InnoDB架构
下面的架构里只挑选了部分内容进行学习
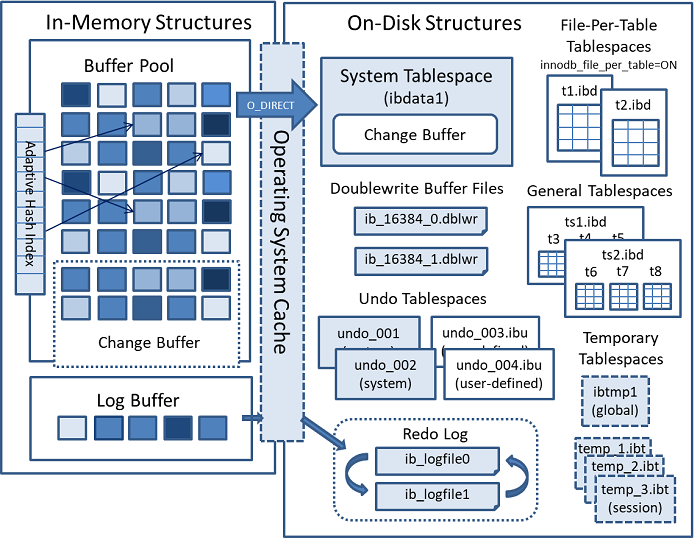
内存架构(In-Memory Structures)
Buffer Pool
Buffer Pool是内存中的一块区域,InnoDB访问表和索引的时候缓存这些数据。buffer pool使得经常使用的数据直接从内存读取,加快了数据处理。在专用的服务器上,会给buffer pool分配80%的物理内存。
为了应对大量读操作,buffer pool被划分为很多页(pages)(就是上图的一个一个蓝色小块),每个页存储多行数据(multiple rows)为了提高缓存管理效率,buffer pool采用链表页( a linked list of pages)实现。采用LRU(least recently used)算法来将很少使用的数据驱除(aged out).
如何充分使用buffer pool保持经常被访问的数据在内存中,是MySQL调优的重要方面。
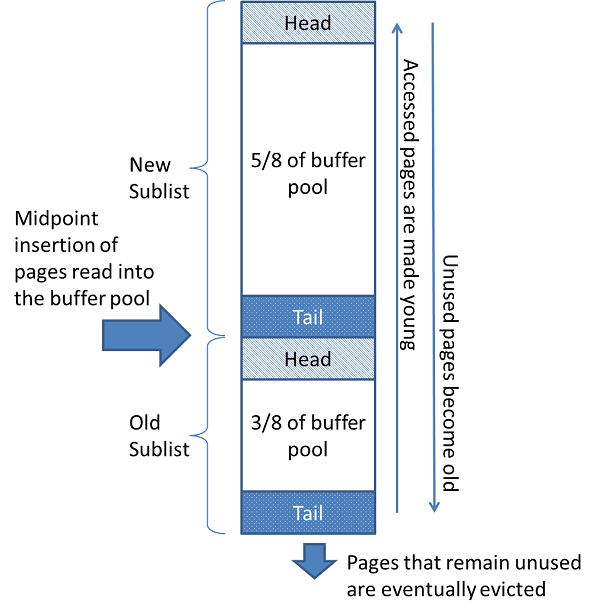
buffer pool也是分young(5/8)和old(3/8)的。Midpoint位于young和old的中间,刚好遇到young的尾(tail)和old的头(head)。
当读一个page到buffer pool的时候,这个page被插入到midpoint的位置。读page可能发生在用户执行了sql查询或者是InnoDB的预读操作(read-ahead operation)
访问一个位于old sublist中的page,这个page会变成“young”,被移到new sublist的头。
随着数据库操作,buffer pool中未被访问的pages会变老,被移到list的尾部。只要有其他pages更新了,那new和old中的其他数据就会变老。当有新的pages插入到midpoint,old sublist里的其他页面会变老。最后,那些没被访问的page到达了oldsublist的tail,被驱逐(evicteds)
Change Buffer
change buffer是一个特殊的数据结构,当这些pages没在buffer pool里时,缓存对二级索引页(secondary index pages)的更改。缓冲区的修改,比如来自insert,update,delete操作,会跟其他的读操作产生的加载到buffer pool中的页(page)进行合并。
