http 传输原理及格式 - friping - ITeye技术网站 - Google Chrome (2013/4/1 14:02:36)
HTTP是Web协议集中的重要协议,它是从客户机/服务器模型发展起来的。客户机/服务器是运行一对相互通信的程序,客户与服务器连接时,首先,向服务器提出请求,服务器根据客户的请求,完成处理并给出响应。浏览器就是与Web服务器产生连接的客户端程序,它的端口为TCP的80端口。举一个大家都很常见的例子,浏览器与Web服务器之间所遵循的协议就是HTTP。
Web的应用层协议HTTP是Web的核心。HTTP在Web的客户程序和服务器程序中得以实现。运行在不同端系统上的客户程序和服务器程序通过交换HTTP消息彼此交流。HTTP定义这些消息的结构以及客户和服务器如何交换这些消息。HTTP定义Web客户(即浏览器)如何从web服务器请求Web页面,以及服务器如何把Web页面传送给客户。
HTTP协议的优点就是可以解决传输数据的准确性、安全性较高、而且有处理网络拥塞的能力。这主要的原因就是HTTP协议传输数据的时候,是由HTTP都把TCP作为底层的传输协议。HTTP客户首先发起建立与服务器TCP连接。一旦建立连接,浏览器进程和服务器进程就可以通过各自的套接字来访问TCP。如前所述,客户端套接字是客户进程和TCP连接之间的“门”,服务器端套接字是服务器进程和同一TCP连接之间的门。客户往自己的套接字发送HTTP请求消息,也从自己的套接字接收HTTP响应消息。类似的,服务器从自己的套接字接收HTTP请求消息,也往自己的套接字发送HTTP响应消息。客户或服务器一旦把某个消息送入各自的套接字,这个消息就完全落入TCP的控制之中。
TCP给HTTP提供一个可靠的数据传输服务;这意味着由客户发出的每个HTTP请求消息最终将无损地到达服务器,由服务器发出的每个HTTP响应消息最终也将无损地到达客户。我们可从中看到分层网络体系结构的一个明显优势——HTTP不必担心数据会丢失,也无需关心TCP如何从数据的丢失和错序中恢复出来的细节。HTTP/1.1服务器端处理请求时按照收到的顺序进行,这就保证了传输的正确性。当然,服务器端在发生连接中断时,会自动的重传请求,保证数据的完整性。
值得注意的是HTTP协议的建立连接方式也非常特别,在早先的HTTP/1.0版本中使用的是非持久连接,而到了HTTP/1.1时非持久连接和持久连接都被支持,但默认使用持久连接。在此要说明非持久连接大概的过程是,举一个浏览网页的例子。首先客户由与TCP连接相关联的本地套接字发出—个HTTP请求消息;其次,服务器接受请求并且经由同一个套接字发送响应消息;然后HTTP服务器告知TCP关闭这个TCP连接(不过TCP要到客户收到刚才这个响应消息之后才会真正终止这个连接);这时HTTP客户经由同一个套接字接收这个响应消息后,TCP连接随后终止。该消息明确标明所封装的对象是一个什么样的文件。客户从中取出这个文件,加以分析后发现其中的真正内容的引用。然后再对这些内容申请连接,最后浏览器就可以显示出网页的内容了,假如网页的内容是由5幅图片组成的那么完成对网页的浏览就需要有6次TCP的连接,这是HTTP/1.0版本的做法。
在HTTP/1.1中,在持久连接情况下,服务器在发出响应后让TCP连接继续打开着。同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。整个Web页面(上例中为包含一个基本HTML文件和5个图像的页面)可以通过单个持久TCP连接发送,甚至存放在同一个服务器中的多个web页面也可以通过单个持久TCP连接发送。通常,HTTP服务器在某个连接闲置一段特定时间后关闭它,而这段时间通常是可以配置的。持久连接分为不带流水线(without pipelining)和带流水线(with pipelining)两个版本。如果是不带流水线的版本,那么客户只在收到前一个请求的响应后才发出新的请求。这种情况下,web页面所引用的每个对象(上例中的5个图像)都经历1个RTT的延迟,用于请求和接收该对象。与非持久连接2个RTT的延迟相比,不带流水线的持久连接已有所改善,不过带流水线的持久连接还能进一步降低响应延迟。不带流水线版本的另一个缺点是,服务器送出一个对象后开始等待下一个请求,而这个新请求却不能马上到达。这段时间服务器资源便闲置了。HTTP/1.1的默认模式使用带流水线的持久连接。