第1章 压缩文件
1.1 tar压缩 zcvf C t x P
tar压缩
[root@oldboyedu-lnb ~]#tar zcvf hosts.tar.gz
z # 使用gzip方式压缩
c # create 创建压缩包
v # verbose 显示压缩的过程
f # 指定文件
x # 解压
t # 查看压缩包的文件名称
-C # 指定解压到哪里
-P # 不提示从成员中删除/
为什么要压缩
1.1.1 不常用的文件 占用磁盘空间
1.1.2 压缩后的文件 备份文件 传送到备份服务器
服务器-->传送文件到备份服务器--->每个文件传输都会占用1次IO请求
上千个文件-->备份服务器--->建立上千次的IO请求
上千个文件压缩成一个文件-->和服务器建立1次IO 大大降低了服务器的IO请求
1.1.3 什么时间压缩
压缩最耗费服务器的CPU
业务的低谷期进行压缩和传送数据
1.2 压缩其他的命令
zip bz bz2
# 提前安装zip命令 yum -y install zip
zip压缩:
|
-q |
不显示指令执行过程 |
|
-r |
递归处理,将指定目录下的所有文件和子目录一并处理 |
|
-z |
替压缩文件加上注释 |
|
-v |
显示指令执行过程或显示版本信息 |
|
-n<字尾字符串> |
不压缩具有特定字尾字符串的文件 |
/home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip:
[root@linuxcool ~]# zip -q -r html.zip /home/html 压缩文件 cp.zip 中删除文件 a.c: [root@linuxcool ~]# zip -dv cp.zip a.c 把/home目录下面的mydata目录压缩为mydata.zip: [root@linuxcool ~]# zip -r mydata.zip mydata 把/home目录下面的abc文件夹和123.txt压缩成为abc123.zip: [root@linuxcool ~]# zip -r abc123.zip abc 123.txt 将 logs目录打包成 log.zip: [root@linuxcool ~]# zip -r log.zip ./logs
gzip 压缩
语法格式:gzip [参数]
常用参数:
|
-a |
使用ASCII文字模式 |
|
-d |
解开压缩文件 |
|
-f |
强行压缩文件 |
|
-l |
列出压缩文件的相关信息 |
|
-c |
把压缩后的文件输出到标准输出设备,不去更动原始文件 |
|
-r |
递归处理,将指定目录下的所有文件及子目录一并处理 |
|
-q |
不显示警告信息 |
参考实例
把rancher-v2.2.0目录下的每个文件压缩成.gz文件:
[root@linuxcool ~]# gzip *
把上例中每个压缩的文件解压,并列出详细的信息:
[root@linuxcool ~]# gzip -dv *
递归地解压目录:
[root@linuxcool ~]# gzip -dr rancher.gz [root@oldboyedu-lnb ~]# zip zip.gz 1.txt 2.txt [root@oldboyedu-lnb opt]# unzip zip.gz # 常用 Archive: zip.gz inflating: 1.txt extracting: 2.txt
unzip 解压到指定的位置 -d
[root@oldboyedu-lnb ~]# zip test.zip 1.txt adding: 1.txt (deflated 36%) [root@oldboyedu-lnb ~]# unzip test.zip -d /opt/ Archive: test.zip inflating: /opt/1.txt [root@oldboyedu-lnb ~]# ll /opt/ total 4 -rw-r--r-- 1 root root 1177 Aug 4 08:02 1.txt
第2章 文件的权限
2.1 权限的作用 决定了用户对文件的使用权限
rwxr--r--
2.2 权限用来赋予给用户的
2.3 前三位 属主
中三位 属组
后三位 其他用户
2.4 rwx对应的数字
r 4
w 2
x 1
第3章 文件的属主
3.1 系统用户
作用:
登陆系统 管理数据 管理服务
3.2 系统识别用户
系统如何识别用户的: UID 用户唯一标识 类似于身份证 user dentification UID是一个数字
系统默认用户的分类:
用户 UID 作用
1.管理员用户: 0 最高管理者 相当于皇帝 拥有最高的权限 /root
[root@oldboyedu-lnb~]# id root
uid=0(root) gid=0(root) groups=0(root)
2.虚拟用户: 1-999 sshd虚拟用户 系统中每一个服务启动 都必须使用一个用户 不能登陆操作系统 没有家目录
[root@oldboyedu-lnb~]# id sshd
uid=74(sshd) gid=74(sshd) groups=74(sshd)
3.普通用户: 1000+ 登陆系统 维护系统 常用的系统用户 为了系统安全创建的用户
[root@oldboyedu-lnb~]# id oldboy
uid=1001(oldboy) gid=1001(oldboy) groups=1001(oldboy)
[root@oldboyedu-lnb~]# id alexdsx
id: alexdsx: no such user
[root@oldboyedu-lnb~]# id alex
uid=1002(alex) gid=1002(alex) groups=1002(alex)
3.3 文件的属组 了解
, 默认创建的用户 都会自动创建以自身名字命名的组名 oldboy用户--->创建了oldboy组
当前组内的成员 对文件或目录拥有什么权限
一个用户可以属于多个组 oldboy属于alex组 root组 test组....