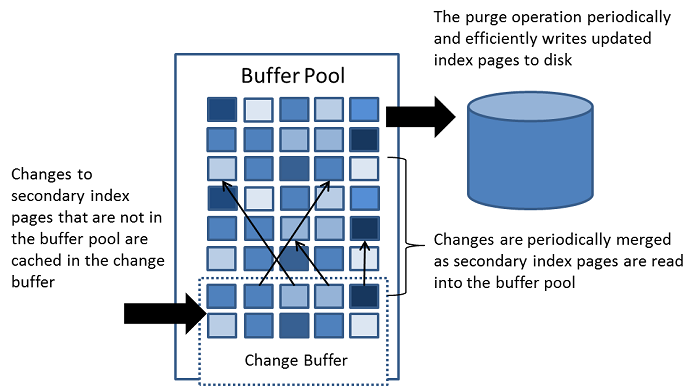
跟聚簇索引(clustered indexes)有所不同的是,二级索引通常都不是唯一的,并且插入二级索引的顺序相对随机。
同样,删除和更新可能会影响索引树中不相邻的二级索引页。当受影响的页被其他操作读进buffer pool,随后合并缓存的更改,避免了将二级索引页从磁盘读入buffer pool所需的大量的随机IO。
在系统大部分处于空闲状态或缓慢关机期间运行的清除操作会定期将更新的索引页写入磁盘。
与将每个值立即写入磁盘相比,清除操作可以更有效地为一系列索引值写入磁盘块。
当有大量的受影响行或者大量的二级索引更新,change buffer的合并可能会耗费几个小时的时间。这期间,此案IO增加,可能会导致跟磁盘绑定(disk-bound queries)的查询效率的显著下降。
在内存上,change buffer是buffer pool的一部分。在磁盘上,change buffer是系统表空间的一部分,当数据库服务器关机的时候,索引的更改会被存储在上面。
On-Disk Structures
Redo Log
Redo log是基于硬盘的数据结构,在崩溃恢复(crash recovery)期间用于矫正不完整事务写入的数据。
在初始化期间和连接接收前,意外宕机前对数据文件未完成的修改会被自动重放(replayed)
默认情况下,redo log在物理上指的就是ib_logfile0 and ib_logfile1。MySQL会以循环的方式写入redo log文件。
Undo Logs
undo log 是跟单个读写事务关联的撤销日志记录的集合。一条undo log记录包含了如何撤销事务在聚集索引记录上的最新修改。undo log可以按需分配。一个事务中对普通临时表的增删改查需要4个undo log,普通表的insert操作只需要一个undo log.
Indexes
聚簇索引和二级索引
每个InnoDB表都有一个存储行数据的聚簇索引。
通常情况下,聚簇索引与主键索引同义。
如果一个表上没定义primary key,InnoDB会使用第一个UNIQUE索引并将所有的key定义为NOT NULL来作为聚簇索引。再如果,连个unique索引页没有,InnoDB就说了,我自己来在包含row ID值的列上生成一个GEN_CLUST_INDEX
聚簇索引怎么加速查询的?
