| 作业要求地址 | https://www.cnblogs.com/harry240/p/11524113.html |
| GitHub地址 | https://github.com/anranbixin/WordCount |
| 结对伙伴的博客 | https://www.cnblogs.com/mylovertomylove/p/11652247.html |
PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
40 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1200 |
1440 |
|
Development |
开发 |
1080 |
1200 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
40 |
50 |
|
· Design Spec |
· 生成设计文档 |
20 |
20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
30 |
|
· Design |
· 具体设计 |
60 |
50 |
|
· Coding |
· 具体编码 |
700 |
960 |
|
· Code Review |
· 代码复审 |
60 |
50 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 |
150 |
|
Reporting |
报告 |
30 |
20 |
|
· Test Report |
· 测试报告 |
60 |
40 |
|
· Size Measurement |
· 计算工作量 |
30 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
20 |
|
合计 |
1230 |
1480 |
题目描述:
代码要求:
- 统计文件的字符数(空格,水平制表符,换行符,均算字符):
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
新增要求:
a) 词组统计:能统计文件夹中指定长度的词组的词频
b) 自定义输出:能输出用户指定的前n多的单词与其数量
(1).-i 参数设定读入的文件路径 wordCount.exe -i input.txt
(2).-m 参数设定统计的词组长度 wordCount.exe -m 3 -i input.txt
(3)-n参数设定输出的单词数量
(4)-o参数设定生成文件的存储路径,则将统计信息输出到文件output.txt中
(5)多参数的混合使用
解题思路过程:
刚开始拿到题目时,我们一片茫然,不知所措,因为之前落下的C#的学习导致后面编写代码时出现了很多问题,
比如:
1.怎样将命令行中的路径通过命令行传入到函数中,使得函数通过命令行的文本路径,得到文本input.txt中的单词数、行数、字符数。在这里感谢前面的师兄师姐和博客园其他给我们提供帮助的人们。
当时并不打算做附加问题,也不知道怎样把命令行中的路径给提取出来,若做-i,-m,-n,-o问题就能直接从args[i]中读取-i后面的一个字符串,通过-i命令提示符得到字符路径,同理通过-o命令提示符得到文本存储路径,通过-n [number]得到number,通过-m [number]得到number。
(PS:我们现在才知道static void Main(string[] args)中的string[] args 指的是我们在命令窗口输入的参数,通过命令窗口接收命令。现在才知道它的作用,后悔当初没认真听课!)
2.怎样提取路径path中input.txt文本中的字符串。当时我们设想将整个文本使用StreamReader sw = file.OpenText();string temp = sw.Read();通过流的方式一个字符一个字符的进入流中,但如果这样实施的话,就会导致后面的行数无法确定,而且读取速度也非常慢;
若使用按行读取的方法StreamReader content = new StreamReader(path);string temp = content.ReadLine();这样读进流中时,就能直接确定input.txt中的文本行数 ,读取速度也较快。
3.怎样判断这个单词满足上述条件
当时我们走了很多弯路,决定用ASII码值通过 97<=words[i]<=122||65<=words[i]<=90 这样的方式来判断单词前四个字符都是英文,但我们觉得这样太麻烦了,于是在网上查找资料,发现可以使用正则表达式直接判断,利用MatchCollection mc_word = Regex.Matches(account_chara, @"([a-zA-Z]{4}w*)")方法,其中[a-zA-Z]是用来判断英文字符,{4},判断前面4个字符是否都满足[a-zA-Z]的条件,这样一来直接通过正则表达式就可以判断单词是否满足上述条件。而单词个数可以通过函数WordNum()的word
通过正则表达式判断好满足条件的单词我们将它加入到一个result列表中,那怎样存储频数呢?首先我们需要将所有大小写统一转换成小写,方便系统检测,此时我们可以使用字典将满足条件的单词作为key,将其频数作为value。
此时知道如何存储单词和频数了,那如何计算频数呢?此时需要字典Dictionary的ContainsKey方法,若单词字典中第一次出现该单词,则将该单词的value的值赋为1,若此前出现过该单词,则将该单词中的value值就+1。
