一、
使用request库的get()函数访问360搜索网页20次并且打印返回状态,text内容,计算text()属性和content()属性所返回网页内容的长度。
对360搜索主页进行爬虫:
利用request库的get函数访问google 20次,输入代码为:
import requests
wan="https://www.so.com/"
def pac(wan):
print("第",i+1,"次访问")
r=requests.get(wan,timeout=30)
r.raise_for_status()
print("text编码方式为",r.encoding)
print("网络状态码为:",r.status_code)
print("text属性:",r.text)
print("content属性:",r.content)
return r.text
for i in range(20):
print(pac(wan))
由于结果太长,这里将代码改为打印text属性和content属性的长度后展示最后一次访问的结果,代码改动:
print("text属性长度:",len(r.text))
print("content属性长度:",len(r.content))
第 20 次访问
text编码方式为 ISO-8859-1
网络状态码为: 200
text属性长度: 5294
content属性长度: 5294
<!DOCTYPE html><!--[if lt IE 7 ]><html class="ie6"><![endif]--><!--[if IE 7 ]><html class="ie7"><![endif]--><!--[if IE 8 ]><html class="ie8"><![endif]--><!--[if IE 9 ]><html class="ie9"><![endif]--><!--[if (gt IE 9)|!(IE)]><!--><html class="w3c"><!--<![endif]--><head><meta charset="utf-8"><title>360æç´¢</title><link rel="dns-prefetch" href="//s0.qhimg.com"><link rel="dns-prefetch" href="//s1.qhimg.com"><link rel="dns-prefetch" href="//p0.qhimg.com"><link rel="dns-prefetch" href="//p1.qhimg.com">
<meta name="keywords" content="360æç´¢,360æç´¢,ç½é¡µæç´¢,è§é¢æç´¢,å¾çæç´¢,é³ä¹æç´¢,æ°é»æç´¢,软件æç´¢,å¦æ¯æç´¢">
<meta name="description" content="360æç´¢æ¯å®å
¨ãç²¾åãå¯ä¿¡èµçæ°ä¸ä»£æç´¢å¼æï¼ä¾æäº360æ¯åççå®å
¨ä¼å¿ï¼å
¨é¢æ¦æªåç±»é鱼欺è¯çæ¶æç½ç«ï¼æä¾æ´æ¾å¿çæç´¢æå¡ã 360æç´¢ soé è°±ã">
<style type="text/css">html,body{height:100%}html,body,form,input,span,p,img,ul,ol,li,dl,dt,dd{margin:0;padding:0;border:0}ul,ol{list-style:none}body{background:#fff;font:12px/1.5 arial,sans-serif;text-align:center}a{text-decoration:none}a:hover{text-decoration:underline}.page-wrap{position:relative;min-height:100%;_height:100%}#main{700px;margin:0 auto;padding:100px 0}#logo{margin:0 auto 55px;position:relative;left:-10px}#logo div{203px;height:72px;background-image:url(http://p0.qhimg.com/t01cbf97e6893738583.png);background-image:-webkit-image-set(url(http://p1.qhimg.com/t01cbf97e6893738583.png) 1x,url(http://p0.qhimg.com/t015dc0adab50c8e912.png) 2x);margin:0 auto}#so-nav-tabs{font-size:14px;text-align:left;padding-left:75px;position:relative;z-index:999}#so-nav-tabs a,#so-nav-tabs strong{height:31px;line-height:31px;display:inline-block;margin-right:18px;*margin-right:15px;color:#666}#so-nav-tabs a:hover{color:#3eaf0e;text-decoration:none}#so-nav-tabs strong{color:#3eaf0e}#search-box{padding-left:40px;text-align:left}#input-container{500px;height:36px;display:inline-block;border:1px solid #bbb;box-shadow:0 2px 1px #f0f0f0;position:relative;z-index:1}#suggest-align{height:32px;position:relative}#input{485px;height:22px;margin:7px 0 5px 8px;outline:0;background:#fff;font-size:16px;line-height:22px;vertical-align:top}#search-button{100px;height:38px;_height:40px;display:inline-block;margin-left:5px;outline:0;border:1px solid #3eaf0e;*border:0;box-shadow:0 1px 1px rgba(0,0,0,0.2);-webkit-box-shadow:0 1px 1px rgba(0,0,0,0.2);-moz-box-shadow:0 