通过聚簇索引访问一行数据很快,因为索引的查询直接访问到了包含这行数据的页。
二级索引如何关联到聚簇索引
在二级索引中,每条记录都包含了行的主键以及为二级索引指定的列。InnoDB使用主键来查询聚簇索引上的值。
当新数据插入到聚簇索引中,InnoDB会为将来插入或者索引的更新保留1/16的页空间。
如果按顺序插入索引记录(升序或降序),则结果索引页将占满15/16。
如果以随机顺序插入记录,则页面的容量为1/2到15/16。
InnoDB的锁和事务模型(Transaction Model)
InnoDB Locking
Shared and Exclusive Locks
InnoDB实现了标准的行锁,包含两种类型:共享锁(S锁)和排它锁(X锁)。
共享锁允许持有锁的事务读取一行;排它锁允许持有锁的事务更新或删除一行。
如果一个事务T1持有了row r这一行的S锁,那么对于想要获取r上的事务T2来说,是这样的处理过程:
- T2请求r上的S锁,会立即成功。最终,T1和T2都同时拥有r上的S锁。
- T2请求X锁,不会被立即授予(grant)。
如果事务T1在row r上持有的是X锁,那么事务T2不管是请求r上的S锁还是X锁,都无法立即获得。事务T2必须等到事务T1释放在row r上的锁才行。
Intention Locks
InnoDB支持多粒度的锁定,允许表锁和行锁共存。例如,通过语句LOCK TABLES ... WRITE获取了特定表上的X锁,为了使多粒度的锁定可行,InnoDB使用了意向锁(intention locks)。意向锁是表级锁,指示事务稍后对表中的行需要哪种类型的锁(共享锁或排他锁)
有两种类型的意向锁:
- 意向共享锁(intension shared lock)表示事务准备获取表中某些行的共享锁。
- 意向排它锁表示事务准备获取表中某些行的排他锁。
例如,SELECT ... FOR SHARE设置了一个IS锁,SELECT ... FOR UPDATE设置了一个IX锁。
意向锁协议如下:
- 一个事务获取一个表的某行数据上的共享锁之前,它必须首先获取表上的意向共享锁(IS)或者更强的锁。
- 一个事务获取一个表的某行数据上的排他锁之前,它必须首先获取表上的意向排他锁(IX)
表级锁的相容性如下:
X |
IX |
S |
IS |
|
|---|---|---|---|---|
X |
Conflict | Conflict | Conflict | Conflict |
IX |
Conflict | Compatible | Conflict | Compatible |
S |
Conflict | Conflict | Compatible | Compatible |
IS |
Conflict | Compatible | Compatible | Compatible |
意向锁不会阻塞任何事情,除了全表请求(eg, LOCK TABLES ... WRITE)意向锁的主要目的就是表示有人正在或者准备锁定表中的行数据。
Record Locks
记录锁是锁定索引记录的锁。
记录锁定始终锁定索引记录,即使没有定义索引的表也是如此(参考上面讲的聚簇索引和二级索引).
Gap Locks
间隙锁是锁定索引记录间隙或者 锁定第一个索引记录之前或者最后一条索引记录之后的间隙 的锁。
例如,SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;阻止了其他事务向t.c1插入15,不管是不是在列上已经存在了这样的值,因为范围内所有值的间隙被锁定了。
间隙可能跨越单个索引值,多个索引值,甚至为空。
间隙锁是性能和并发的权衡结果的一部分,可以在某些隔离级别下使用,而在其他级别不能使用。
使用唯一索引锁定行来搜索唯一行的语句不需要间隙锁定。(不包括搜索条件仅包含多列唯一索引的某些列的情况)例如,假设id有唯一索引,那么SELECT * FROM child WHERE id = 100;只会在id=100的行使用index-record lock,如果id没有没索引或者没有非唯一索引,这条语句还是会锁定之前的间隙。
值得注意的是,不同事务冲突的锁可以保持在不同的间隙上。例如事务A在一个间隙上持有一个共享间隙锁(gap S-lock),而事务B在同一个间隙上持有一个排他间隙锁。允许冲突的间隙锁的原因是,如果从索引中清除记录,则必须合并由不同事务保留在记录上的间隙锁。
InnoDB中的间隙锁是“纯粹禁止的”(原来是代表了这个锁存在的意义,就是为了禁止),意味着唯一的目的就是阻止其他事务插入到间隙中。间隙锁定也可以被显式禁用,通过将隔离级别更改为READ COMMITED(这个级别下,假如where条件不满足的那些索引上的记录对应的record lock会被释放)
也可以显示
Next-Key Locks
next-key lock是索引上的记录锁与索引前面间隙的间隙锁的组合。
InnoDB执行行级锁定的方式是,当它搜索或扫描表索引时,会在遇到的索引记录上设置共享或互斥锁。因此,行锁实际上就是index-record lock.一条索引记录上的next-key lock会影响这条索引记录前面的间隙。换句话说,next-key lock就是index record lock + 这条记录前面间隙上的gap lock。
假如说一个索引包含的值有10,11,13,20,那么next-key lock包含了一下范围:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
InnoDB使用next-key locks来搜索和索引扫描,解决了幻读问题。
Insert Intention Locks
插入意向锁是在行插入之前通过insert操作设置的间隙锁的一种类型。