4.-i和-o命令提示符后的路径都可以通过Directory.GetCurrentDirectory()方法直接获取当前路径filepath,加上我们后面的文件input.txt,即path=path+"\"+input.txt,但这里出现了一个问题,当时这样运行时,发现了一个问题,系统提示“无法获取当前文件路径”,我们检查了 很久,一直没发现到底哪儿错了,后面通过在控制台中打印整个路径,发现其中path和"input.txt"中间没有用"/"连接,后面我们将路径更改为path=path+"\"+input.txt才得以解决这个问题。
5.-n后面加上数字则表示设定输出的单词数量,通过开始将单词作为key,将频数作为value时,使用Dictionary的OrderByDescending方法通过value的值--单词频数倒序排序,这样我们就可以直接找到前n个高频数的单词并将其打印出来。
6.-m后面加上数字是表示以这个数字表示词组的单词个数,因此物品们可以利用循环嵌套的方法将词组放在一个集合中,最后在控制台中打印出来,并将其结果放入output.txt文件中。
功能模块图如下:

关键函数的流程图如下:
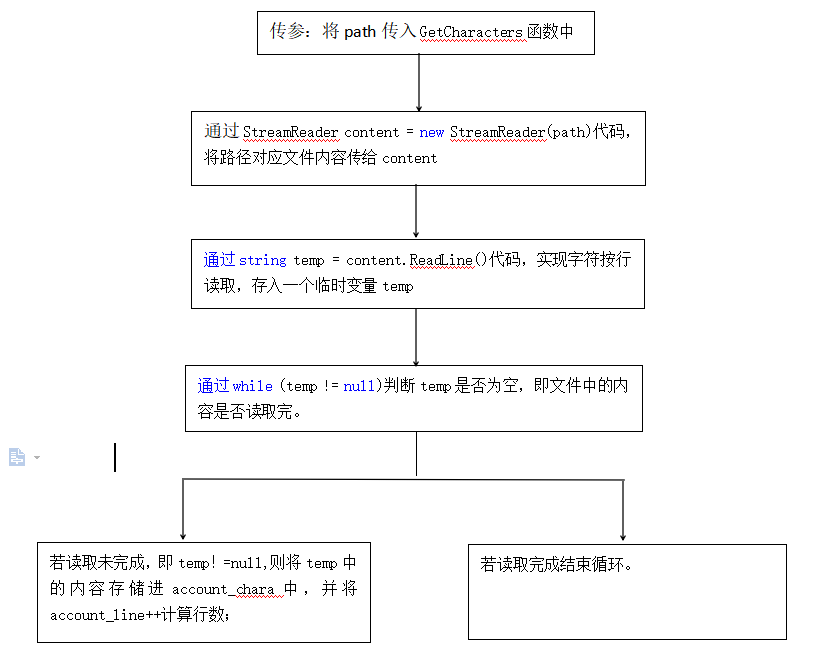
1. GetCharacters (string path)函数的流程图
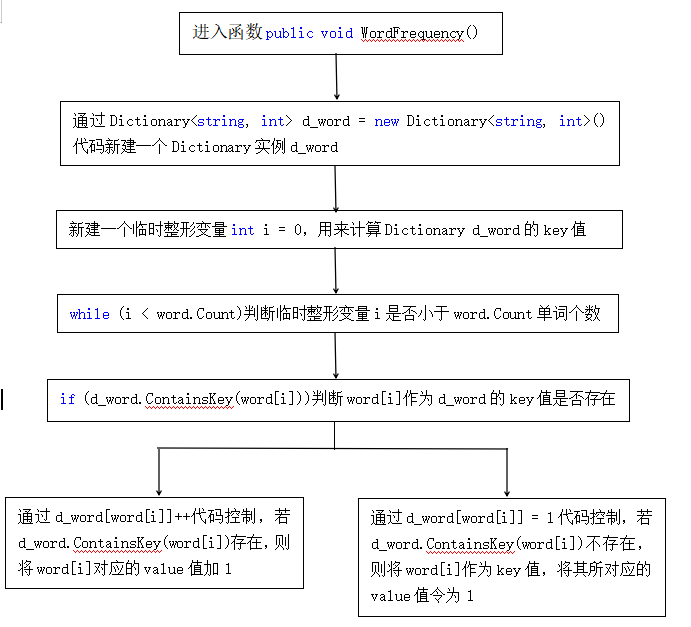
2.public void WordFrequency()流程图如下:
代码规范
我们本着“保持简明,让代码更容易读”的原则,让我们更好地理解和维护程序。
代码风格的原则是:简明,易读,无二义性。
1.缩进:
4个空格,在VS2017和其他的一些编辑工具中都可以定义Tab键扩展成为几个空格键。不用 Tab键的理由是Tab键在不同的情况下会显示不同的长度。4个空格的距离从可读性来说正好。
2.括号:
在复杂的条件表达式中,用括号清楚地表示逻辑优先级。
3.断行与空白的{ }行:
每个“{”和“}”都独占一行
如:
if ( condition)
{
DoSomething();
}
else
{
DoSomethingElse();
}
4.分行:
不要把多行语句放在一行上。
5.命名:
命名方法使用“匈牙利命名法”,在变量面前加上有意义的前缀,就可以让程序员一眼看出变量的类型及相应的语义
例如:
fFileExist,表明是一个bool值,表示文件是否存在;
szPath,表明是一个以0结束的字符串,表示一个路径。
6.下划线问题:
下划线用来分隔变量名字中的作用域标注和变量的语义
7.大小写问题:
由多个单词组成的变量名,如果全部都是小写,很不易读,一个简单的解决方案就是用大小写区分它们。
Pascal——所有单词的第一个字母都大写;
Camel——第一个单词全部小写,随后单词随Pascal格式,这种方式也叫lowerCamel。
一个通用的做法是:所有的类型/类/函数名都用Pascal形式,所有的变量都用Camel形式。
类/类型/变量:名词或组合名词,如Member、ProductInfo等。
函数则用动词或动宾组合词来表示,如get/set; RenderPage()。
8.注释:
复杂的注释应该放在函数头,养成边写代码边写注释的好习惯
