遵循三范式。你想想你们公司如果连数据库字段都没有一个规则的话,也就是说你们公司开发都没有一个限制,那么你们是不是开发起来对接起来很麻烦呀,包括后面来的人接手前面的工作,完成搞不懂前一个人的开发流程。这样维护起来是不是很麻烦?
原则:定长和非定长数据类型的选择
decimal不会损失精度,存储空间会随数据的增大而增大。double占用固定空间,较大数的存储会损失精度。非定长的还有varchar、text
原则:尽可能使用 not null
非null字段的处理要比null字段的处理高效些!且不需要判断是否为null。因为null在MySQL中,不好处理,存储需要额外空间,运算也需要特殊的运算符。
语句优化:
语句1:select * from student limit 9,4
语句2:slect * from student limit 4 offset 9
// 语句1和2均返回表student的第10、11、12、13行
// 语句2中的4表示返回4行,9表示从表的第十行开始
再说一下我数据库查询这里的思路,因为逐步写入EXCEL的数据实际上来自Mysql的分页查询,大家知道其语法是LIMIT offset, num 不过随着offset越来越大Mysql在每次分页查询时需要跳过的行数就越多,这会严重影响Mysql查询的效率(包括MongoDB这样的NoSQL也是不建议skip掉多条来取结果集),所以我采用LastId的方式来做分页查询。这样从后面开始查是不是就好一些了?通过ID分组来一个降序查:
建立索引,但是不是索引越多越好。
普通索引:对关键字没有限制
唯一索引:要求记录提供的关键字不能重复
主键索引:要求关键字唯一且不为null
可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(alter table 表名 add index(字段名)),同样的SQL执行的效率,你会发现查询效率会有明显的提升(数据量越大越明显)。
mysql主从复制作用和原理
一、什么是主从复制?
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库
二、主从复制的作用
1、做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3、读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
问题及解决方法
mysql主从复制存在的问题:
主库宕机后,数据可能丢失
从库只有一个sql Thread,主库写压力大,复制很可能延时
解决方法:
半同步复制---解决数据丢失的问题
并行复制----解决从库复制延迟的问题
三、主从复制的原理
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作:
1.binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
2.从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
3.从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从复制如图:

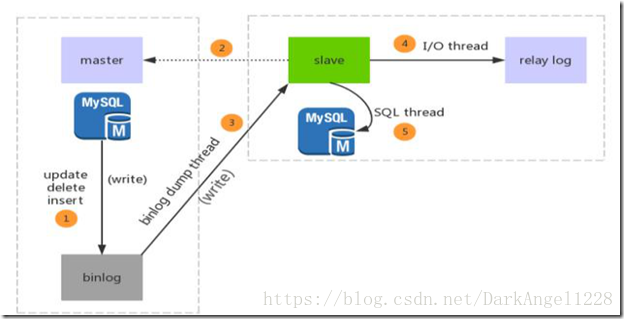
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
优化网站性能 数据库机构优化:
读写分离和分库分表:随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分库分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切分则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务的不同来切分,如用户业务、商品业务相关的表放在不同的数据库中。

还可以使用NoSql数据库和搜索引擎来做到这个网站优化性能
对于海量数据的查询和分析,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb、hbase、redis,搜索引擎有lucene、solr、elasticsearch。