多个用户可以属于1个组 oldboy alex lidao 用户---> 属于test组
多个用户可以属于多个组 oldboy--> alex lidao alex--> oldboy lidao
第4章 索引节点和块设备
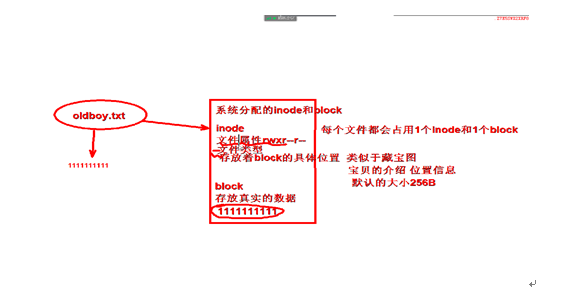
4.1 inode 和 block
在创建文件系统的时候自动生成的定量的inode和block
inode 索引节点 index node
特点:
类似于书的目录
相当于超市的入口
inode的查看方式 ls -li
inode定义: 存储文件的属性及block的具体位置
一个文件最少占用一个inode和1个block
一个inode可以被多个文件占用
在同一个文件系统中相同的inode号称为硬链接?
inode默认的大小256B
文件名在上级目录的block中
4.1.1 磁盘的使用过程:
磁盘 地皮
RAID 地皮组合在一起 统一规划
分区 写字楼 餐厅 游乐场 宿舍
格式化 打扫卫生 清理
创建文件系统 精装修 生成inode和block 中式 韩式 美式 欧式.... NTFS FAT32 XFS ext2 ext3 ext4
挂载 安装房间的门
4.2 block 快设备
特点:
存储文件数据的
创建文件最少需要一个1个inode和1个block
默认的block的大小是4K
文件太少、浪费磁盘空间 存储单位是按4K方式存储的
10K文件-->占用三个block
磁盘的读取按照block单位进行读取 读取1个block会占用1次IO
IO input output 输入输出的次数决定了磁盘的使用效率
读取1个block占用1s 读取10k--->占用三秒
4.2.1 查看inode和block
inode: ls -li
df -i 查看当前系统inode使用情况
block: df -h 查看的是block空间的总大小 扩展:如何查看默认的block大小 调整block大小
4.2.2 使用过程中磁盘无法存储内容
4.2.2.1 查看inode使用情况
什么情况下inode会被占满
1个文件最少占用1个inode 当有大量小文件的时候 inode会被占满
4.2.2.2 查看block使用情况
什么情况下block占满
文件太大 其中一个满 都无法正常存储内容
4.2.2.3 block快存储 大了好还是小了好
说明:10K 文件 block 4K 占用3个block
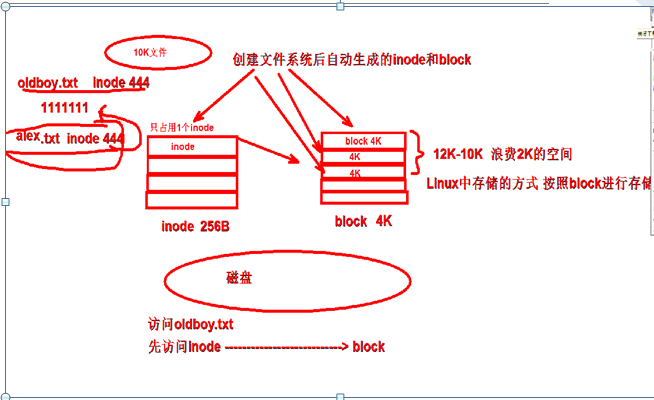
磁盘IO 输入输出的次数,决定了磁盘的性能
10M 消耗block少 IO次数少 硬盘性能没影响 10G 消耗block多 IO次数多 磁盘性能降低 大文件较多 视频/图片/音频 block调大一点 IO消耗较少 小文件较多 文档/网站代码 block小一些 节省磁盘空间
4.3 软链接和硬链接
硬链接:
在同一个文件系统中有相同的inode号的文件互为硬链接
硬链接 文件的多个入口 类似于超市有多个入口 堵死一个门不影响文件的正常使用
相当于复制多个inode号码
4.3.1 创建硬链接
ln 源文件 目标文件
[root@oldboyedu-lnb test]# ln test.txt hard_link.txt [root@oldboyedu-lnb test]# ll -i total 0 50996266 -rw-r--r-- 2 root root 0 Aug 4 10:35 hard_link.txt 50996266 -rw-r--r-- 2 root root 0 Aug 4 10:35 test.txt
4.3.2 硬链接的特点
1.对已存在的文件做硬链接 2.inode相同 属性相同 3.只能在同一个分区内进行创建 同一个文件系统 4.不能对目录创建硬链接,只能对文件创建硬链接 扩展了解 5.删除一个硬链接不影响其他的相同inode号的文件 6.目录的硬链接默认是2个 7.可以在任意一个入口进入到文件修改内容 查看文件的时候都会发生变 8.删除所有的相同的inode号 文件被真正的删除
4.3.3 硬链接的作用
提高系统的安全性
4.4 软链接
说明: 类似windows的快捷方式,软链接存放了指向源文件的指针
4.4.1 创建软链接:
ln -s 源文件 目标文件
[root@oldboy~/oldboy]#ll -rw-r--r--. 1 root root 5 5月 13 11:06 1.txt [root@oldboy~/oldboy]#ln -s 1.txt s_1.txt [root@oldboy~/oldboy]#ll 总用量 4 rw-r--r--. 1 root root 5 5月 13 11:06 1.txt lrwxrwxrwx. 1 root root 5 5月 13 11:07 s_1.txt -> 1.txt
4.4.2 软链接特点
