Strom安装
Strom启动
./zkServer.sh start
启动nimbus主节点: nohup bin/storm nimbus >> /dev/null &
启动supervisor从节点: nohup bin/storm supervisor >> /dev/null &
都启动完毕之后,启动strom ui管理界面: bin/storm ui &
使用了drpc,要启动drpc: nohup bin/storm drpc &
Storm简介
- 低延迟。高性能。可扩展。
- 分布式。系统都是为应用场景而生的,如果你的应用场景、你的数据和计算单机就能搞定,那么不用考虑这些复杂的问题了。我们所说的是单机搞不定的情况。
- 容错。一个节点挂了不影响应用。
实现一个实时计算系统。如果仅仅需要解决这5个问题,可能会有无数种方案,使用消息队列+分布在各个机器上的工作进程不就ok啦?
- 容易在上面开发应用程序。设计的系统需要应用程序开发人员考虑各个处理组件的分布、消息的传递吗?那就有点麻烦啊,开发人员可能会用不好,也不会想去用。
- 消息不丢失。用户发布的一个宝贝消息不能在实时处理的时候给丢了;更严格一点,如果是一个精确数据统计的应用,那么它处理的消息要不多不少才行。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 消息严格有序。有些消息之间是有强相关性的,比如同一个宝贝的更新和删除操作消息,如果处理时搞乱顺序完全是不一样的效果了。
- 快速。系统的设计保证了消息能得到快速的处理,使用ZeroMQ作为其底层消息队列。
Storm的架构、基本概念
-
Nimbus:主节点,负责资源分配和任务调度。
-
Supervisor:每个工作节点都运行了一个名为“Supervisor”的守护进程,负责接收nimbus分配的任务,启动和停止自己管理的N个worker进程。
-
Worker:运行具体处理组件逻辑的进程。一个Worker对应一个Topo,conf.setNumWorkers(2); 一个worker对应一个端口对应一个JVM进程!不是对应一台机器!
-
Topology:storm中运行的一个实时应用程序(相当于MR),(Spout + Bolt = Topo = Component,Spout,Bolt的名字就是ComponentId)形成有向图。点是计算节点,边是数据流。
-
Executor执行线程:就是setBolt制定的那个数字!!用来设置线程数。
-
Task:task不与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程executor。代表最大并发度。用来设置要执行的task数目,处理逻辑的数目。
-
Spout:Topology中的数据流源头。通常情况下spout会从外部数据源中读取数据,然后转换为Topology内部的源数据,然后封装成Tuple形式,之后发送到Stream中,Bolt再接收任意多个输入stream, 作一些业务处理。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
-
Bolt:一个Topology中接受数据然后执行处理的逻辑处理组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数。
-
Tuple:Bolt之间一次消息传递的基本单元:有序元素的列表。通常建模为一组逗号分隔的值,所以就是一个value list。
-
Stream:tuple的序列流。
Storm分组机制
Stream Grouping 定义了一个流在Bolt Task间该如何被切分进行接收,由接收数据的bolt来设置。
Bolt在多线程下有7种类型的stream grouping ,单线程下都是All Grouping:
-
Shuffle Grouping(随机分组): 随机派发stream里面的tuple, 保证Bolt的每个Task接收到的tuple数目相同平均分配。(Spout 100条,Bolt的两个Task每个获得50条Tuple)
-
Fields Grouping(按字段分组): 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
作用:(1)过滤多输出Field中选择某些Field;去重操作,Join。
(2)相同的tuple会分给同一个Task处理,比如WordCount,相同的单词给同一个Task统计才能准确,而使用Shuffle Grouping就不行!! -
Non Grouping (不分组):不关心到底谁会收到它的tuple。这种分组和Shuffle grouping是一样的效果,不平均分配。
-
LocalOrShuffleGrouping:如果目标Bolt中的一个或者多个Task和当前产生数据的Task在同一个Worker进程里面,那么就走内部的线程间通信,将Tuple直接发给在当前Worker进程的目的Task。否则,同shuffleGrouping。该方式数据传输性能优于shuffleGrouping,因为在Worker内部传输,只需要通过Disruptor队列就可以完成,没有网络开销和序列化开销。因此在数据处理的复杂度不高,而网络开销和序列化开销占主要地位的情况下,可以优先使用localOrShuffleGrouping来代替shuffleGrouping。
-
DirectGrouping :这种方式发送者可以指定下游的哪个Task可以接收这个元组。只有在数据流被声明为直接数据流时才能够使用直接分组方式。使用直接数据流发送元组需要使用 OutputCollector 的 emitDirect 方法。Bolt 可以通过 TopologyContext 来获取它的下游消费者的任务 id,也可以通过跟踪 OutputCollector 的 emit 方法(该方法会返回它所发送元组的目标任务的 id)的数据来获取任务 id。
-
All Grouping (广播发送): 对于每一个tuple, 所有的Bolts都会收到。(Spout 100条,两个Bolt每个获得100条Tuple,一共200条)
-
Global Grouping (全局分组): tuple被分配到一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
并发度相关概念
Executor数代表实际并发数(worker进程中的线程数),这样设置一个并发数:setBolt(xx, xx, 1);。
Task数代表最大并发度,是具体的处理逻辑实例,这样设置2个task:setBolt(xx, xx, 1).setTask(2);
这样就两个task共享一个executor线程,互相抢executor线程来执行bolt的execute方法。
通过storm rebalance命令:一个component的task数是不会改变的, 但是一个componet的executer数目是会发生变化的。
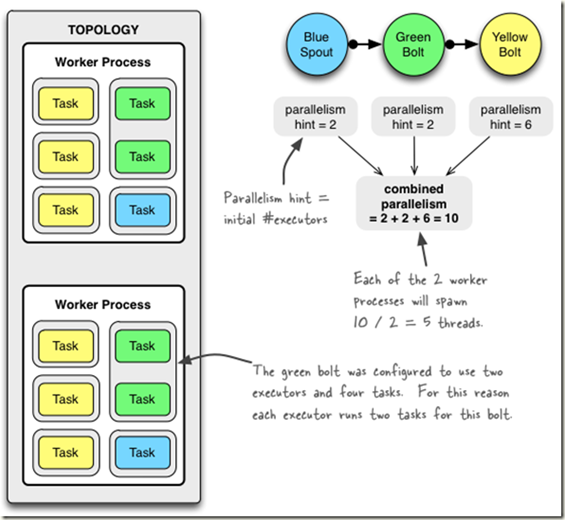
看看下面的例子:
Config conf = new Config();
// 2个进程
conf.setNumWorkers(2);
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
通过setBolt和setSpout一共定义 2 + 2 + 6 = 10个 executor threads;
前面 setNumWorkers 设置2个workers, 所以storm会平均在每个worker上run 5个executors !!!!
而对于green-bolt, 定义了4个tasks, 所以每个executor中有2个tasks。