这个锁表示的插入的意图是,如果多个事务要在同一块gap插入数据,如果插入的不是同一个位置,那么不会互相阻塞。
比如索引记录上有4和7,分别尝试插入值5和6的单独事务在获得插入行的排他锁之前,分别使用插入意向锁来锁定4和7之间的间隙,但不会相互阻塞,因为行是无冲突的。
验证insert意向锁:(group就是个很普通的表,id是自增主键,name varchar(10))
前置条件:group表里有了id>4的数据,另外将session里的提交模式改为手动
session1:
begin;
select * from `group` where id > 4 for update;
session2:
begin ;
insert into `group`(id, name) values (8, 'yyy');
session3:
SHOW ENGINE INNODB STATUS;
依次执行,1,2,3三个会话,会看到有如下信息:
TRANSACTIONS
------------
Trx id counter 10055945
Purge done for trx's n:o < 0 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 422113267110440, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422113267109520, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 10055944, ACTIVE 23 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 3, OS thread handle 140637967390464, query id 331 192.168.31.198 root update
/* ApplicationName=DataGrip 2019.2.5 */ insert into `group`(id, name) values (8, 'yyy')
------- TRX HAS BEEN WAITING 23 SEC FOR THIS LOCK TO BE GRANTED:
// ===========重点在这行===============
RECORD LOCKS space id 169 page no 3 n bits 72 index PRIMARY of table `mysql_learning`.`group` trx id 10055944 lock_mode X insert intention waiting
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
AUTO-INC Locks
An
AUTO-INClock is a special table-level lock taken by transactions inserting into tables withAUTO_INCREMENTcolumns
简单的讲,为了使id连续自增,如果一个事务插入记录,其他事务必须等到这个事务结束。
Predicate Locks for Spatial Indexes
不做了解。
Locks Set by Different SQL Statements in InnoDB
locking read(比如select for share或select for update)/ update、 delete通常会在处理sql语句的时候,在每个被扫描的索引记录上设置record lock。sql语句里有没有where条件将这行数据排除掉也没有影响。InnoDB不知道确切的where条件,只知道哪些索引范围被扫描到了。锁通常是next-key lock,它会阻止插入到记录前面的间隙的插入语句。
*如果在查询里用到了二级索引,并且索引的记录锁也被设置为排他锁,那么InnoDB也会去聚簇索引那里取出相应的数据并加锁*。
如果语句中没有合适的索引并且MySQL必须扫描整个表来处理语句,表中的每一行都会被锁定,就会阻止其他用户的所有insert操作。所以创建好的索引非常重要,避免查询不必要的扫描多行。
InnoDB设置的锁类型如下:
-
SELET ... FROM是一致性读,读数据库的快照,并且没有设置任何锁,除非隔离级别改为SERIALIZABLE。SERIALIZABLE的级别,查询会在遇到的索引记录上设置next-key lock.但是,对于使用唯一索引来搜索唯一行的行锁定的语句,仅需要索引记录锁定(index record lock)。 -
SELECT ... FOR UPDATE和SELECT ... FOR SHARE会对扫描到的行加锁,对于不满足where条件的行,会释放上面的锁。 -
locking read(比如select for share或select for update)/update、delete语句,使用哪种锁取决于,语句是否使用具有唯一搜索条件或范围类型搜索条件的唯一索引。 -
- 对于使用唯一搜索条件的唯一索引来说,InnoDB仅锁定发现的索引记录,而不会锁定它前面的间隙。
- 对于其他搜索条件和非唯一索引,InnoDB使用间隔锁或next-key锁来锁定扫描的索引范围,以阻止其他会话插入该范围所覆盖的间隔。
-
UPDATE ... WHERE ...在查询找到的每条记录上设置了一个排他next-key lock****.但是,对于使用唯一索引来搜索唯一行的行锁定的语句,仅需要索引记录锁定(index record lock)。 -
