explain所有人都应该很熟悉,通过它我们可以知道SQL是如何执行的,虽然不是100%管用,但是至少大多数场景通过explain的输出结果我们能直观的看到执行计划的相关信息。
早一些的版本explain还只能查看select语句,现在已经能支持delete,update,insert,replace了。
刚开始我想写这个的时候只是因为这个东西经常性不用就忘记,写了发现其实这个东西真的挺麻烦的,要把每个场景都整出来麻烦的很。
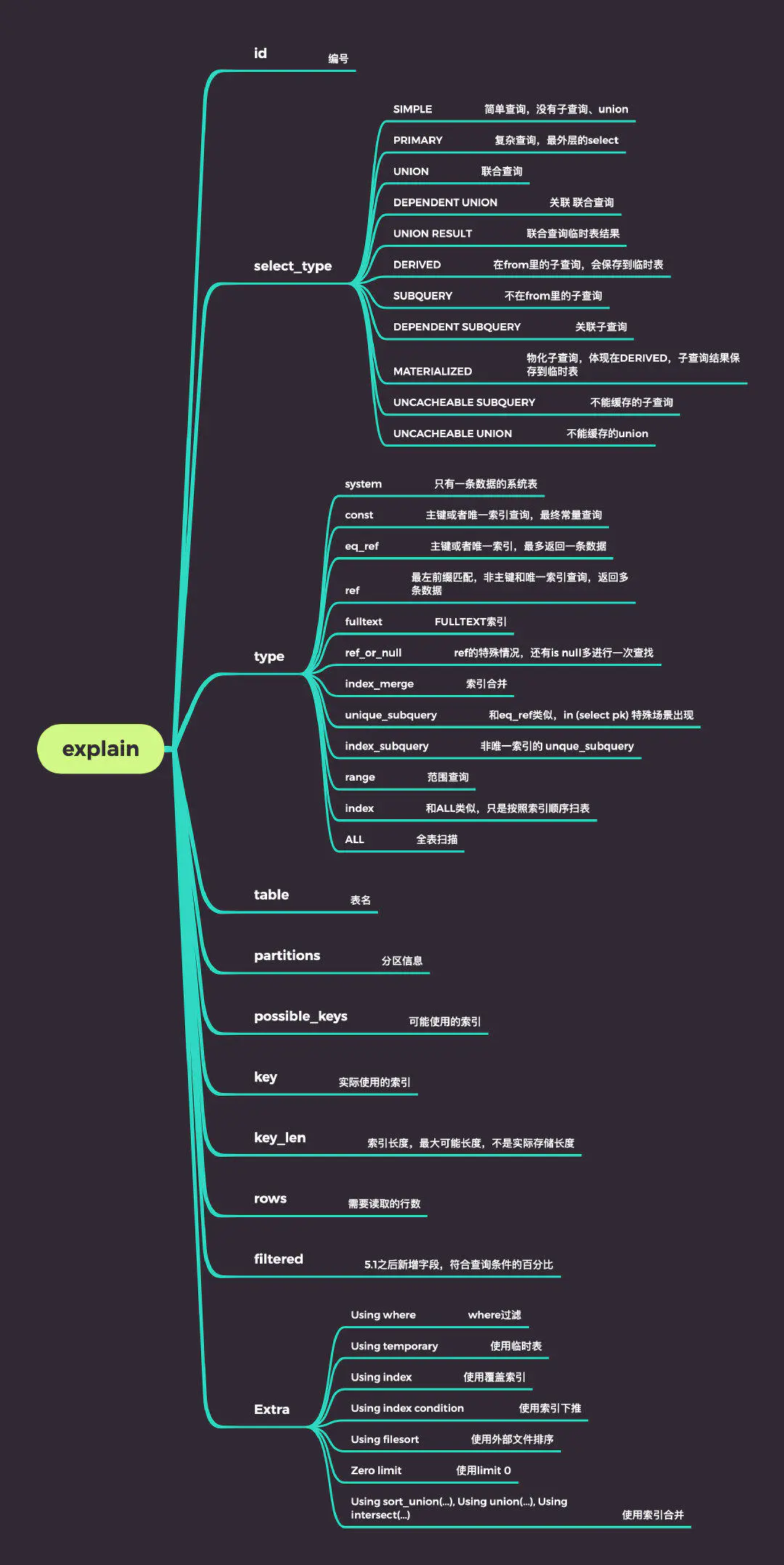
id
查询编号,如果没有子查询或者联合查询的话,就只有一条,如果是联合查询的话,那么会出现一条id为null的记录,并且标志查询结果,因为union结果会放到临时表中,所以我们看到这里的表名是<union1,2>这种格式。