代码说明如下:
将控制台上的命令通过参数args传入,得到-i -o -n -m选项的混合使用的命令,并将其中-n [number]和-m [number]中的number分别传入变量n和m中,代码如下:
for (int i = 0; i < args.Length; i++)//将控制台上的命令通过参数args传入
{
switch (args[i])
{
case "-i":
path = args[i + 1];//输入路径
break;
case "-o"://-o输出路径
outpath = args[i + 1];
break;
case "-m"://-m输出几个高频词
m = args[i + 1];
break;
case "-n"://-n输出几个单词的个数
n = args[i + 1];
break;
default:
Console.WriteLine("输入有误,请检查");
break;
}
}
GetCharacters将文件中的文本以字符串的形式存储进account_chara,同时计算文本行数account_line
public void GetCharacters(string path)
{
StreamReader content = new StreamReader(path);//为StreamReader创建实例
string temp = content.ReadLine();//定义字符临时变量,按行读入
while (temp != null)//当读取的这一行不为空时,执行以下功能
{
account_chara = account_chara + temp;//将读入的文本通过字符串的形式存储在account_chara
account_line++;//计算行数
Console.WriteLine(account_line);
temp = content.ReadLine();//读取下一行
}
}
WithdraWord()是利用正则表达式从字符串account_chara中匹配英文单词(该英文单词要求为:以字母开头,数字结尾,单词至少4个字符)。
其中([a-zA-Z]{4}w*)中[a-zA-Z]表示英文字符,{4}表示前面[a-zA-Z]重复4次。
将满足条件的单词存放在word列表中,为下面将单词统一转换成小写和计算单词频数做准备。
//以字母开头,数字结尾,单词至少4个字符
public void WithdraWord() {
//MatchCollection表示以迭代的方式将正则表达式模式应用于输入字符串所找到的成功匹配的集合 MatchCollection mc_word = Regex.Matches(account_chara, @"([a-zA-Z]{4}w*)"); int i = 0;//临时变量 while (i < mc_word.Count) { word.Add(Convert.ToString(mc_word[i]));//存储单词 i++; } }
