的和
- min
- 评分 _score 与函数值间的较小值
- max
- 评分 _score 与函数值间的较大值
- replace
- 函数值替代评分 _score
与使用乘积的方式相比,使用评分 _score 与函数值求和的方式可以弱化最终效果,特别是使用一个较小 factor 因子时:
GET /blogposts/post/_search { "query": { "function_score": { "query": { "multi_match": { "query": "popularity", "fields": [ "title", "content" ] } }, "field_value_factor": { "field": "votes", "modifier": "log1p", "factor": 0.1 }, "boost_mode": "sum" } } }
将函数计算结果值累加到评分 _score 。
之前请求的公式现在变成下面这样(参见 Figure 32, “使用 sum 结合受欢迎程度” ):
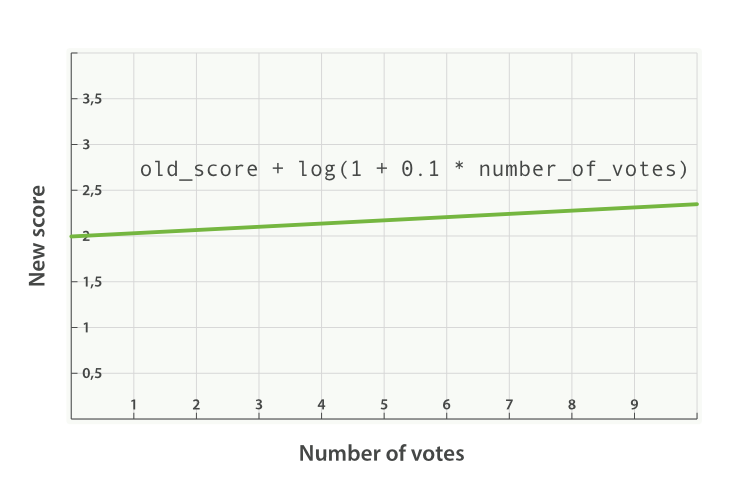
new_score = old_score + log(1 + 0.1 * number_of_votes)
max_boost
最后,可以使用 max_boost 参数限制一个函数的最大效果:
GET /blogposts/post/_search { "query": { "function_score": { "query": { "multi_match": { "query": "popularity", "fields": [ "title", "content" ] } }, "field_value_factor": { "field": "votes", "modifier": "log1p", "factor": 0.1 }, "boost_mode": "sum", "max_boost": 1.5 } } }
无论 field_value_factor 函数的结果如何,最终结果都不会大于 1.5 。
越近越好
很多变量都可以影响用户对于度假屋的选择,也许用户希望离市中心近点,但如果价格足够便宜,也有可能选择一个更远的住处,也有可能反过来是正确的:愿意为最好的位置付更多的价钱。
如果我们添加过滤器排除所有市中心方圆 1 千米以外的度假屋,或排除所有每晚价格超过 £100 英镑的,我们可能会将用户愿意考虑妥协的那些选择排除在外。
function_score 查询会提供一组 衰减函数(decay functions) ,让我们有能力在两个滑动标准,如地点和价格,之间权衡。
有三种衰减函数—— linear 、 exp 和 gauss (线性、指数和高斯函数),它们可以操作数值、时间以及经纬度地理坐标点这样的字段。所有三个函数都能接受以下参数:
- origin
- 中心点 或字段可能的最佳值,落在原点 origin 上的文档评分 _score 为满分 1.0 。
- scale
- 衰减率,即一个文档从原点 origin 下落时,评分 _score 改变的速度。(例如,每 £10 欧元或每 100 米)。
- decay
- 从原点 origin 衰减到 scale 所得的评分 _score ,默认值为 0.5 。
- offset
- 以原点 origin 为中心点,为其设置一个非零的偏移量 offset 覆盖一个范围,而不只是单个原点。在范围 -offset <= origin <= +offset 内的所有评分 _score 都是 1.0
- 这三个函数的唯一区别就是它们衰减曲线的形状.