1px 1px rgba(0,0,0,0.2);background:url(http://p1.qhimg.com/d/_onebox/btn-98-114.png) no-repeat #3eaf0e;color:#fff;font:bold 16px arial,sans-serif;vertical-align:top;cursor:pointer}#search-button.hover{border:1px solid #4bbe11;*border:0;background-position:0 -38px}#search-button.mousedown{border:1px solid #4bbe11;*border:0;background-position:0 -76px}#footer{100%;height:36px;line-height:36px;text-align:left;color:#eaeaea;position:absolute;left:0;bottom:0}#footer p{margin:0 20px}#footer a{color:#959595;margin:0 5px 0 3px}#footer span{float:right;font-style:normal;color:#959595}</style>
</head>
text编码方式为 ISO-8859-1
网络状态码为: 200
text属性长度: 5294
content属性长度: 5294
<!DOCTYPE html><!--[if lt IE 7 ]><html class="ie6"><![endif]--><!--[if IE 7 ]><html class="ie7"><![endif]--><!--[if IE 8 ]><html class="ie8"><![endif]--><!--[if IE 9 ]><html class="ie9"><![endif]--><!--[if (gt IE 9)|!(IE)]><!--><html class="w3c"><!--<![endif]--><head><meta charset="utf-8"><title>360æç´¢</title><link rel="dns-prefetch" href="//s0.qhimg.com"><link rel="dns-prefetch" href="//s1.qhimg.com"><link rel="dns-prefetch" href="//p0.qhimg.com"><link rel="dns-prefetch" href="//p1.qhimg.com">
<meta name="keywords" content="360æç´¢,360æç´¢,ç½é¡µæç´¢,è§é¢æç´¢,å¾çæç´¢,é³ä¹æç´¢,æ°é»æç´¢,软件æç´¢,å¦æ¯æç´¢">
<meta name="description" content="360æç´¢æ¯å®å
¨ãç²¾åãå¯ä¿¡èµçæ°ä¸ä»£æç´¢å¼æï¼ä¾æäº360æ¯åççå®å
¨ä¼å¿ï¼å
¨é¢æ¦æªåç±»é鱼欺è¯çæ¶æç½ç«ï¼æä¾æ´æ¾å¿çæç´¢æå¡ã 360æç´¢ soé è°±ã">
<style type="text/css">html,body{height:100%}html,body,form,input,span,p,img,ul,ol,li,dl,dt,dd{margin:0;padding:0;border:0}ul,ol{list-style:none}body{background:#fff;font:12px/1.5 arial,sans-serif;text-align:center}a{text-decoration:none}a:hover{text-decoration:underline}.page-wrap{position:relative;min-height:100%;_height:100%}#main{700px;margin:0 auto;padding:100px 0}#logo{margin:0 auto 55px;position:relative;left:-10px}#logo div{203px;height:72px;background-image:url(http://p0.qhimg.com/t01cbf97e6893738583.png);background-image:-webkit-image-set(url(http://p1.qhimg.com/t01cbf97e6893738583.png) 1x,url(http://p0.qhimg.com/t015dc0adab50c8e912.png) 2x);margin:0 auto}#so-nav-tabs{font-size:14px;text-align:left;padding-left:75px;position:relative;z-index:999}#so-nav-tabs a,#so-nav-tabs strong{height:31px;line-height:31px;display:inline-block;margin-right:18px;*margin-right:15px;color:#666}#so-nav-tabs a:hover{color:#3eaf0e;text-decoration:none}#so-nav-tabs strong{color:#3eaf0e}#search-box{padding-left:40px;text-align:left}#input-container{500px;height:36px;display:inline-block;border:1px solid #bbb;box-shadow:0 2px 1px #f0f0f0;position:relative;z-index:1}#suggest-align{height:32px;position:relative}#input{485px;height:22px;margin:7px 0 5px 8px;outline:0;background:#fff;font-size:16px;line-height:22px;vertical-align:top}#search-button{100px;height:38px;_height:40px;display:inline-block;margin-left:5px;outline:0;border:1px solid #3eaf0e;*border:0;box-shadow:0 1px 1px