select_type
关联类型,决定访问表的方式。
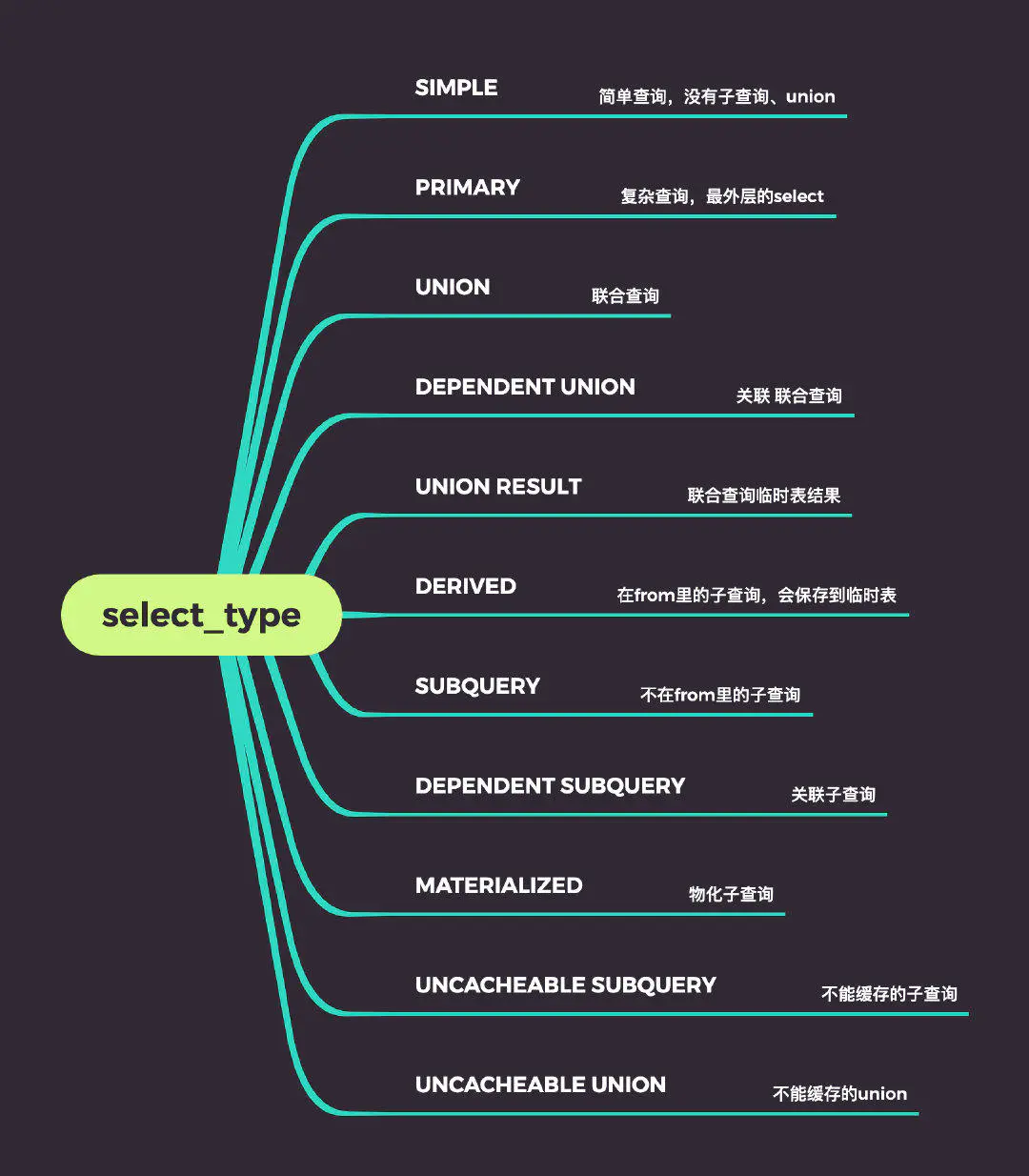
SIMPLE
简单查询,代表没有子查询或者union。
PRIMARY
如果不是简单查询,那么最外层查询就会被标记成PRIMARY。
UNION&UNION RESULT
从上图可以看出来了,包含联合查询,第一个被标记成了PRIMARY,union之后的查询被标记成UNION,以及最后产生的UNION RESULT
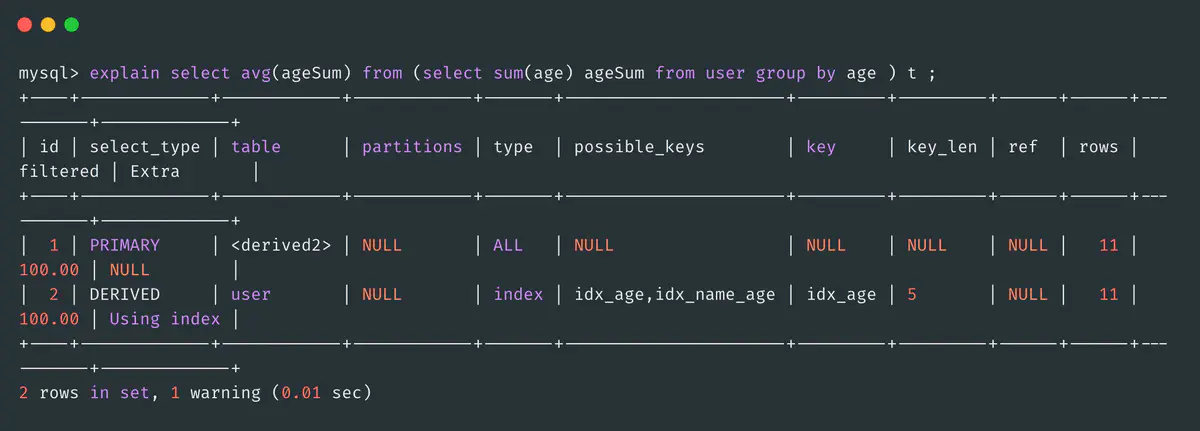
DERIVED
用来标记出现在from里的子查询,这个结果会放入临时表中,也叫做派生表。