用图来说明会更为直观(参见 Figure 33, “衰减函数曲线” )

图 Figure 33, “衰减函数曲线” 中所有曲线的原点 origin (即中心点)的值都是 40 , offset 是 5 ,也就是在范围 40 - 5 <= value <= 40 + 5 内的所有值都会被当作原点 origin 处理——所有这些点的评分都是满分 1.0 。
在此范围之外,评分开始衰减,衰减率由 scale 值(此例中的值为 5 )和 衰减值 decay (此例中为默认值 0.5 )共同决定。结果是所有三个曲线在 origin +/- (offset + scale) 处的评分都是 0.5 ,即点 30 和 50 处。
linear 、 exp 和 gauss (线性、指数和高斯)函数三者之间的区别在于范围( origin +/- (offset + scale) )之外的曲线形状:
- linear 线性函数是条直线,一旦直线与横轴 0 相交,所有其他值的评分都是 0.0 。
- exp 指数函数是先剧烈衰减然后变缓。
- gauss 高斯函数是钟形的——它的衰减速率是先缓慢,然后变快,最后又放缓。
选择曲线的依据完全由期望评分 _score 的衰减速率来决定,即距原点 origin 的值。
回到我们的例子:用户希望租一个离伦敦市中心近( { "lat": 51.50, "lon": 0.12} )且每晚不超过 £100 英镑的度假屋,而且与距离相比,我们的用户对价格更为敏感,这样查询可以写成:
GET /_search { "query": { "function_score": { "functions": [ { "gauss": { "location": { "origin": { "lat": 51.5, "lon": 0.12 }, "offset": "2km", "scale": "3km" } } }, { "gauss": { "price": { "origin": "50", "offset": "50", "scale": "20" } }, "weight": 2 } ] } } }
- location 字段以地理坐标点 geo_point 映射。
- price 字段是数值。
- origin 为什么是 50 而不是 100 。
- price 语句是 location 语句权重的两倍。
location 语句可以简单理解为:
- 以伦敦市中作为原点 origin 。
- 所有距原点 origin 2km 范围内的位置的评分是 1.0 。
- 距中心 5km ( offset + scale )的位置的评分是 0.5 。
price 语句使用了一个小技巧:用户希望选择 £100 英镑以下的度假屋,但是例子中的原点被设置成 £50 英镑,价格不能为负,但肯定是越低越好,所以 £0 到 £100 英镑内的所有价格都认为是比较好的。如果我们将原点 origin 被设置成 £100 英镑,那么低于 £100 英镑的度假屋的评分会变低,与其这样不如将原点 origin 和偏移量 offset 同时设置成 £50 英镑,这样就能使只有在价格高于 £100 英镑( origin + offset )时评分才会变低。
可插拔的相似度算法
在进一步讨论相关度和评分之前,我们会以一个更高级的话题结束本章节的内容:可插拔的相似度算法(Pluggable Similarity Algorithms)。 Elasticsearch 将 实用评分算法 作为默认相似度算法,它也能够支持其他的一些算法,这些算法可以参考 相似度模块 文档。
Okapi BM25算法
能与 TF/IDF 和向量空间模型媲美的就是 Okapi BM25 ,它被认为是 当今最先进的 排序函数。 BM25 源自 概率相关模型(probabilistic relevance model) ,而不是向量空间模型,但这个算法也和 Lucene 的实用评分函数有很多共通之处。
BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。与其详细解释 BM25 公式,倒不如将关注点放在 BM25 所能带来的实际好处上。
词频饱和度
TF/IDF 和 BM25 同样使用 逆向文档频率 来区分普通词(不重要)和非普通词(重要),同样认为(参见 词频 )文档里的某个词出现次数越频繁,文档与这个词就越相关。
不幸的是,普通词随处可见,实际上一个普通词在同一个文档中大量出现的作用会由于该词在 所有 文档中的大量出现而被抵消掉。
曾经有个时期,将 最 普通的词(或 停用词 ,参见 停用词)从索引中移除被认为是一种标准实践,TF/IDF 正是在这种背景下诞生的。TF/IDF 没有考虑词频上限的问题,因为高频停用词已经被移除了。
Elasticsearch 的 standard 标准分析器( string 字段默认使用)不会移除停用词,因为尽管这些词的重要性很低,但也不是毫无用处。这导致:在一个相当长的文档中,像 the 和 and 这样词出现的数量会高得离谱,以致它们的权重被人为放大。
另一方面,BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
这就是 非线性词频饱和度(nonlinear term-frequency saturation) 。
Figure 34. TF/IDF 与 BM25 的词频饱和度

字段长度归一化(Field-length normalization)
在 字段长归一化 中,我们提到过 Lucene 会认为较短字段比较长字段更重要:字段某个词的频度所带来的重要性会被这个字段长度抵消,但是实际的评分函数会将所有字段以同等方式对待。它认为所有较短的 title 字段比所有较长的 body 字段更重要。
BM25 当然也认为较短字段应该有更多的权重,但是它会分别考虑每个字段内容的平均长度,这样就能区分短 title 字段和 长 title 字段。
在 查询时权重提升 中,已经说过 title 字段因为其长度比 body 字段 自然 有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。