计算满足条件的单词个数
//单词总数
public int WordNum()
{
return word.Count;
}
将列表word中的所有字符元素全部转换成小写的形式,为下面计算单词频数做准备。
public void ToLower()//将word中的单词元素转换成小写
{
foreach (string element in word)
{
element.ToLower();
}
}
计算字符的个数,其中字符个数不包括中文的数量,因此需要排除中文的字符(正则表达式@"[^u4e00-u9fa5]*")
//字符总数
public int CharacterNum()
{
//区分是否为中文,中文用正则表达式表示为u4E00-u9FA5
MatchCollection mc_chara = Regex.Matches(account_chara, @"[^u4e00-u9fa5]*");
string temp = null;
int i = 0;
while (i < mc_chara.Count)
{
temp = temp + Convert.ToString(mc_chara[i]);
i++;
}
return temp.Length;
}
计算单词频数,将单词与单词频数存放在d_word字典中,按降序排序,为输出前n个频数做准备
public void WordFrequency()
{
Dictionary<string, int> d_word = new Dictionary<string, int>();//创建一个字典实例,将每个不同单词作为key值,将其频数作为其value
int i = 0;
while (i < word.Count)
{
if (d_word.ContainsKey(word[i]))//判断word[i]作为d_word的key值是否存在
{
d_word[word[i]]++;//若存在,则将word[i]对应的value值加1
}
else
{
d_word[word[i]] = 1;//若不存在,则将word[i]作为key值,将其所对应的value值令为1
}
i++;
}
//将d_word按照降序的方式排序(这样可以通过循环提取前n个最高频率的单词)
word_num = d_word.OrderByDescending(p => p.Value).ToDictionary(p => p.Key, o => o.Value);
}
WriteToFile(string path, string)将得到的数据输出到文件中
//写入文件
public void WriteToFile(string path, string outpath)
{
