1.主从复制原理
在执行slaveof 命令后,复制过程便开始运作
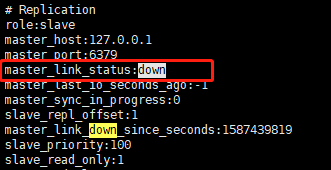
1)保存主节点(master)信息。执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始,在执行slaveof的从节点中可以看到master_link_status:down的状态,从统计信息可以看出,主节点的ip和port被保存下来,但是主节点的连接状态(master_link_status)是下线状态
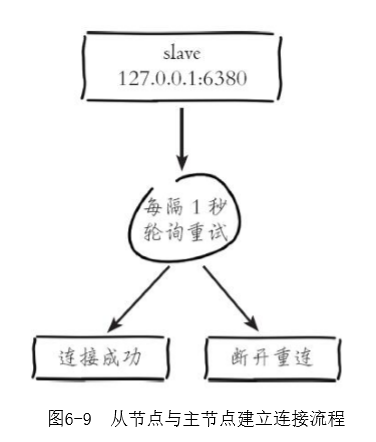
2)从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接,从节点会建立一个socket套接字,例如图6-8中从节点建立了一个端口为24555的套接字,专门用于接受主节点发送的复制命令
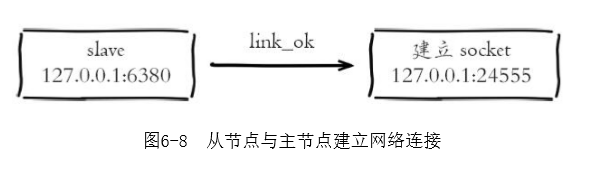
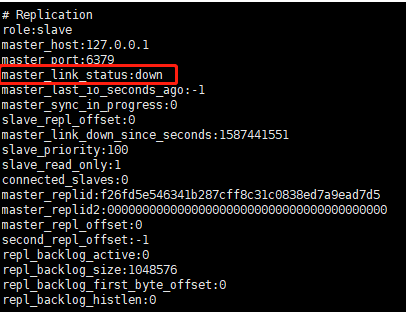
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行slaveof no one取消复制,关于连接失败,可以在从节点执行info replication查看master_link_down_since_seconds指标,它会记录与主节点连接失败的系统时间
3)发送ping命令。连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的如下:
·检测主从之间网络套接字是否可用。
·检测主节点当前是否可接受处理命令。
如果发送ping命令后,从节点没有收到主节点的pong回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连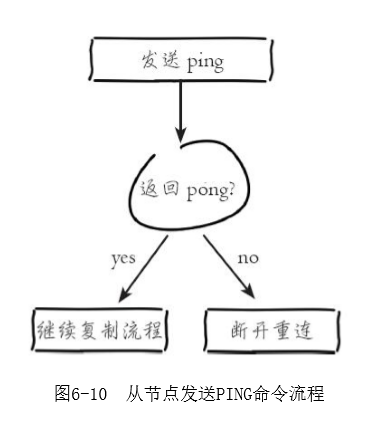
4)权限验证。如果主节点设置了requirepass参数,则需要密码验证,从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程
5)同步数据集。主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。Redis在2.8版本以后采用新复制命令psync进行数据同步,原来的sync命令依然支持,保证新旧版本的兼容性
6)命令持续复制。当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
2.搭建主从复制
## step 1
## vim /usr/conf/redis/6379.conf
## 修改配置文件
## port 6379
## pidfile /tmp/redis_6379.pid
## logfile "/usr/logs/redis/redis6379.log"
## dir /usr/data/redis4_6379
##slaveof 配置主从,也可以redis-cli 后执行slaveof
## step 2
## 按上面的步骤创建3个
## redis-server /usr/conf/redis/redis6379.conf
## redis-server /usr/conf/redis/redis6380.conf
## redis-server /usr/conf/redis/redis6381.conf
## step 3
## netstat -lnp | grep redis