当UPDATE修改一条聚簇索引记录,受影响的二级索引记录会被隐式锁定。在插入新的二级索引记录之前执行重复检查扫描时,以及在插入新的二级索引记录时,UPDATE操作还会在受影响的二级索引记录上获得共享锁。
-
DELETE FROM ... WHERE ...在每个遇到的记录上设置了一个排他next-key lock但是,对于使用唯一索引来搜索唯一行的行锁定的语句,仅需要索引记录锁定(index record lock)。 -
INSERT在插入的行上设置了一个排他锁。这个锁是一个index-record lock,不是next-key lock,不会阻止其他会话在插入的行前面的间隙插入数据。插入行之前,会设置一个插入意向锁。
锁验证
create table gap_lock_test(
col1 varchar(10) primary key,
col2 varchar(20)
);
create index gap_lock_test_idx1 on gap_lock_test(col2);
insert into gap_lock_test values('1', '1');
insert into gap_lock_test values('3', '3');
insert into gap_lock_test values('7', '3');
insert into gap_lock_test values('5', '5');
记录锁
| Seq | Session 1 | Session 2 | Session 3 |
|---|---|---|---|
| 1 | set session transaction isolation level REPEATABLE READ; start transaction; | set session transaction isolation level REPEATABLE READ; start transaction; | |
| 2 | select col2 from gap_lock_test where col2 = '3' for update; | ||
| 3 | update gap_lock_test set col2 = **'4' **where col2 = '3'; | ||
| 4 | SHOW ENGINE INNODB STATUS; | ||
| 5 |
结果:
/* ApplicationName=DataGrip 2019.2.5 */ update gap_lock_test set col2 = '4'
where col2 = '3'
------- TRX HAS BEEN WAITING 3 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 172 page no 4 n bits 72 index gap_lock_test_idx1 of table `lock_learning`.`gap_lock_test` trx id 10057155 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 1; hex 33; asc 3;;
1: len 1; hex 33; asc 3;;
可以看到,创建了Record lock。
Gap lock
| Seq | Session 1 | Session 2 | Session 3 |
|---|---|---|---|
| 1 | set session transaction isolation level REPEATABLE READ; start transaction; | set session transaction isolation level REPEATABLE READ; start transaction; | |
| 2 | select ** from gap_lock_testwhere* col1 between '1' and '5' ****lock in share mode; | ||
| 3 | insert into gap_lock_test values('2', '2'); | ||
| 4 | SHOW ENGINE INNODB STATUS; | ||
| 5 |
结果
/* ApplicationName=DataGrip 2019.2.5 */ insert into gap_lock_test values('2', '2')
------- TRX HAS BEEN WAITING 3 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 172 page no 3 n bits 72 index PRIMARY of table `lock_learning`.`gap_lock_test` trx id 10057179 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 1; hex 33; asc 3;;
1: len 6; hex 000000997477; asc tw;;
2: len 7; hex f5000001810110; asc ;;
3: len 1; hex 33; asc 3;;
select * from performance_schema.data_locks;
And you can check the LockMode column:
- X/S :means next-key lock;
- X/S, Gap :the combo means gap lock end;
- X/S, Rec_not_gap :the combo means record lock.
参考:MySQL8手册