Prep(path);//获取文本的函数GetCharacters(path);提取符合题目要求的单词函数WithdraWord();将所有字符转换成小写的函数ToLower();计算每个单词出现频率函数WordFrequency()
FileInfo file = null;
if (outpath == null)//判断outpath是否存在
{
file = new FileInfo(@"D:VS_practice201731062402output.txt");//若不存在则添加一个新的文件
}
else//若存在则直接将该outpath赋给file
{
file = new FileInfo(outpath);
}
//将结果全部输入到outpath路径下的output.txt
StreamWriter sw = file.AppendText();
sw.WriteLine("字符数:" + CharacterNum());
sw.WriteLine("单词数:" + WordNum());
sw.WriteLine("行数:" + WordLineNum());
Console.WriteLine("字符数为:" + CharacterNum());
Console.WriteLine("单词数为:" + WordNum());
Console.WriteLine("行数为:" + WordLineNum());
//统计前10个高频单词
WriteWord(sw, 10);
//关闭文件
sw.Close();
Console.WriteLine("结果文件保存于:
D:\VS_practice\201731062402\output.txt");
}
WriteWord(StreamWriter sw, int n)为筛选出前n个高频单词并将其打印出来
public void WriteWord(StreamWriter sw, int n)
{
int flag = 0;
foreach (KeyValuePair<string, int> element in word_num)
{
string key = element.Key;
int value = element.Value;
//写入前n个高频单词,以及其频数
if (flag < n)
{
Console.WriteLine("单词 : {0} 频数是 : {1}", key, value);
sw.WriteLine("单词 :{0} 频数是 : {1}", key, value);
flag++;
}
}
}
WordGroup(StreamWriter sw, int m)计算以m个为一组的单词组,将其打印在屏幕上和output.txt中
public void WordGroup(StreamWriter sw, int m)
{
//Console.WriteLine("------------------------------");
//sw.WriteLine("------------------------------");