1.软链接的inode和源文件不同 存放源文件的路径 指向源文件的实体 2.删除链接文件不影响源文件 3.删除源文件 链接文件存在,但是无法访问源文件的内容 红底白字进行闪烁 4.创建软链建 ln -s 5.创建的软链接就是普通文件 删除rm命令 PS:删除的是软链接 而不是--->file
4.4.3 软链接作用
1.可以利用软链接跨文件系统的方式 处理磁盘不够用 2.可以快速进行代码回滚 代码上线?
4.4.4 软链接和硬链接的区别
在Linux系统中 链接分为两种 一种是硬链接 hard link 另一种软链接(符号链接) symbllc link
1)创建方式不同 ln直接创建硬链接 ln -s 带s参数创建是软链接 2)硬链接的inode号码是相同的 软链接Inode是不同的 3)目录不能创建硬链接可以创建软链接 4)删除硬链接不影响源文件 5)删除文件的软链接源文件则导致软链接失效。如果删除软链接文件不影响源文件 6)同时删除源文件和硬链接的文件 整个文件才会被真正的删除(没有被系统调用情况),删除软链接的源文件,则文件被真正删除。 7)软链接可以跨文件系统,硬链接不可以跨文件系统 8)软链接在工作中常用 创建软链接 最好使用全路径(绝对路径)
[root@oldboyedu-lnb test]# ln -s /tmp/data /root/test/data
第5章 文件时间的修改
5.1 三个时间修改
Access:# 文件的访问时间 cat less more head tail第一次查看时间改变 如果文件没有被修改 则时间不会改变
Modify:# 文件的修改时间 内容被修改 时间会发生变化
[root@oldboyedu-lnb~]# echo test > oldboy.txt [root@oldboyedu-lnb~]# stat oldboy.txt File: ‘oldboy.txt’ Size: 5 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 34044702 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2020-08-04 23:23:16.784751936 +0800 Modify: 2020-08-04 23:24:15.392326380 +0800 Change: 2020-08-04 23:24:15.392326380 +0800
Change:# 文件的属性修改时间 文件属性变化 时间就会变化
[root@oldboyedu-lnb~]# chmod +x oldboy.txt [root@oldboyedu-lnb~]# stat oldboy.txt File: ‘oldboy.txt’ Size: 10 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 34307462 Links: 1 Access: (0755/-rwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2020-08-04 23:25:23.213991139 +0800 Modify: 2020-08-04 23:25:23.213991139 +0800 Change: 2020-08-04 23:32:49.386364313 +0800 Birth: - [root@oldboyedu-lnb~]# mv oldboy.txt oldboy.bak [root@oldboyedu-lnb~]# stat oldboy.bak File: ‘oldboy.bak’ Size: 10 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 34307462 Links: 1 Access: (0755/-rwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2020-08-04 23:25:23.213991139 +0800 Modify: 2020-08-04 23:25:23.213991139 +0800 Change: 2020-08-04 23:34:00.687063165 +0800 Birth: -
5.2 find按照时间查找文件
-mtime # 常用
-atime
-ctime
文件详细信息:
inode和block的存储过程 理解 系统如何找到/root/oldboy/test.txt
第一步:首先查找/目录, 查找/目录的inode号码 第二步:在/目录下的block位置找到root的目录名称 第三步:找到root对应的inode号码 第四步:root的inode号码指向了自己的block的位置,找到oldboy目录名称 第五步:找到oldboy对应的inode号码 第六步:oldboy的号码指向了自己的block的位置,里面存储的是test.txt 第七步:找到了test.txt文件 找到自身的inode号码,指向自身的block位置 第八步:通过block位置查看test.txt内容