## step 4
## redis-cli -p 6380
## slaveof 127.0.0.1 6379
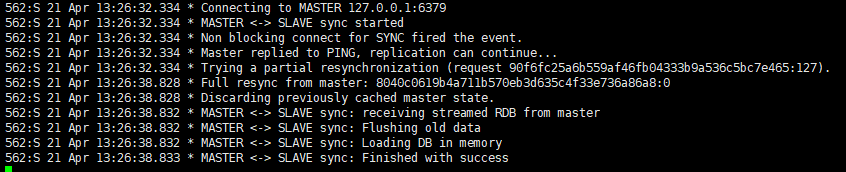
## slave 日志(这里执行了部分复制,不是全量复制,下面对比这两种复制)
3800:S 22 Apr 11:47:00.251 * DB loaded from disk: 0.000 seconds 3800:S 22 Apr 11:47:00.252 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer. ## 可能可以执行部分复制 3800:S 22 Apr 11:47:00.252 * Ready to accept connections 3800:S 22 Apr 11:47:00.252 * Connecting to MASTER 127.0.0.1:6379 ## 连接到master 3800:S 22 Apr 11:47:00.252 * MASTER <-> SLAVE sync started ## 同步开始 3800:S 22 Apr 11:47:00.252 * Non blocking connect for SYNC fired the event. 3800:S 22 Apr 11:47:00.252 * Master replied to PING, replication can continue... ## master有响应,复制继续 3800:S 22 Apr 11:47:00.252 * Trying a partial resynchronization (request d46e024f8d9608a34ce5c30f039ad40f8a7ebbf1:603). ## 尝试进行部分复制,请求master_replid为d46e024f8d9608a34ce5c30f039ad40f8a7ebbf1,偏移量603开始的backlog 3800:S 22 Apr 11:47:00.252 * Successful partial resynchronization with master. ## 部分复制成功 3800:S 22 Apr 11:47:00.252 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization.
## master日志
3773:M 22 Apr 11:47:00.252 * Slave 127.0.0.1:6381 asks for synchronization ## 接收到6381的同步请求 3773:M 22 Apr 11:47:00.252 * Partial resynchronization request from 127.0.0.1:6381 accepted. Sending 0 bytes of backlog starting from offset 603. ## 部分请求成功,发送了0数据,因为断开后没作修改 ## 主动slaveof no one 重连后不会使用部分复制
## redis-cli -p 6381
## slave of 127.0.0.1 6379
## redis-cli -p 6379
2.主要复制参数
|
参数
|
说明
|
|---|---|
| slaveof | 复制选项,slave复制对应的master |
| masterauth | 如果master设置了requirepass,那么slave要连上master,需要有master的密码才能连上 |
| replica-serve-stale-data |
当从库和主库失去连接或者复制正在进行时 ## yes:从库会继续响应客户端的请求 ## no: 当有请求来的时候返回一个错误”SYNC with master in progress” |
| slave-read-only | 作为从服务器,是否只读 |
|
是否使用socket方式复制数据。目前redis复制提供两种方式 disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave,当一个rdb保存的过程中,多个slave都能共享这个rdb文件 socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave |
|
| repl-diskless-sync-delay | diskless复制的延迟时间,一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输,最好等待一段时间,等更多的slave连上再开始复制 |
| repl-ping-slave-period | slave根据指定的时间间隔向服务器发送ping请求 |
| repl-timeout | 复制连接超时时间,master和slave都有效 |
| repl-disable-tcp-nodelay |
## yes: 禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽 ## no : 默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes |
| repl-backlog-size |
复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令,这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步 只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态,缓冲区的大小越大,slave离线的时间可以更长 当slave过了很久才重连上和复制缓冲区的内容对不上,只能执行全部复制,如RDB和AOF |
| repl-backlog-ttl | master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒 |
| slave-priority | 当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master,而配置成0,永远不会被选举 |
| min-slaves-to-write | redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write,健康的slave的个数小于N,mater就禁止写入,避免哨兵模式master不可用仍向该节点写入数据 |
| min-slaves-max-lag | 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave 单位秒 ,1和0都是关闭这个功能 |
slaveof
在配置文件中设置,永远有效
在redis客户端执行slaveof命令,重启redis后无效
master上配置acquirepass
slave上配置masterauth
当master上有设置密码,而slave配置中没有设置masterauth,不能开始复制,尽管输入了或者配置了slaveof命令
slave-serve-stale-data no

## 当 slave-serve-stale-data 值为no时,当slave失去与master 的连接的时候,redis不能响应客户端的请求
## 当 slave-serve-stale-data 值为yes时,当slave失去与master 的连接的时候,redis能继续响应客户端请求
repl-diskless-sync
repl-disless-sync no: 使用socket发送rdb文件
repl-disless-sync yes: master端将RDB file写到disk,稍后再传送到slave端,尝试请求复制后,会阻塞repl-diskless-sync-delay秒,等待更多slave连上master
## slave:

## master:

## master 上尽管收到有slave 连上,仍然会等待repl-diskless-sync-delay秒 ,
repl-ping-slave-period 5

## 每5秒ping 一次master,当超过repl-timeout没响应时认为复制中断,cluster集群不受这个参数影响
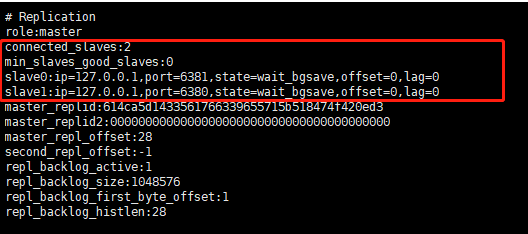
min-slaves-to-write 5
## redis-cli -a 12345 set qweerg sjias

