这次花了4小时40分钟,看了第 559~575 页,共 17 页
第一遍对应地址 https://www.cnblogs.com/stone94/p/10264044.html
注意:本章的练习题一定要做,并且要在看到的时候立即做,这非常有助于理解刚学的小节的内容,继续往后看的时候,也不至于持续积累懵逼程度
关键术语及其英文表示:
记住这些对看懂本章有很大的帮助,或者把这些当做字典,看书时忘记某个英文缩写代表什么意思时,来看看也行
VM:虚拟内存
PA:物理地址
VA:虚拟地址
MMU:内存管理单元(在本章中可以看做地址翻译的代表)
VP:虚拟页
VPO:虚拟页面偏移量(字节)
VPN:虚拟页号
TLBI:TLB索引
TLBT:TLB标记
PTE:页表条目
PP:物理页
PPO:物理页面偏移量(字节)
CO:缓存块内的字节偏移量
CI:高速缓存索引
CT:高速缓存标记
什么是虚拟内存?它的作用是什么?
为了更加有效地管理内存并且少出错,现代系统提供了一种对主存的抽象概念,叫做虚拟内存(VM)。
虚拟内存是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的完美交互,它为每个进程提供了一个大的、一致的和私有的地址空间。通过一个很清晰的机制,虚拟内存提供了三个重要的能力:(1)它将主内看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效地使用了主存;(2)它为每个进程提供了一致的地址空间,从而简化了内存管理;(3)它保护了每个进程的地址空间不被其他进程破坏。
物理寻址

虚拟寻址
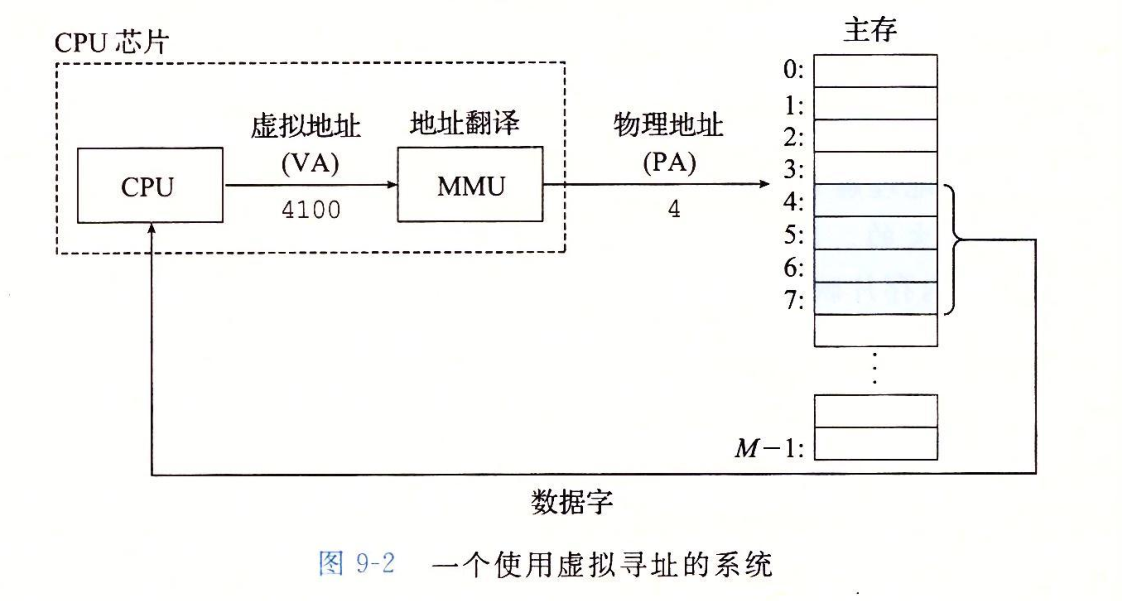
图 9-2 中,将虚拟地址(VA)翻译成物理地址(PA)的地址翻译工作,是由内存管理单元(MMU)负责的
页表
虚拟内存系统必须由某种方法来判定一个虚拟页是否缓存在 DRAM 中的某个地方。如果是,系统还必须确定这个虚拟页存放在哪个物理页中。如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理内存职工选择一个牺牲也,并将虚拟页从磁盘复制到 DRAM 中,替换这个牺牲也。
这些功能是由软硬件联合提供的,包括操作系统软件、MMU(内存管理单元)中的地址翻译硬件和一个存放在物理内存中叫做页表(page table, pgd)的数据结构,页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。操作系统负责维护页表的内容,以及在磁盘与 DRAM 之间来回传送页。
页表就是一个页表条目(Page Table Entry, PTE)的数组。