rgba(0,0,0,0.2);-webkit-box-shadow:0 1px 1px rgba(0,0,0,0.2);-moz-box-shadow:0 1px 1px rgba(0,0,0,0.2);background:url(http://p1.qhimg.com/d/_onebox/btn-98-114.png) no-repeat #3eaf0e;color:#fff;font:bold 16px arial,sans-serif;vertical-align:top;cursor:pointer}#search-button.hover{border:1px solid #4bbe11;*border:0;background-position:0 -38px}#search-button.mousedown{border:1px solid #4bbe11;*border:0;background-position:0 -76px}#footer{100%;height:36px;line-height:36px;text-align:left;color:#eaeaea;position:absolute;left:0;bottom:0}#footer p{margin:0 20px}#footer a{color:#959595;margin:0 5px 0 3px}#footer span{float:right;font-style:normal;color:#959595}</style>
</head>
<body>
<div class="page-wrap">
<div id="main">
<div id="logo"><div></div></div>
<div id="so-nav-tabs">
<a href="http://sh.qihoo.com/?src=tab_web">æ°é»</a>
<strong>ç½é¡µ</strong>
<a href="http://wenda.so.com/?src=tab_web">é®ç</a>
<a href="http://video.so.com/?src=tab_web">è§é¢</a>
<a href="http://image.so.com/?src=tab_web">å¾ç</a>
<a href="http://music.so.com/?src=tab_web">é³ä¹</a>
<a href="http://map.so.com/?src=tab_web">å°å¾</a>
<a href="http://baike.so.com/?src=tab_web">ç¾ç§</a>
<a href="http://ly.so.com/?src=tab_web">è¯å»</a>
</div>
<div id="search-box">
<form action="/s">
<span id="input-container">
<input type="hidden" name="ie" value="utf-8">
<input type="hidden" name="shb" value="1">
<input type="hidden" name="src" id="from" value="noscript_home">
<div id="suggest-align">
<input type="text" name="q" id="input" suggestWidth="501px" autocomplete="off" x-webkit-speech><cite id="suggest-tp"></cite>
</div>
<div id="sug-arrow"><span id="sug-new"></span></div>
</span><input type="submit" id="search-button" value="æä¸ä¸">
</form>
</div>
</div>
<div id="footer">
<p>
<span>Copyright © 360.CN 京ICPå¤08010314å·-19 京å
¬ç½å®å¤110000000006å·</span>
<a href="http://info.so.com/feedback.html">æè§åé¦</a>|
<a href="http://zhanzhang.so.com">ç«é¿å¹³å°</a>|
<a href="http://info.so.com/about.html">å
³äºæ们</a>|
<a href="http://www.so.com/help/help_1_1.html">使ç¨å¸®å©</a>|
<a href="http://www.so.com/help/help_iduty.html">使ç¨åå¿
读</a>|
<a href="http://e.360.cn?src=srp">æ¨å¹¿åä½</a>
</p>
</div>
</div>
<img src="//s.qhupdate.com/so/click.gif?pro=so&pid=home&mod=noscriptpage" >
</body>
</html>
<div class="page-wrap">
<div id="main">
<div id="logo"><div></div></div>
<div id="so-nav-tabs">
<a href="http://sh.qihoo.com/?src=tab_web">æ°é»</a>
<strong>ç½é¡µ</strong>
<a href="http://wenda.so.com/?src=tab_web">é®ç</a>
<a href="http://video.so.com/?src=tab_web">è§é¢</a>
<a href="http://image.so.com/?src=tab_web">å¾ç</a>
<a href="http://music.so.com/?src=tab_web">é³ä¹</a>
<a href="http://map.so.com/?src=tab_web">å°å¾</a>
<a href="http://baike.so.com/?src=tab_web">ç¾ç§</a>
<a href="http://ly.so.com/?src=tab_web">è¯å»</a>
</div>
<div id="search-box">
<form action="/s">
<span id="input-container">
<input type="hidden" name="ie" value="utf-8">
<input type="hidden" name="shb" value="1">