这种情况下,HTTP客户每碰到一个引用就立即发出一个请求,因而HTTP客户可以一个接一个紧挨着发出各个引用对象的请求。服务器收到这些请求后,也可以一个接一个紧挨着发出各个对象。如果所有的请求和响应都是紧挨着发送的,那么所有引用到的对象一共只经历1个RTT的延迟(而不是像不带流水线的版本那样,每个引用到的对象都各有1个RTT的延迟)。另外,带流水线的持久连接中服务器空等请求的时间比较少。与非持久连接相比,持久连接(不论是否带流水线)除降低了1个RTT的响应延迟外,缓启动延迟也比较小。其原因在于既然各个对象使用同一个TCP连接,服务器发出第一个对象后就不必再以一开始的缓慢速率发送后续对象。相反,服务器可以按照第一个对象发送完毕时的速率开始发送下一个对象。
从上面的例子不难看出,非持久连接中用户的点击导致浏览器发起建立一个与Web服务器的TCP连接,这里涉及一个三次握手的过程:首先是客户向服务器发送一个小的冗余消息,接着是服务器向客户确认并响应一个小的TCP消息,最后是客户向服务器回确认。三次握手过程的前两次结束时,流逝的时间为1个RTT。此时客户把HTTP请求消息发送到TCP连接中,客户接着把三次握手过程最后一次中的确认捎带,在包含这个消息的数据分节中发送出去。服务器收到来自TCP连接的请求消息后,把相应的HTML文件发送到TCP连接中,服务器接着把对早先收到的客户请求的确认捎带在包含该HTML文件的数据分节中发送出去。这个HTTP请求顺应交互也花去1个RTT时间。很容易就能看出持久连接在时间损耗上的优势了。
另外一个非常重要的地方就是HTTP协议的请求头以及响应头的格式。如果不清楚请求头的格式就无法向服务器端准确地发送下载请求;同时响应头的获得信息,对下载工具下一步的处理也至关重要。下面列出HTTP请求消息:
GET/somedir/page.htmlHTTP/1.1
Host:www.hhit.edu.cn
Connection:close
User-agent:Mozilla/4.0
Accept-language:zh-cn
(额外的回车符和换行符)
首先,这个消息是用普通的ASCII文本书写的。其次,这个消息共有5行(每行以一个回车符和一个换行符结束),最后一行后面还有额外的一个回车和换行符。当然,一个请求消息可以不止这么多行,也可以仅仅只有一行。该请求消息的第一行称为请求行(request line),后续各行都称为头部行(header)。请求行有3个字段:方法字段、URL字段、HTTP版本字段。方法字段有若干个值可供选择,包括GET、POST和HEAD。HTTP请求消息绝大多数使用GET方法,这是浏览器用来请求对象的方法,所请求的对象就在URL字段中标识。本例中浏览器实现的是HTTP/1.1版本。
上面例子中的请求消息有四行他们的意思分别是:
头部行Host:www.hhit.edu.cn存放所请求对象的主机。
请求消息中包含头部Connection:close是在告知服务器本浏览器不想使用持久连接;服务器发出所请求的对象后应关闭连接。尽管产生这个请求消息的浏览器实现的是HTTP/1.1版本,它还是不想使用持久连接。
User-agent头部行指定用户代理,也就是产生当前请求的浏览器的类型。本例的用户代理是Mozilla/4.0,它是Nelscape浏览器的一个版本。这个头部行很有用,因为服务器实际上可以给不同类型的用户代理发送同一个对象的不同版本(这些不同版本位用同一个URL寻址)。
最后,Accept-languag:头部行指出要是所请求对象有简体中文版本,那么用户宁愿接收这个版本;如果没有这个语言版本,那么服务器应该发送其默认版本。Accept-languag:仅仅是HTTP的众多内容协商头部之一。
HTTP协议请求消息的一般格式如图:

图 HTTP协议的请求信息格式
值得注意的是在请求消息的最后是附属体,在我们给出的例子中并没有这一项。是因为,附属体不在GET方法中使用,而是在POST方法中使用。POST方法适用于需由用户填写表单的场合,如往google搜索引擎中填入待搜索的词。用户提交表单后,浏览器就像用户点击了超链接那样仍然从服务器请求一个Web页面,不过该页面的具体内容却取决于用户填写在表单各个字段中的值。如果浏览器使用POST方法提出该请求,那么请求消息附属体中包含的是用户填写在表单各个字段中的值。
HTTP协议的响应消息和请求消息有所不同,下面是一个典型的响应消息:
HTTP/1.1 200 OK
Connection:close
Date:Thu,13Oct200503:17:33GMT
Server:Apache/2.0.54(Unix)
Last-Modified:Mon,22Jun199809;23;24GMT
Content-Length:682l
Content-Type:text/html
(数据数据数据数据数据…………)
这个响应消息分为3部分:1个起始的状态行(Status Line),6个头部行、1个包含所请求对象本身的附属体。状态行有3个字段:协议版本字段、状态码字段、原因短语字段。本例的状态行表明,服务器使用HTTP/1.1版本,状态码(Status Codes)200表示响应过程完全正常(也就是说服务器找到了所请求的对象,并正在发送)。
在上面的响应消息中头部行的意思分别是:
服务器使用Connection:close头部行告知客户自己将在发送完本消息后关闭TCP连接。
Date头部行:指出服务器创建并发送本响应消息的日期和时间。注意,这并不是对象本身的创建时间或最后修改时间,而是服务器把该对象从其文件系统中取出,插入响应消息中发送出去的时间。
Server头部行:指出本消息是由Apache服务器产生的;它与HTTP请求消息中的User-agent头部行类似。
Last-Modified头部行:指出对象本身的创建或最后修改日期或时间。Last-Modified头部对于对象的高速缓存至关重要,且不论这种高速缓存是发生在本地客户主机上还是发生在网络高速缓存服务器主机(也就是代理服务器主机)上。
Content-Length头部行:指出所发送对象的字节数。
Content-Type头部行:指出包含在附属体中的对象是HTML文本。对象的类型是由Content—Type头部而不是由文件扩展名正式指出的。
HTTP响应消息格式如图:
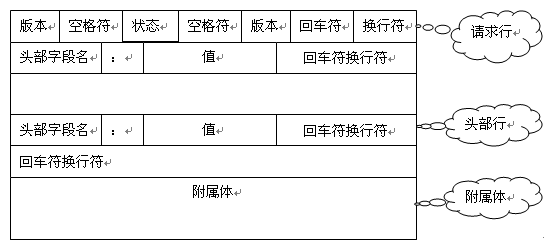
图 HTTP协议的响应信息格式

图 完整的HTTP请求响应内容
在响应消息中的状态行明显多出了明显多出了状态码(Status Codes)和原因短语,是因为在请求的信息可能存在着很多情况需要区分开,这样也便于用户能够清楚地知道请求的情况以及出错的原因,响应消息中的状态码和原因短语指示相应请求的处理结果。当服务器响应时,其状态行的信息为HTTP的版本号,状态码,及解释状态码的简单说明。现将5类状态码详细列出:
1XX客户方错误
100 继续
101 交换协议
2XX成功
200 OK
201 已创建
202 接收
203 非认证信息
204 无内容
205 重置内容
206 部分内容
3XX重定向
300 多路选择
301 永久转移
302 暂时转移
303 参见其它
304 未修改(Not Modified)
305 使用代理
4XX客户方错误
400 错误请求(Bad Request)
401 未认证
402 需要付费
403 禁止(Forbidden)
404 未找到(Not Found)
405 方法不允许
406 不接受
407 需要代理认证
408 请求超时
409 冲突
410 失败
411 需要长度
412 条件失败
413 请求实体太大
414 请求URL太长
415 不支持媒体类型
5XX服务器错误
500 服务器内部错误
501 未实现(Not Implemented)
502 网关失败
504 网关超时
505 HTTP版本不支持
测量程序的运行时间 - 蒋文专栏 - 博客频道 - CSDN.NET - Google Chrome (2013/3/29 14:18:04)
要精确测量程序的运行时间非常困难,主要因为:
1. concurrent:OS并发运行多个process,在这些process间进行切换
2. 运行时间受到各种计算机环境的影响:如Cache的命中率
两种测量机制:
1. 基于外部时钟(Interval Counting)
计算机硬件中有一个external timer,其主要作用就是每个一定时间(通常设置为1-10 ms间某个数),向CPU发送中断信号。CPU接收到该中断信号后,立即执行相应的中断处理程序。此时OS进入kernel mode,运行系统代码,查看是否应该进行进程切换。利用这个external timer,OS可以为每个进程记录其所消耗的时间。
具体工作方式:
当timer中断后,OS查看在中断之前是哪个process在运行,就把一次中断间隔时间算在这个process的账上。对每一个process所花时间,实际上细分为user time和system time,user time表示执行用户程序所用时间,system time表示执行内核系统代码所用时间,OS根据所在的mode(user mode和kernel mode)来区分。
如何使用Interval Counting来计时:
第一,Linux下的time命令
该命令可以返回某个程序的运行时间的具体参数。
第二,C standard library <time.h>中clock函数
clock_t clock(void);
该函数返回当前进程到目前为止所使用的clock数。
测量时间的方法:
- clock_t beg = clock();
- // 待测量时间的代码
- clock_t end = clock();
- double seconds = (double) (end - beg) / CLOCKS_PER_SEC;
准确性:这种方法最多能识别到interval 级别(10ms左右),而且由于其实在中断时将这个interval全记录到前一刻的运行的那个process上,所以会造出误差,但当运行时间较长时,这种误差可相互抵消。因此,基于外部时钟的方法,适用于运行时间 > 1s 的情况,此时可以测得比较准确的数据。
2. 基于CPU时钟周期(Cycle Counters)
有些硬件CPU内部有一个寄存器专用于存放系统到目前为止运行了多少个CPU时钟周期。如interl 的IA32体系结构中有一个64位的寄存器用于该目的。使用该寄存器可以测量程序运行的CPU时钟周期数,进而算出运行时间。
问题:
和具体硬件相关,有可能一些硬件没有这样的寄存器,即使有,也要使用硬件相关的汇编语言来读取该寄存器。
该寄存器并不是和process相关,而是全部程序公用的,那么进程切换怎么办?
因此,Cycle Counter方法比较适用于程序运行时间较短的情况,理想情况下 < 10ms最准确,因为此时进行进程切换的可能性较低。
如何使用:
第一,使用gettimeofday函数(POSIX标准),注意其底层到底是使用什么方式(Interval Counting还是Cycle Counters)取决于具体的系统(硬件和OS)。
代码参考Computer Systems ---- A programmer's perspective first edtion 官网下载的code中: code/perf/tod.c
第二,使用汇编语言直接访问底层硬件,前提是硬件支持。
IA32平台下代码参考Computer Systems ---- A programmer's perspective first edtion 官网下载的code中: code/perf/clock.c
The K-Best Measurement Scheme:用于修正Cycle Counter方法中产生的误差。具体参考Computer Systems ---- A programmer's perspective first edtion 9.4.3 节。
如何消除Cache的影响:按程序要运行的实际环境来模拟。若该程序在实际情况下经常访问新的数据,则可以写程序将Cache先清空;反之亦然。注意Cache有两种,用于指令的cache和用于数据的cache。
总结:
1. 如果程序运行时间 大于1s,则采用interval counting就可以取得比较精确数据。
2. 如果程序运行时间小于10ms,则采用cycle counters可以获取非常精确的数据,即使测试的时候系统负载很重(很多进程同时运行)。采用 K-Best Measurement Scheme,底层使用cycle counters。
3. 如果运行时间介于 10ms和1s之间,则想要获取准确时间必须非常小心:采用 K-Best Measurement Scheme,底层使用cycle counters;同时测试的时候系统必须负载很轻(lightly loaded)。
Bloom filter (C) - LiteratePrograms - Google Chrome (2013/3/26 14:41:44)
Bloom filter (C)
This program is a code dump.
Code dumps are articles with little or no documentation or rearrangement of code. Please help to turn it into a literate program. Also make sure that the source of this code does consent to release it under the MIT or public domain license.
This is an implementation of a Bloom filter in C.
typedef unsigned int(*hashfunc_t)(
const char*);
typedef struct{size_tasize;
unsigned char*a;size_tnfuncs;hashfunc_t*funcs;}BLOOM;BLOOM*bloom_create(size_tsize
,size_tnfuncs
, ...);
intbloom_destroy(BLOOM*bloom);
intbloom_add(BLOOM*bloom
, const char*s);
intbloom_check(BLOOM*bloom
, const char*s);#endif
<<bloom.c>>=#include<limits.h>#include<stdarg.h>#include"bloom.h"#define SETBIT(a, n) (a[n/CHAR_BIT] |= (1<<(n%CHAR_BIT)))#define GETBIT(a, n) (a[n/CHAR_BIT] & (1<<(n%CHAR_BIT)))BLOOM*bloom_create(size_tsize
,size_tnfuncs
, ...){BLOOM*bloom;va_listl;
intn;
if(!(bloom=malloc(
sizeof(BLOOM))))
returnNULL;
if(!(bloom->a=calloc((size+CHAR_BIT-1)
/CHAR_BIT
, sizeof(
char)))){free(bloom);
returnNULL;}
if(!(bloom->funcs=(hashfunc_t*)malloc(nfuncs*
sizeof(hashfunc_t)))){free(bloom->a);free(bloom);
returnNULL;}va_start(l
,nfuncs);
for(n=0;n<nfuncs;++n){bloom->funcs[n]=va_arg(l
,hashfunc_t);}va_end(l);bloom->nfuncs=nfuncs;bloom->asize=size;
returnbloom;}
intbloom_destroy(BLOOM*bloom){free(bloom->a);free(bloom->funcs);free(bloom);
return0;}
intbloom_add(BLOOM*bloom
, const char*s){size_tn;
for(n=0;n<bloom->nfuncs;++n){SETBIT(bloom->a
,bloom->funcs[n](s)%bloom->asize);}
return0;}
intbloom_check(BLOOM*bloom
, const char*s){size_tn;
for(n=0;n<bloom->nfuncs;++n){
if(!(GETBIT(bloom->a
,bloom->funcs[n](s)%bloom->asize)))
return0;}
return1;}
<<test.c>>=#include<stdio.h>#include<string.h>#include"bloom.h"
unsigned intsax_hash(
const char*key){
unsigned inth=0;
while(*key)h
^=(h
<<5)+(h>>2)+(
unsigned char)*key++;
returnh;}
unsigned intsdbm_hash(
const char*key){
unsigned inth=0;
while(*key)h=(
unsigned char)*key+++(h<<6)+(h<<16)-h;
returnh;}
intmain(
intargc
, char*argv[]){FILE*fp;
charline[1024];
char*p;BLOOM*bloom;
if(argc<2){fprintf(stderr
,"ERROR: No word file specified ");
returnEXIT_FAILURE;}
if(!(bloom=bloom_create(2500000
,2
,sax_hash
,sdbm_hash))){fprintf(stderr
,"ERROR: Could not create bloom filter ");
returnEXIT_FAILURE;}
if(!(fp=fopen(argv[1]
,"r"))){fprintf(stderr
,"ERROR: Could not open file %s "
,argv[1]);
returnEXIT_FAILURE;}
while(fgets(line
,1024
,fp)){
if((p=strchr(line
,' ')))*p='�';
if((p=strchr(line
,' ')))*p='�';bloom_add(bloom
,line);}fclose(fp);
while(fgets(line
,1024
,stdin)){
if((p=strchr(line
,' ')))*p='�';
if((p=strchr(line
,' ')))*p='�';p=strtok(line
," ,.;: ?!-/()");
while(p){
if(!bloom_check(bloom
,p)){printf("No match for ford "%s" "
,p);}p=strtok(NULL
," ,.;: ?!-/()");}}bloom_destroy(bloom);
returnEXIT_SUCCESS;}
<<Makefile>>=all:
bloombloom:
bloom.o test.o cc -o bloom -Wall -pedantic bloom.o test.obloom.o:
bloom.c bloom.h cc -o bloom.o -Wall -pedantic -ansi -c bloom.ctest.o:
test.c bloom.h cc -o test.o -Wall -pedantic -ansi -c test.c
那些优雅的数据结构(1) : BloomFilter——大规模数据处理利器 - 苍梧 - 博客园 - Google Chrome (2013/3/26 14:06:31)
BloomFilter——大规模数据处理利器
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
一. 实例
为了说明Bloom Filter存在的重要意义,举一个实例:
假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
1. 将访问过的URL保存到数据库。
2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。
4. Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
方法4消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。
实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
二. Bloom Filter的算法
废话说到这里,下面引入本篇的主角——Bloom Filter。其实上面方法4的思想已经很接近Bloom Filter了。方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter使用了多个哈希函数,而不是一个。
Bloom Filter算法如下:
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(1) 加入字符串过程
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。

图1.Bloom Filter加入字符串过程
很简单吧?这样就将字符串str映射到BitSet中的k个二进制位了。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
(3) 删除字符串过程
字符串加入了就被不能删除了,因为删除会影响到其他字符串。实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
三. Bloom Filter参数选择
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
(2)Bit数组大小选择
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献1。该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
四. Bloom Filter实现代码
下面给出一个简单的Bloom Filter的Java实现代码:

publicclass BloomFilter
{
/* BitSet初始分配2^24个bit */
privatestaticfinalint DEFAULT_SIZE =1<<25;
/* 不同哈希函数的种子,一般应取质数 */
privatestaticfinalint[] seeds =newint[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits =new BitSet(DEFAULT_SIZE);
/* 哈希函数对象 */
private SimpleHash[] func =new SimpleHash[seeds.length];
public BloomFilter()
{
for (int i =0; i < seeds.length; i++)
{
func[i] =new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 将字符串标记到bits中
publicvoid add(String value)
{
for (SimpleHash f : func)
{
bits.set(f.hash(value), true);
}
}
//判断字符串是否已经被bits标记
publicboolean contains(String value)
{
if (value ==null)
{
returnfalse;
}
boolean ret =true;
for (SimpleHash f : func)
{
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/* 哈希函数类 */
publicstaticclass SimpleHash
{
privateint cap;
privateint seed;
public SimpleHash(int cap, int seed)
{
this.cap = cap;
this.seed = seed;
}
//hash函数,采用简单的加权和hash
publicint hash(String value)
{
int result =0;
int len = value.length();
for (int i =0; i < len; i++)
{
result = seed * result + value.charAt(i);
}
return (cap -1) & result;
}
}
}
参考文献:
[1]Pei Cao. Bloom Filters - the math.
http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html
[2]Wikipedia. Bloom filter.
快速URL排重的方法(一) - oyd的专栏 - 博客频道 - CSDN.NET - Google Chrome (2013/3/26 11:36:44)
快速URL排重的方法(一) - oyd的专栏 - 博客频道 - CSDN.NET - Google Chrome (2013/3/26 11:36:44)
我这里介绍一个极适合大量URL快速排重的方法 ,这个算法被称为Bloom filter,基本上,它也只适合这样的场合。
这里的大量是指有5000万至1亿的URL,更大的数据量可能也不合适了。
一开始我使用了一个最复杂的做法,是有一个单独的daemon程序负责排重,数据和排重结果通过socket传输。
后来发现不行,仅仅几百万数据要做好几个小时,5000万不把人都急疯了?至于daemon中具体用什么算法就次要了,因为一涉及到网络通讯,速度再快也被拉下来(这里针对的是发送一条记录/返回一条结果的模式,一次传送一批数据则与网络状况有关了)
所以,把目标锁定在单机排重,一开始,试验了perl中的hash,非常简单的代码
 use DB_File;my %db;#tie %db, 'DB_File', "createdb.dat", or die "Can't initialize db:: $!
";while(<>) { chomp $_; $db{$_} = 1;# add code here}#untie %db;
use DB_File;my %db;#tie %db, 'DB_File', "createdb.dat", or die "Can't initialize db:: $!