Dictionary<string, int> dc = new Dictionary<string, int>();
string list = null;
int i, j;
for (i = 0; i <= word.Count - m; i++)
{
list = word[i];
for (j = 1; j < m; j++)
{
list += " " + word[i + j];
}
if (dc.ContainsKey(list))
{
dc[list]++;
}
else
{
dc[list] = 1;
}
}
Dictionary<string, int> tt = dc.OrderByDescending(p => p.Value).ThenBy(o => o.Key).ToDictionary(p => p.Key, o => o.Value);
foreach (KeyValuePair<string, int> element in tt)
{
Console.WriteLine("词组为:{0} 次数为:{1}", element.Key, element.Value);
sw.WriteLine("词组为:{0} 次数为:{1}", element.Key, element.Value);
}
}
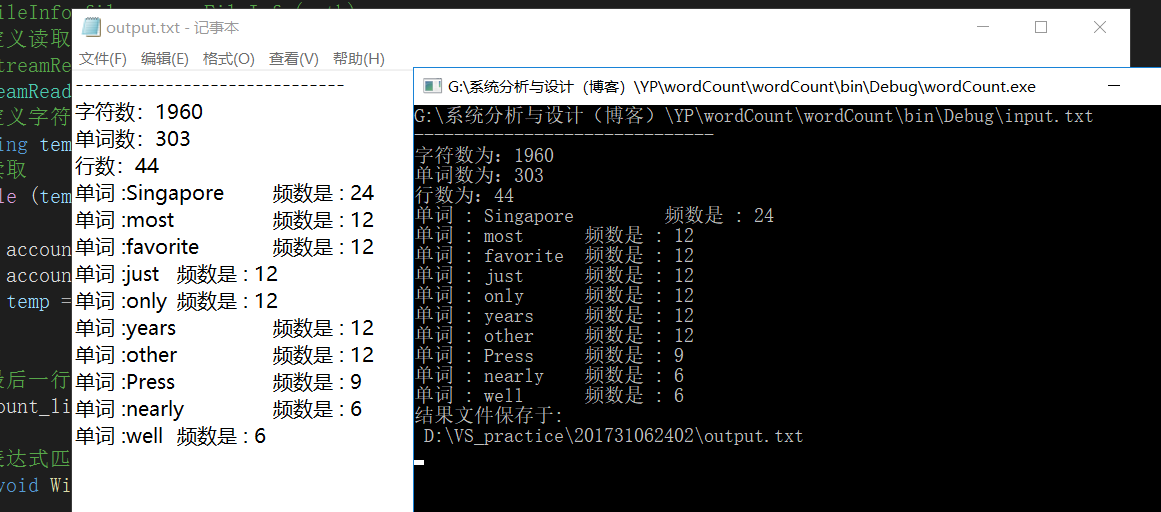
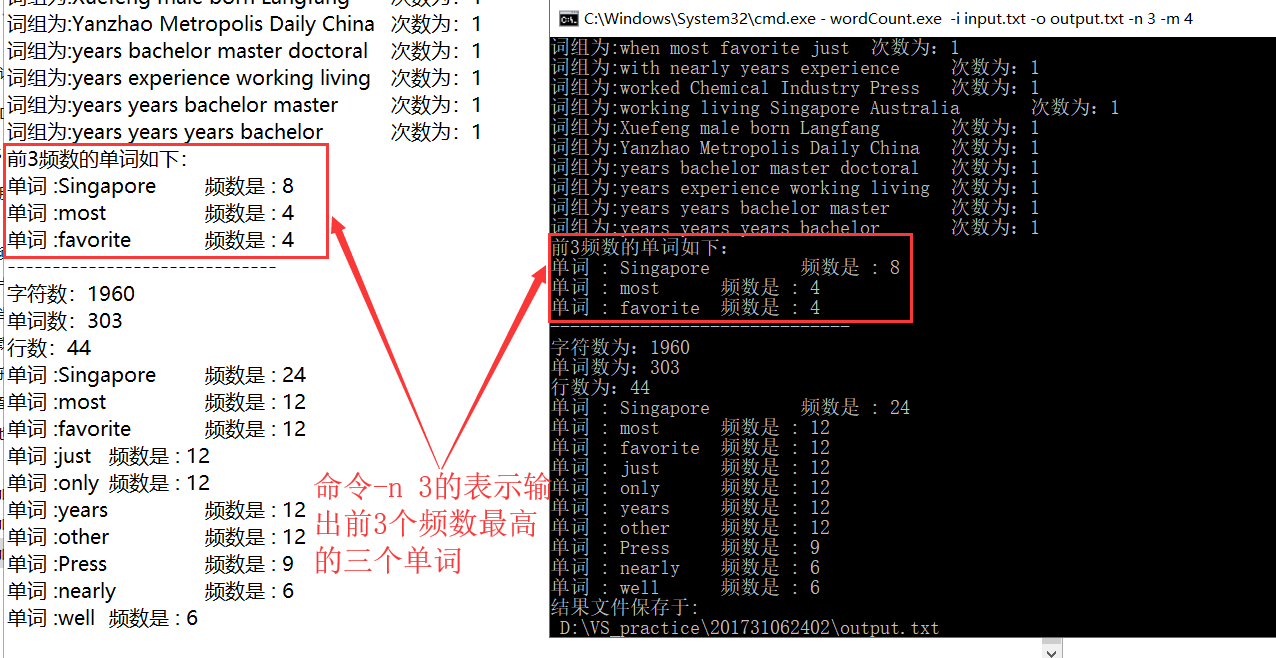
成功运行后截图如下:
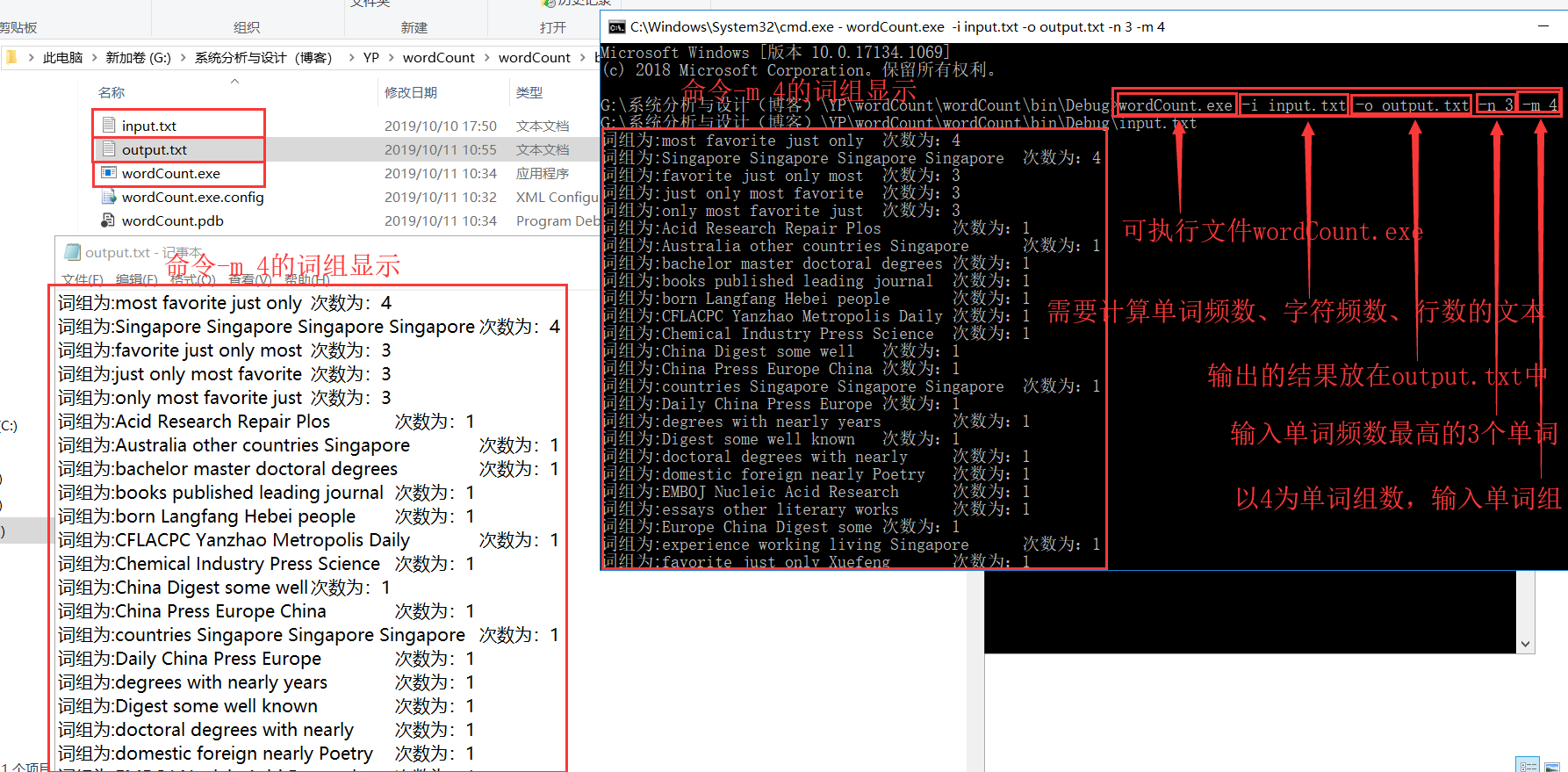
附加功能-i -o -n -m 的截图如下所示:
测试
上述测试代码为:
[TestMethod()]
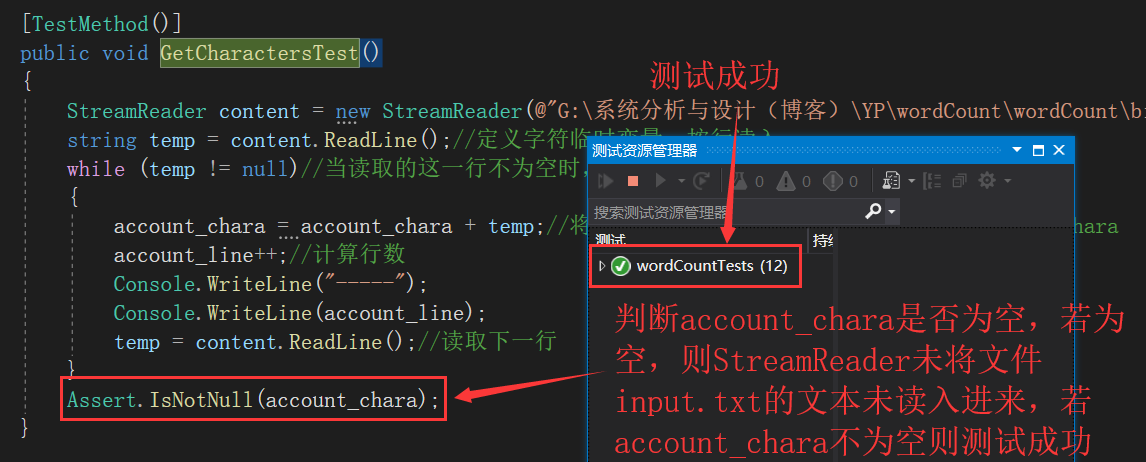
public void GetCharactersTest()
{
StreamReader content = new StreamReader(@"G:系统分析与设计(博客)YPwordCountwordCountinDebuginput.txt");//为StreamReader创建实例
string temp = content.ReadLine();//定义字符临时变量,按行读入
while (temp != null)//当读取的这一行不为空时,执行以下功能
{
account_chara = account_chara + temp;//将读入的文本通过字符串的形式存储在account_chara
account_line++;//计算行数
Console.WriteLine("-----");
Console.WriteLine(account_line);
temp = content.ReadLine();//读取下一行
}
Assert.IsNotNull(account_chara);
}
下面对WithdraWordTest()做测试,代码如下:
[TestMethod()]
public void WithdraWordTest()
{
MatchCollection mc_word = Regex.Matches("ABcd123", @"([a-zA-Z]{4}w*)");//MatchCollection表示以迭代的方式将正则表达式模式应用于输入字符串所找到的成功匹配的集合
int i = 0;//临时变量
while (i < mc_word.Count)
{
word.Add(Convert.ToString(mc_word[i]));//存储单词
i++;
}
Assert.IsNotNull(word);
}
下列12个函数全部测试完毕并成功通过,截图如下:(由于测试代码众多,这里只展示其中两个,代码如上所示)

性能分析
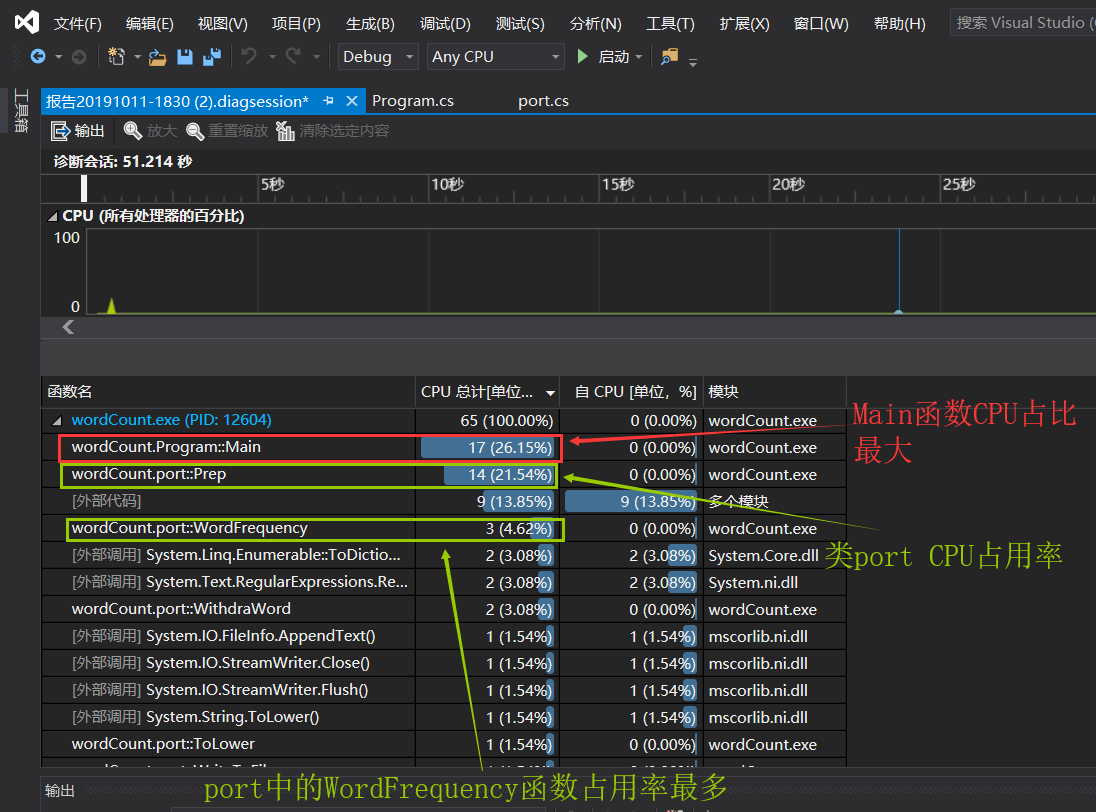
根据性能分析,可以看出Main函数中是CPU占比最多的函数,于是我们看到main函数,其中在该函数中,我们读取文件、将最后结果放在文件中所花时间、判断命令行中出现的命令选项、判断并打印结果等所花时间都很多,特别是文件的读取过程很慢,因此我们针对文件读取做了很多分析,最后减少了程序对文件的读取的个数使得性能加快。
而在另一个类port中,WordFrequency()函数占用率最高,因此我们针对WordFrequency()函数进行了分析,WordFrequency()函数中主要拖垮性能的原因是有大量的判断语句,判断d_word字典中的key值,即单词word[i]是否存在,若存在则执行value值加1的操作,若不存在,则将其作为key存入字典并将其value值令为1,因此我们在函数外将我们需要判断的值优先判断,最后再根据其判断值进行value的值操作,加快了程序性能。
提交代码到Github

结对编程编程过程图片:

总结
这一路磕磕绊绊,又重新学习了C#,对C#又有了更加深入的了解,特别是泛型Dictionary的运用,它的结构是这样的:Dictionary<[key], [value]>,Dictionary存入对象是需要与[key]值一一对应的存入该泛型,通过某一个一定的[key]去找到对应的值,因为这个题目需要大量元素以及该元素出现的频率,最开始时,我们学习的C#只停留在简单的基础操作中,没有深入的学习C#其中封装好的函数,因此没有想到用Dictionary的方法去做,一股脑儿的使用二维数组去做,中途碰到了很多bug难以解决,最后在网上查找资料,看到Dictionary能够很好的解决这个问题,因此我们又重新开始使用库提供给我们的Dictionary,这个过程非常艰辛。虽然挫折一波接着一波,但我们还是共同努力,体会到1+1>2的好处,我的结对小伙伴在编写这个函数的功能时,我就在看下一个函数如何设计,就这样轮换着来,终于把这个项目给做出来了。
1+1有时候真的大于2!!