## 健康的slave的个数小于5,mater就禁止写入
## 通过参数 min-slaves-max-lag 来判断延迟多少以内为健康的slave
3.全量复制和部分复制
全量复制
- 发送 psync 命令(spync ? -1)
- 主节点根据psync-1解析出当前为全量复制,回复+FULLRESYNC响应
- 从节点接收主节点的响应数据保存运行ID和偏移量offset
- 主节点 bgsave 并保存 RDB 到本地
- 主节点发送 RBD 文件到从节点
- 主节点在从节点接受数据的期间,将新数据保存到“复制客户端缓冲区”,从节点加载完 RDB 完毕,再发送缓冲区backlog过去。
- 从节点清空数据后加载 RDB 文件,如果 RDB 文件很大,这一步操作仍然耗时,如果此时客户端访问,将导致数据不一致,可以使用配置slave-server-stale-data 关闭.
- 从节点成功加载完 RBD 后,如果开启了 AOF,会立刻做 bgrewriteaof。
- 对于数据量较大的主节点,比如生成的RDB文件超过6GB以上时要格外小心。传输文件这一步操作非常耗时,速度取决于主从节点之间网络带宽,通过细致分析Full resync和MASTER<->SLAVE这两行日志的时间差,可以算出RDB文件从创建到传输完毕消耗的总时间。如果总时间超过repl-timeout所配置的值(默认60秒),从节点将放弃接受RDB文件并清理已经下载的临时文件,导致全量复制失败
- 对于高流量写入场景非常容易造成主节点复制客户端缓冲区溢出。默认配置为client-output-bufferlimit slave256MB64MB60,如果60秒内缓冲区消耗持续大于64MB或者直接超过256MB时,主节点将直接关闭复制客户端连接,造成全量同步失败
- 对于主节点,当发送完所有的数据后就认为全量复制完成,打印成功日志:Synchronization with slave127.0.0.1:6380succeeded,但是对于从节点全量复制依然没有完成,还有后续步骤需要处理。
-
从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能,它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用
全量复制的开销
- 主节点bgsave时间。
- RDB文件网络传输时间。
- 从节点清空数据时间。
- 从节点加载RDB的时间。
- 可能的AOF重写时间。
部分复制
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施,使用psync{runId}{offset}命令实现。当从节点(slave)正在复制主节点(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。补发的这部分数据一般远远小于全量数据,所以开销很小
- 当从节点出现网络中断,超过了 repl-timeout 时间,主节点就会中断复制连接。
- 主节点会将请求的数据写入到“复制积压缓冲区”,默认 1MB。
- 当从节点恢复,重新连接上主节点,从节点会将 offset 和主节点 id 发送到主节点。
- 主节点校验后,如果偏移量的数后的数据在缓冲区中,就发送 cuntinue 响应 —— 表示可以进行部分复制。
- 主节点将缓冲区的数据发送到从节点,保证主从复制进行正常状态
心跳
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令
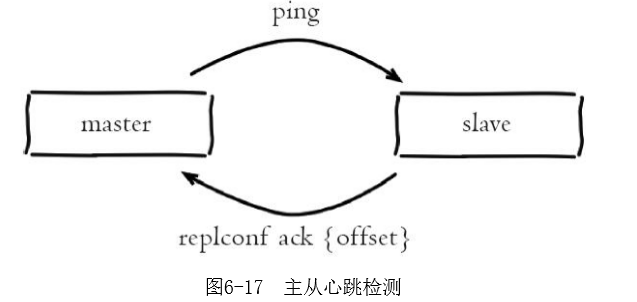
主从心跳判断机制:
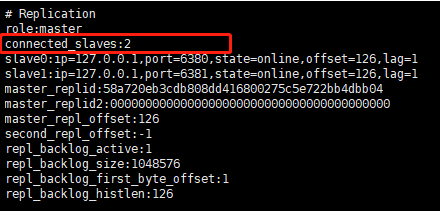
1)主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,通过client list命令查看复制相关客户端信息,主节点的连接状态为flags=M,从节点连接状态为flags=S。
2)主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活性和连接状态。可通过参数repl-ping-slave-period控制发送频率。
3)从节点在主线程中每隔1秒发送replconf ack{offset}命令,给主节点上报自身当前的复制偏移量。replconf命令主要作用如下:
- 实时监测主从节点网络状态。
- 上报自身复制偏移量,检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓冲区中拉取丢失数据。
- 实现保证从节点的数量和延迟性功能,通过min-slaves-towrite、min-slaves-max-lag参数配置定义。主节点根据replconf命令判断从节点超时时间,体现在inforeplication统计中的lag信息中,lag表示与从节点最后一次通信延迟的秒数,正常延迟应该在0和1之间。如果超过repl-timeout配置的值(默认60秒),则判定从节点下线并断开复制客户端连接。即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。