首先生成正则表达式练习的数据:
#! /usr/bin/python
from random import randint, choice
from string import lowercase
from sys import maxint
from time import ctime
doms = ('com', 'edu', 'net', 'org', 'gov')
for i in range(randint(5, 10)):
#generate time in string format
dtint = randint(0, maxint - 1)
dtstr = ctime(dtint)
#generate user name, length:4~7
shorter = randint(4, 7)
em = ''
for j in range(shorter):
em += choice(lowercase)
#generate domain name, length:shorter~12
longer = randint(shorter, 12)
dn = ''
for j in range(longer):
dn += choice(lowercase)
print '%s::%s@%s.%s::%d-%d-%d' % (dtstr, em, dn, choice(doms), dtint, shorter, longer)
每次gendata.py执行都会产生5~10行的输出,在每行的输出中,我们从int类型的范围内,随机的挑选一个整数,并把这个整数换算成计算机的时间,换算的方法就是从1970年1月1日零点到现在的秒数。
random.choice()这个函数的用处就是根据指定的序列,随机返回该序列中的一个元素,在这里我们指定序列是26个小写字母,string.lowercase。
登陆名的长度为4~7个字符,虚拟邮箱的地址的域名长度在4~12个字符,但是不能短于登录名的长度。
看生成的数据:
Wed May 27 07:48:25 1981::ufbfecs@surdpbsoru.net::359768905-7-10 Thu Apr 7 09:42:29 2033::ewanfh@znkvahbcorb.edu::1996450949-6-11 Fri Feb 9 20:25:16 1979::icopo@aeslbbik.gov::287411116-5-8 Fri Aug 22 03:58:37 2031::gtigjb@oundjfu.org::1945108717-6-7 Tue Jan 23 07:34:12 1979::tatxg@nztitfrkc.net::285896052-5-9 Tue May 29 17:25:57 1973::uohh@qxhwzrpu.gov::107515557-4-8 Thu Feb 1 05:44:21 1973::quiafo@lmltvmi.gov::97364661-6-7 Sun Feb 26 04:46:30 1984::ynpvvju@ygdcbqkk.edu::446589990-7-8
利用生成的数据,提取星期:
#! /usr/bin/python
import re
#p = re.compile(r'^(Mon|Tue|Wed)')
p = re.compile(r'^(w{3})')
f = open('gendata.txt', 'r')
for eachLine in f.readlines():
m = p.match(eachLine.strip())
if m is not None:
print m.groups()
f.close()
利用生成的数据,提取后面的数字:
在这里,如果用匹配的方法,就不得不写一个正则表达式来匹配整行内容,并用子组保存我们感兴趣的那部分数据,在这里用搜索的方法更合适。
#! /usr/bin/python
import re
p = re.compile(r'd+-d+-d+')
f = open('gendata.txt', 'r')
for eachLine in f.readlines():
s = p.search(eachLine.strip())
if s is not None:
print s.group()
f.close()
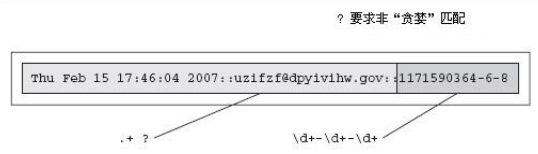
如果用匹配的方法,那么正则表达式要设计为:
r'.+(d+-d+-d+)'
但是这样的设计是不行的,因为python默认是贪心匹配的,所以会出现这样的结果:
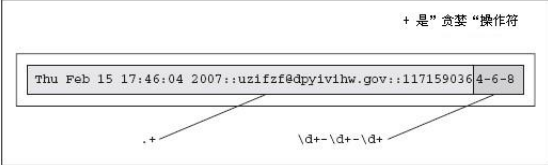
所以要修改正则表达式:
r'.+?(d+-d+-d+)'