这个对于低版本的Mysql可能显示是这样的,高一点可能你看到的还是PRIMARY,因为被Mysql优化了。我换一个版本的Mysql和SQL执行可以验证到这个结果。
SUBQUERY
不在from里的子查询。

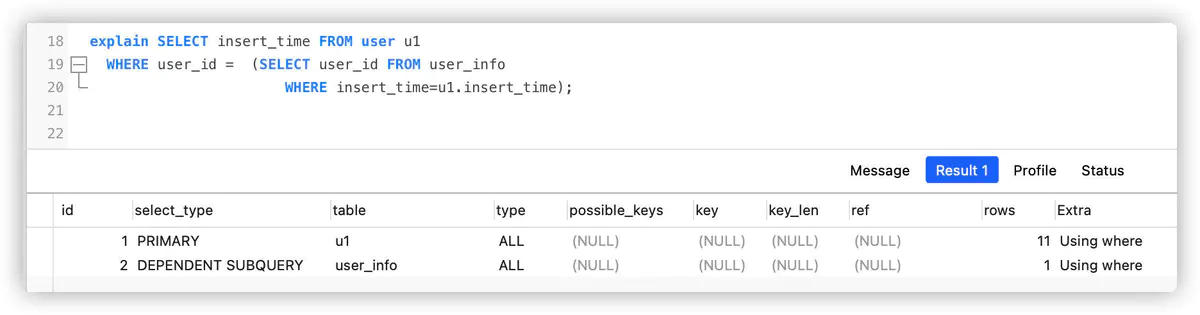
DEPENDENT
代表关联子查询(子查询使用了外部查询包含的列),和UNION,SUBQUERY组合产生不同的结果。
UNCACHEABLE
代表不能缓存的子查询,也可以和UNION,SUBQUERY组合产生不同的结果。

