网络中的链路容量和交换结点中的缓存和处理机都有着工作的极限,当网络的需求超过它们的工作极限时,就出现了拥塞。拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。常用的方法就是
1. 慢开始和拥塞避免
2. 快重传和快恢复
下面分别说一下两种方法:
1. 慢开始和拥塞避免
发送方维持一个叫做“拥塞窗口”的变量,该变量和接收端口共同决定了发送者的发送窗口;
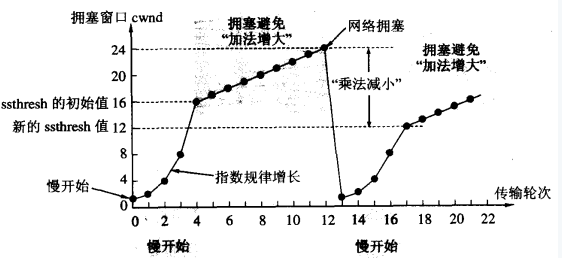
当主机开始发送数据时,避免一下子将大量字节注入到网络,造成或者增加拥塞,选择发送一个1字节的试探报文;
当收到第一个字节的数据的确认后,就发送2个字节的报文;
若再次收到2个字节的确认,则发送4个字节,依次递增2的指数级;
最后会达到一个提前预设的“慢开始门限”,比如24,即一次发送了24个分组。慢开始门限ssthresh的用法如下:
cwnd < ssthresh, 继续使用慢开始算法;
cwnd > ssthresh,停止使用慢开始算法,改用拥塞避免算法;
cwnd = ssthresh,既可以使用慢开始算法,也可以使用拥塞避免算法;
所谓拥塞避免算法就是:每经过一个往返时间RTT就把发送方的拥塞窗口+1,即让拥塞窗口缓慢地增大,按照线性规律增长;
当出现网络拥塞,比如丢包时,将慢开始门限设为出现拥塞时窗口值的一半,然后将cwnd设为1,执行慢开始算法(较低的起点,指数级增长);
2. 快重传和快恢复
如果发送方设置的计时器超时仍然没有收到确认,那么很可能是网络出现了拥塞,导致报文在网络的某处被丢弃,在这种情况下TCP马上把拥塞窗口cwnd减小到1,并执行慢开始算法,同时把慢开始门限值ssthresh减半,这就是不使用快重传的情况。
再看使用快重传的情况,该算法要求接收方每收到一个失序的报文段后立刻发出确认(为的就是让发送方及早知道有报文段没有达到对方),而不要等待自己发送数据时才进行捎带确认。
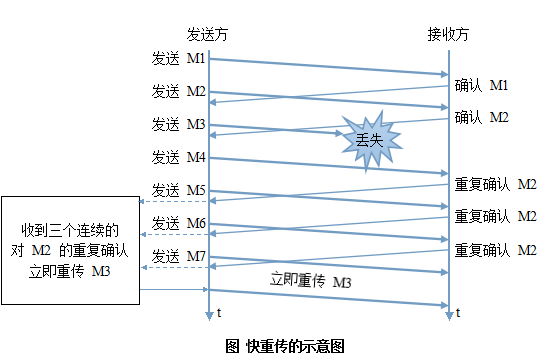
在上面的M3没有达到的情况下,根据可靠传输原理,接收方可以什么都不用做,也可以在适当的时机发送一次对M2的确认,静静的等待发送方M3的计时器超时重发。现在的快重传不是这样的,它要求在发送发收到对某个序号的重复三次确认后,就立即重发该序号,不要等到计时器超时。这样可以尽早的重传未被确认的报文段,因此使用快重传后可以使整个网络的吞吐量提高约20%。
总结:这里的一个小的改动就接收方立即给出确认报文,发送方不在傻傻的等自己想要的报文的确认,因为这样可能等不到该序号的确认,等来的全是失序报文的确认,最后导致计时器超时。所以要发送方等待三个重复的失序报文的确认就立即重传报文,不用等到计时器超时。
与快重传配合的就是快恢复,当连续收到三个重复确认的报文时,执行“乘法减少”,把慢开始门限减半,这是为了预防网络发生拥塞。这时发送方认为网络可能没有发生拥塞,因为如果真的发生了拥塞,就不会有一连串的有好几个失序报文到达接收方,更不会一连串的能收到这些失序报文的确认。因此这时把cwnd值设置为慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法(加法增大)。
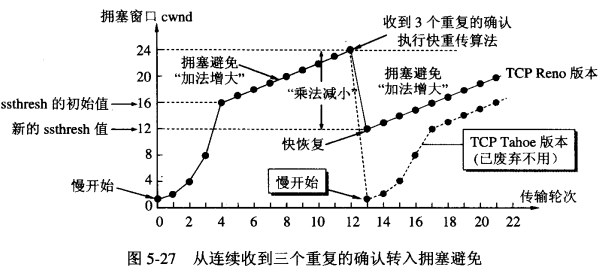
注意:这里不是说慢开始和拥塞避免就没有用了,不是的。采用快重传和快恢复算法的时候,慢开始在TCP连接建立时或者网络出现超时(也就是发送端的超时计时器超时)时仍然需要使用。