页命中
通过虚拟地址查询数据时,该数据正好被缓存在物理内存中(缓存命中),则直接返回相应数据
缺页
通过虚拟地址查询数据时,该数据没有被缓存在物理内存中(缓存不命中),此时,地址翻译硬件会触发一个缺页异常,缺页异常调用内核中的缺页处理程序,该程序会选择一个牺牲页(如果该牺牲页曾经被修改过,则会将其写回磁盘,持久化下来),将目标物理页复制到原来牺牲页的位置,接着异常程序处理结束,返回,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址发送到地址翻译硬件,此时,必然会导致一个页命中,返回相应数据给 CPU。
把 PTE 缓存在高速缓存中
尽管页表是虚拟内存使用的一个管理内存的工具,但是,页表本身也是数据,是数据,人们就会想到如何缓存它,以提高访问效率

图 9-14 中,
最坎坷的一条路:
VA → MMU → PTEA → PTEA不命中 → PTEA → 内存 → PTE → PTEA命中 → PTE → MMU → PA → PA不命中 → PA → 内存 → 数据 → PA命中 → 数据 → 处理器
最顺畅的一条路:
VA → MMU → PTEA → PTEA命中 → PTE → MMU → PA → PA命中 → 数据 → 处理器
把 PTE 缓存在 TLB 中
利用 TLB 加速地址翻译
如图 9-14 所示,每次 CPU 产生一个虚拟地址,MMU 就必须查阅一个 PTE,以便将虚拟地址翻译为物理地址。在最糟糕的情况下,这回要求从内存多取一次数据,代价是几十到几百个周期。如果 PTE 碰巧缓存在 L1 中,那么开销及下降到 1 个或 2 个周期。然而,许多系统都视图消除即使是这样的开销,它们在 MMU 中包括了一个关于 PTE 的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer, TLB)。
TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。
当 TLB 命中时,所有的翻译步骤都是在芯片上的 MMU 中执行的,因此非常快。

多级页表
我认为,多级页面的核心作用是用时间换空间。也就是说,其实多级页表比一级页表运行起来要慢,但是可以减轻内存的压力。
关于空间,见本小节(9.6.3 多级页表)的开头
“到目前为止,我们一直假设系统只用一个单独的页表来进行地址翻译。但是如果我们有一个 32 位的地址空间、4KB 的页面和一个 4 字节的 PTE,那么即使应用所引用的只是虚拟地址空间中很小的一部分,也总是需要一个 4MB 的页表驻留在内存中。对于地址空间为 64 位的系统来说,问题将变得更为复杂。”
算一些这笔账:
32位地址空间,即共有2^32个虚拟地址
每个页面(即页)4KB,即2^12
那么虚拟地址空间中共有2^32除以2^12,即2^20个页面(即页)
每个页都需要对应一个页表条目(即PTE),故页面条目的个数也是2^20
而每个 PTE 的大小是 4 字节,即2^2,那么2^20页表条目的总大小就是 2^22 字节了,即 4MB关于时间,见本小节的这两段:
“二级页表中的每个 PTE 都负责映射一个 4KB 的虚拟内存页面,就像我们查看只有一级的页表一样。注意,使用 4 字节的 PTE,每个一级和二级页表都是 4KB 字节,这刚好和一个页面的大小是一样的。
这种方法从这两个方面减少了内存要求。第一,如果一级页表中的一个 PTE 是空的,那么相应的二级页表就根本不会存在。这代表一种巨大的潜在节约,因为对于一个典型的程序,4GB 的虚拟地址空间的大部分都会使未分配的。第二,只有一级页表才需要总是在主存中;虚拟内存系统可以在需要时创建、页面调入或调出二级页面,这就减少了主存的压力;只有最经常使用的二级页表才需要缓存在主存中。”