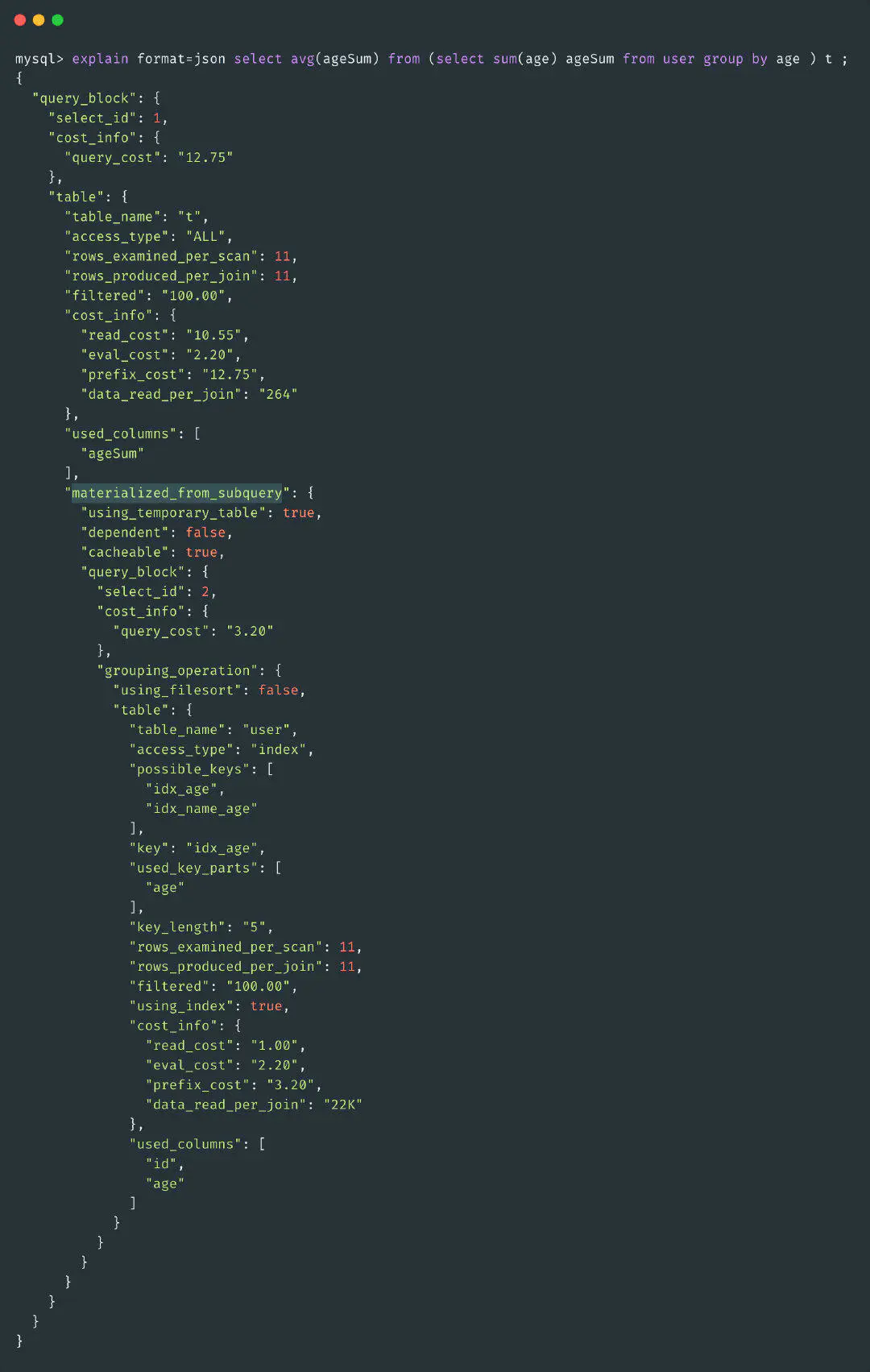
MATERIALIZED
物化子查询是Mysql对子查询的优化,第一次执行子查询时会将结果保存到临时表,物化子查询只需要执行一次。
比如上述DERIVED就是物化的一种体现,与之对应的就是DEPENDENT,每次子查询都需要重新调用。
这个结果无法直观的看出来,可以用FORMAT=JSON命令查看materialized_from_subquery字段。
table
显示表名,从上述的一些图中可以观察到UNION_RESULT和DERIVED显示的表名都有一些自己的命名规则。
比如UNION_RESULT产生的是<unionM,N>,DERIVED产生的是<derivedN>。
partitions
数据的分区信息,没有分区忽略就好了。
type
关联类型,决定通过什么方式找到每一行数据。以下按照速度由快到慢。
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL。

system&const
这通常是最快的查找方式,代表Mysql通过优化最终转换成常量查询,最常规的做法就是直接通过主键或者唯一索引查询。
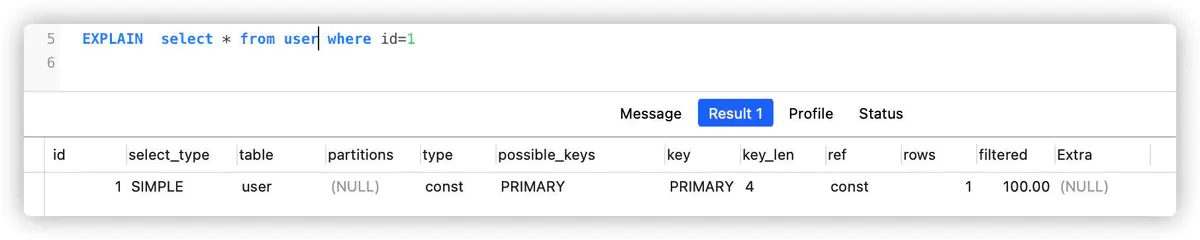
而system是const的一个特例(只有一行数据的系统表),随便找一张系统表,就插入一条数据就可以看到system了。

eq_ref
通常通过主键索引或者唯一索引查询时会看到eq_ref,它最多只返回一条数据。user_id是唯一索引,为了测试就关联以下主键索引。

ref
也是通过索引查找,但是和eq_ref不同,ref可能匹配到多条符合条件的数据,比如最左前缀匹配或者不是主键和唯一索引。
最简单的办法,随便查一个普通索引就可以看到。

fulltext
使用FULLTEXT索引
ref_or_null
和ref类似,但是还要进行一次查询找到NULL的数据。
这相当于是对于IS NULL查询的优化,如果表数据量太少的话,你或许能看到这里类型是全表扫描。

index_merge
索引合并是在Mysql5.1之后引入的,就像下面的一个OR查询,按照原来的想法要么用name的索引,要么就是用age的索引,有了索引合并就不一样了。
对于这种单表查询(无法跨表合并)用到了多个索引的情况,每个索引都可能返回一个结果,Mysql会对结果进行取并集、交集,这就是索引合并了。

unique_subquery
按照官方文档所说,unique_subquery只是eq_ref的一个特例,对于下图中这种in的语句查询会出现以提高查询效率。
由于Mysql会对select进行优化,基本无法出现这个场景,只能用update这种语句了。

index_subquery
和unique_subquery类似,只是针对的是非唯一索引。

range
看名字就知道,范围查询,其实就是带有限制条件的索引扫描。
常见的范围查询比如between and,>,<,like,in 都有可能出现range。

index
跟全表扫描类似,只是扫表是按照索引顺序进行。
ALL
全表扫描,没啥好说的。
possible_keys
可以使用哪些索引。
key
实际决定使用哪个索引。
key_len
索引字段的可能最大长度,不是表中实际数据使用的长度。
ref
表示key展示的索引实际使用的列或者常量。
rows
查询数据需要读取的行数,只是一个预估的数值,但是能很直观的看出SQL的优劣了。
filtered
5.1版本之后新增字段,表示针对符合查询条件的记录数的百分比估算,用rows和filtered相乘可以计算出关联表的行数。
Extra
解析查询的附加额外信息,这个太多了,有兴趣可以自己看官方文档,只列举一些常见的。
Using index
使用覆盖索引。
Using index condition
使用索引下推,索引下推简单来说就是加上了条件筛选,减少了回表的操作。

Using temporary
排序使用了临时表。
Using filesort
使用外部索引文件排序,但是不能从这里看出是内存还是磁盘排序,我们只能知道更消耗性能。
Using where
where过滤,没啥好说的。
Zero limit
除非你写个LIMIT 0。
Using sort_union(), Using union(), sing intersect()
使用了索引合并,参看上文。
总结
作者:艾小仙人
链接:https://www.jianshu.com/p/32e41daed5b2
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。