";while(<>) { chomp $_; $db{$_} = 1;# add code here}#untie %db;从标准输入或文件中每行一个URL读入,插入到perl内置的hash表中,这就成了,需要输出结果则预先判断一下插入的key是否存在。
这个方法速度很快,可惜的是,它占用内存太大,假设1个URL平均50字节,5000万个URL需要2.5G内存。
于是又想到一个方法,把部分数据放入硬盘空间,perl中也提供一个现成的模块DB_File,把上面代码中的注释去掉,就可使用DB_File了,用法与hash一样,只是内部用数据库实现的。
测试了一下,速度明显下降了一个档次,仅40万的数据就要1分钟,关键还在于随着数据量的增加,速度下降加快,两者不呈线性关系。
数据量大的时候,有可能用MySQL的性能会比DB_File好,但是总体上应该是一丘之貉,我已经不抱期望了。
也许DB_File可以优化一下,使用更多的内存和少量的硬盘空间,不过这个方案还是太复杂,留给专家解决吧,一般来说,我认为简单的方法才有可能做到高效。
下面我们的重点对象隆重登场:Bloom filter。简单的说是这样一种方法:在内存中开辟一块区域,对其中所有位置0,然后对数据做10种不同的hash,每个hash值对内存bit数求模,求模得到的数在内存对应的位上置1。置位之前会先判断是否已经置位,每次插入一个URL,只有当全部10个位都已经置1了才认为是重复的。
如果对上面这段话不太理解,可以换个简单的比喻:有10个桶,一个桶只能容纳1个球,每次往这些桶中扔两个球,如果两个桶都已经有球,才认为是重复,问问为了不重复总共能扔多少次球?
10次,是这个答案吧?每次扔1个球的话,也是10次。表面上看一次扔几个球没有区别,事实上一次两个球的情况下,重复概率比一次一个球要低。Bloom filter算法正式借助这一点,仅仅用少量的空间就可以进行大量URL的排重,并且使误判率极低。
有人宣称为每个URL分配两个字节就可以达到0冲突,我比较保守,为每个URL分配了4个字节,对于5000万的数量级,它只占用了100多M的空间,并且排重速度超快,一遍下来不到两分钟,极大得满足了我的欲望。
今天时间不够,下一篇再贴代码
快速URL排重的方法(二) - oyd的专栏 - 博客频道 - CSDN.NET - Google Chrome (2013/3/26 11:37:24)
接上篇,起初我为了输入输出方便,是用perl去实现的,后来发现perl中求模速度太慢,就改用C了
常量定义:SPACE指你要分配多大的内存空间,我这里是为5000万数据的每一条分配4字节
const int MAXNUM = SPACE * 8;
#define LINE_MAX 2048
int bits[] = {0x1, 0x2, 0x4, 0x8, 16, 32, 64, 128};
char* db = NULL;
主程序:这里循环读入标准输入的每一行,进行排重。
{
db = new char[SPACE];
memset(db, 0, SPACE);
char line[LINE_MAX];
while (fgets(line, LINE_MAX, stdin) != NULL) {
int len = strlen(line);
len--;
if (len <= 0) continue;
if (!is_exist(line, len)) {
// add code here
}
}
return 0;
}
判定函数:我没有做Bloom filter算法中描述的10次hash,而是做了一个MD5,一个SHA1,然后折合成9次hash。
unsigned int hashs[9];
unsigned char buf[20];
MD5(str, len, buf);
memcpy(hashs, buf, 16);
SHA1(str, len, buf);
memcpy(hashs + 4, buf, 20);
int k = 0;
for (int j = 0; j < sizeof(hashs) / sizeof(hashs[0]); j++) {
int bitnum = hashs[j] % MAXNUM;
int d = bitnum / 8;
int b = bitnum % 8;
char byte = db[d];
if (byte & bits[b] == bits[b]) {
} else {
byte |= bits[b];
db[d] = byte;
k++;
}
}
return (k == 0);
}
gcc 编译时添加 -lcrypto
主要算法就在这里了,实际应用的话可以采用循环监视磁盘文件的方法来读入排重数据,那些代码就与操作系统相关,没必要在这写了