<input type="hidden" name="src" id="from" value="noscript_home">
<div id="suggest-align">
<input type="text" name="q" id="input" suggestWidth="501px" autocomplete="off" x-webkit-speech><cite id="suggest-tp"></cite>
</div>
<div id="sug-arrow"><span id="sug-new"></span></div>
</span><input type="submit" id="search-button" value="æä¸ä¸">
</form>
</div>
</div>
<div id="footer">
<p>
<span>Copyright © 360.CN 京ICPå¤08010314å·-19 京å
¬ç½å®å¤110000000006å·</span>
<a href="http://info.so.com/feedback.html">æè§åé¦</a>|
<a href="http://zhanzhang.so.com">ç«é¿å¹³å°</a>|
<a href="http://info.so.com/about.html">å
³äºæ们</a>|
<a href="http://www.so.com/help/help_1_1.html">使ç¨å¸®å©</a>|
<a href="http://www.so.com/help/help_iduty.html">使ç¨åå¿
读</a>|
<a href="http://e.360.cn?src=srp">æ¨å¹¿åä½</a>
</p>
</div>
</div>
<img src="//s.qhupdate.com/so/click.gif?pro=so&pid=home&mod=noscriptpage" >
</body>
</html>
二、
这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
a.打印head标签内容和你的学号后两位
b 获取body标签内容
c 获取id为first的标签对象
d 获取并打印html页面中的中文字符
html为:
1 <!DOCTYPE html> 2 3 <html> 4 5 <head> 6 7 <meta charset="utf-8"> 8 9 <title>菜鸟教程(runoob.com)</title> 10 11 </head> 12 13 <body> 14 15 <hl>我的第一个标题学号25</hl> 16 17 <p id="first">我的第一个段落。</p> 18 19 </body> 20 21 <table border="1"> 22 23 <tr> 24 25 <td>row 1, cell 1</td> 26 27 <td>row 1, cell 2</td> 28 29 </tr> 30 31 <tr> 32 33 <td>row 2, cell 1</td> 34 35 <td>row 2, cell 2</td> 36 37 <tr> 38 39 </table> 40 41 </html>
菜鸟教程运行结果:

相关计算代码:
from bs4 import BeautifulSoup
import re
soup=BeautifulSoup('''<!DOCTYPE html>
<html1>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<hl>我的第一标题</hl>
<p id="first">我的第一个段落。</p>
</body>
<table border="1">
<tr>
<td>row 1, cell 1</td>
<td>row 1, cell 2</td>
</tr>
<tr>
<td>row 2, cell 1</td>
<td>row 2, cell 2</td>
<tr>
</table>
</html>''')
print("打印head标签和我的学号")
print(soup.head,"我的学号:07")
print("获取body标签内容",soup.body)
print("获取id为first的标签对象",soup.find_all(id="first"))
st=soup.text
pp = re.findall(u'[u1100-uFFFDh]+?',st)
print("获取并打印html页面中的中文字符")
print(pp)
运行结果:

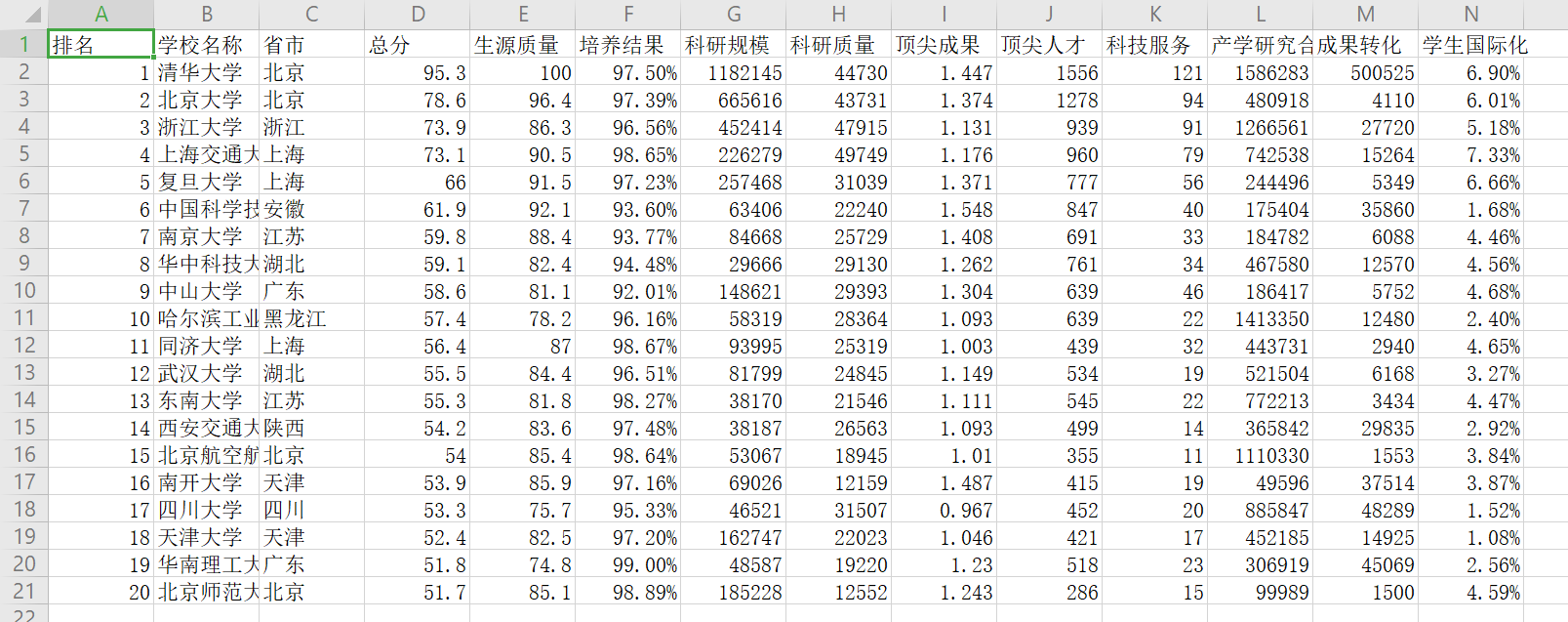
三、爬中国大学排名网站内容(http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html)
把爬取的数据,存为csv文件。
代码:
import csv
import os
import requests
from bs4 import BeautifulSoup
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding ='utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def writercsv(save_road,num,title):
if os.path.isfile(save_road):
with open(save_road,'a',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=allUniv[i]
csv_write.writerow(u)
else:
with open(save_road,'w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
csv_write.writerow(title)
for i in range(num):
u=allUniv[i]
csv_write.writerow(u)
title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模",
"科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化","学生国际化"]
save_road="D:\pm.csv"
def main():
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
writercsv(save_road,20,title)
main()
结果: