第九章学习笔记
第九章的主要内容是Linux操作系统中的I/O库函数。对于I/O库函数的介绍,分别为以下几个方面:
- I/O库函数的作用及其相对于系统调用的优势
- I/O库函数和系统调用之间的相同点和不同点
- I/O库函数的算法
- I/O库函数的不同模式
- 文件流缓冲方案
知识点归纳:
经过一整章的自主学习,大致对I/O库函数的构成、功能有了初步的认识。下面会对该知识进行具体描述:
- I/O库函数与系统调用
学习I/O库函数之前就需要明白另一种文件操作的基础:系统调用。
Linux下对文件操作有两种方式:系统调用system call和库函数调用Library functions。书上P224中就对二者的最主要功能区别做了阐述:系统调用只支持数据块的读写,而I/O库函数可以指出更多逻辑单元的读写,例如行、字符、结构化记录等。系统调用实际上就是指最底层的一个调用,在linux程序设计里面就是底层调用的意思面向的是硬件。而库函数调用则面向的是应用开发的,相当于应用程序的api,采用这样的方式有很多种原因,第一:双缓冲技术的实现。第二,可移植性。第三,底层调用本身的一些性能方面的缺陷。第四:让api也可以有了级别和专门的工作面向。
①系统调用(底层文件访问)
系统调用提供的函数如open, close, read, write, ioctl等
系统调用通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
②库函数调用(标准IO库)
标准IO库函数提供的文件操作函数如fopen, fread, fwrite, fclose, fflush, fseek等,
库函数调用通常用于应用程序中对一般文件的访问。
库函数调用是系统无关的,因此可移植性好。
由于库函数调用是基于C库的,因此也就不可能用于内核空间的驱动程序中对设备的操作。
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
使用库函数也有系统调用的开销,为什么不直接使用系统调用呢?这是因为,读写文件通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),这时,使用库函数就可以大大减少系统调用的次数。这一结果又缘于缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,例如用fwrite写文件,都是先将内容写到用户空间缓冲区,当用户空间缓冲区满或者写操作结束时,才将用户缓冲区的内容写到内核缓冲区,同样的道理,当内核缓冲区满或写结束时才将内核缓冲区内容写到内核缓冲区,同样的道理,当内核缓冲区满或写结束时才将内核缓冲区内容写到文件对应的硬件媒介。
9.4中的介绍中,详细阐明了调用过程。使用系统调用,只需要一次复制,就可以完成任务,而I/O库函数需要两次复制,即从内核到内部缓冲区再到程序缓冲区。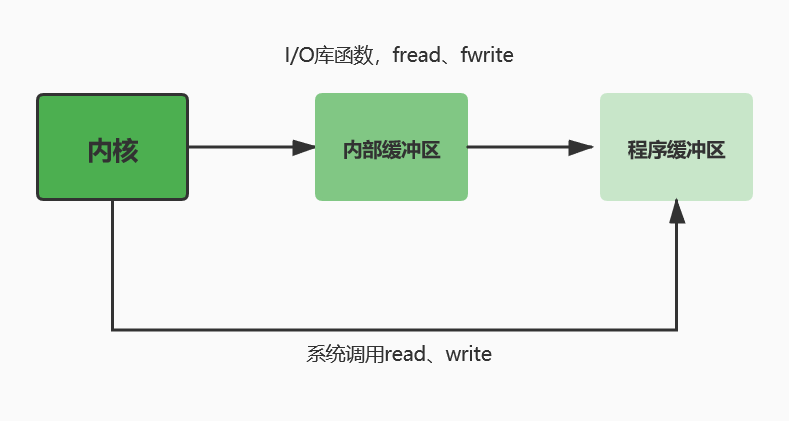
由过程图可知,虽然系统调用的复制次数更少,但只适用于以数据块大小为单位的请求中,因为系统调用只支持数据块的读写。而I/O库函数可以适用于其他逻辑单元,如行、字符等。
从书中9.2的例子不难看出,I/O库函数和系统调用的区别不仅仅限于表面的语法和表述,更深层次的区别在于硬件底层的运行逻辑的不同。I/O库函数可以满足在很多情况下更多的用户需求,所以系统学习I/O库函数的意义不言而喻。
2.I/O库函数的算法
经过9.1、9.2、9.4的学习,基本了解了系统调用与I/O库函数的基本逻辑以及区别和联系,9.3着重介绍了I/O库函数的具体算法。P227介绍了三个I/O库函数的算法:fread、fwrite、fclose。下面将分别学习三种算法的区别:
①fread算法
功 能: 从一个流中读数据,从所给的输入流stream中读取的n项数据,每一项数据长度为size字节,到由ptr所指的块中。
函数原型: int fread(void *ptr, int size, int nitems, FILE *stream);
参数: void *ptr 存放读取的数据的空间
int size 读取的字符长度
int nitems 读取字符的数量
FILE *stream 读取的数据流
返回值: 成功 返回所读的数据项数(不是字节数),失败 遇到文件结束或出错时可能返回0。
补充: void free(void *block); 释放先前分配的首地址为block的内存块。
②fwrite算法
功 能: 与fread算法类似写内容到流中。
函数原型: fwrite(void *buffer, size_t length, size_t count, FILE *filename);
参数:buffer:是一个指针,对fwrite来说,是要输出数据的地址。
size_t size 要写入的字节数;
size_t count:要进行写入size字节的数据项的个数;
FILE *filename 读取的数据流
返回值: 它返回将写入文件的对象数。 如果要写入的对象数量较少或遇到EOF ,则它将引发错误。
补充: 在文件处理中,通过fwrite()函数,我们将大小为长度的对象的计数写入名为缓冲区的数组的输入流文件名中。
③fclose算法
功 能: 关闭文件先前打开的文件,关闭后会把缓冲区的数据送到程序或者文件(要看先前对文件的操作是读取文件数据还是输出数据到文件)
函数原型:int fclose(FILE *fp);
参数:是一个文件指针,指向要关闭的文件。例如先前把创建的文件给了fp,现在fp则代表着这个文件,操作fp即可关闭文件。
返回值: 如果文件关闭成功,返回值是 0;
如果文件关闭失败,返回值是 EOF,并设置 errno 为指定的错误。、
3.I/O库函数模式
书中对于fopen()的介绍较少,上网查找资料。C 库函数 FILE *fopen(const char *filename, const char *mode) 使用给定的模式 mode 打开 filename 所指向的文件。
- filename -- 这是 C 字符串,包含了要打开的文件名称。
- mode -- 这是 C 字符串,包含了文件访问模式,模式如下:
|
字符串
|
说明
|
|
r
|
以只读方式打开文件,该文件必须存在。
|
|
r+
|
以读/写方式打开文件,该文件必须存在。
|
|
rb+
|
以读/写方式打开一个二进制文件,只允许读/写数据。
|
|
rt+
|
以读/写方式打开一个文本文件,允许读和写。
|
|
w
|
打开只写文件,若文件存在则文件长度清为零,即该文件内容会消失;若文件不存在则创建该文件。
|
|
w+
|
打开可读/写文件,若文件存在则文件长度清为零,即该文件内容会消失;若文件不存在则创建该文件。
|
|
a
|
以附加的方式打开只写文件。若文件不存在,则会创建该文件;如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(EOF 符保留)。
|
|
a+
|
以附加方式打开可读/写的文件。若文件不存在,则会创建该文件,如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(EOF符不保留)。
|
|
wb
|
以只写方式打开或新建一个二进制文件,只允许写数据。
|
|
wb+
|
以读/写方式打开或新建一个二进制文件,允许读和写。
|
|
wt+
|
以读/写方式打开或新建一个文本文件,允许读和写。
|
|
at+
|
以读/写方式打开一个文本文件,允许读或在文本末追加数据。
|
|
ab+
|
以读/写方式打开一个二进制文件,允许读或在文件末追加数据。
|
I/O库函数中有不同的模式,书中9.5着重介绍了三种I/O库函数模式,分别是:字符模式I/O、行模式I/O库函数、格式化I/O库函数。下面分别学习:
①字符模式I/O
fgetc()从文件流取出下一个字节并把它作为一个字符返回,如果到达文件结尾或者出现错误的时候返回EOF。其中getchar()从标准输入读取数据。
函数原型:
#include <stdio.h>
int fgetc(FILE *stream);
fputc()函数把一个字符写道一个输出文件流中。如果成功返回写入的值,失败则返回EOF。其中puchar()函数将单个字符写道标准输出。
#include <stdio.h>
int fputc(int c, FILE *stream);
②行模式I/O
fgets()函数从输入文件流stream读取一个字符串,并把读到的字符写到ptr指向的缓冲区,当遇到如下情况停止:遇到换行符,已经传输n-1个字符,或者到达文件尾。它会把遇到的换行符也传递到接收字符串里去,再加上一个表示结尾的空字节�。
#include <stdio.h>
char *fgets(char *ptr, int n, FILE *stream);
C 库函数 int fputs(const char *str, FILE *stream) 把字符串写入到指定的流 stream 中,但不包括空字符。
int fputs(const char *str, FILE *stream)
③格式化模式I/O
这一类I/O我们应该非常熟悉了,同时这也是我们平时最常接触到的I/O了。
int printf(const char *format,….);
int fprintf(FILE *fp,const char *format,….);
int sprintf(char *buf,const char *format,…);
int snprintf(char *buf,size_t n,const char *format,…);
printf()函数是最常用的格式化输出函数,做着重分析,其原型为:
int printf( char * format, ... );
printf()会根据参数 format 字符串来转换并格式化数据,然后将结果输出到标准输出设备(显示器),直到出现字符串结束('�')为止。
参数 format 字符串可包含下列三种字符类型:
- 一般文本,将会直接输出
- ASCII 控制字符,如 、 等有特定含义
- 格式转换字符
格式转换为一个百分比符号(%)及其后的格式字符所组成。一般而言,每个%符号在其后都必需有一个参数与之相呼应(只有当%%转换字符出现时会直接输出%字符),而欲输出的数据类型必须与其相对应的转换字符类型相同。
printf()格式转换的一般形式如下:
%(flags)(width)(. prec)type
以括号括起来的参数为选择性参数,而%与type 则是必要的,下面介绍 type 的几种形式。
1) 整数
- %d 整数的参数会被转成有符号的十进制数字
- %u 整数的参数会被转成无符号的十进制数字
- %o 整数的参数会被转成无符号的八进制数字
- %x 整数的参数会被转成无符号的十六进制数字,并以小写abcdef 表示
- %X 整数的参数会被转成无符号的十六进制数字,并以大写ABCDEF 表示浮点型数
- %f double 型的参数会被转成十进制数字,并取到小数点以下六位,四舍五入
- %e double 型的参数以指数形式打印,有一个数字会在小数点前,六位数字在小数点后,而在指数部分会以小写的e 来表示
- %E 与%e 作用相同,唯一区别是指数部分将以大写的E 来表示
- %g double 型的参数会自动选择以%f 或%e 的格式来打印,其标准是根据打印的数值及所设置的有效位数来决定。
- %G 与%g 作用相同,唯一区别在以指数形态打印时会选择%E 格式。
除了上述几种模式中介绍的I/O外,书中p230 9.5.5还有许多其他有功能的I/O:
2) 字符及字符串
- %c 整型数的参数会被转成unsigned char 型打印出
- %s 指向字符串的参数会被逐字输出,直到出现NULL 字符为止
- %p 如果是参数是"void *"型指针则使用十六进制格式显示
最有收获的内容:
4.文件流缓冲
除open(), openat(), read(), write()等文件描述符相关的函数外,其他IO库函数进行IO操作的直接操作对象都是IO buffer。而且read,write等函数并不是直接从用户程序直接读写数据到磁盘而是与内核IO缓冲区交互。
C标准库的I/O缓冲区有三种类型:全缓冲、行缓冲和无缓冲。当用户程序调用库函数做写操作(读操作时I/O缓冲区是如何变化的?)时, 不同类型的缓冲区具有不同特性。
全缓冲:如果缓冲区写满了就写回内核。对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓冲区。
行缓冲:如果用户程序写的数据中有换行符就把这一行写回内核,执行真正的IO操作。标准输入和标准输出对应终端设备时通常是行缓冲的。典型代表就是键盘输入数据,每次读取一行。
无缓冲:用户程序每次调库函数做写操作都要通过系统调用写回内核。标准错误输出通常是无缓冲的,这样用户程序产生的错误信息可以尽快输出到设备。
缓冲区类型与调用的函数接口无关,于调用时指定的参数预计默认值有关;标准I/O缓存区是针对每个流的(FILE *fp),而不是针对I/O函数的
下面的是引至APUE的,实际上ISO C要求:
1.当且仅当标准输入和标准输出并不涉及交互式设备时,他们才是全缓冲的
2.标准错误输出决不是全缓冲的。
问题与解决思路:
问题1:教材中对于fopen()中的模式参数那部分的介绍较为简单,也未说fopen的参数。对于该算法的理解不够深刻。
解决方法:上博客园查找资料,学习不同的模式参数(在学习笔记中)
问题2:有关系统调用和I/O库函数各自的使用优势还不能熟练掌握。
解决方法2:询问同寝室的同学,最终明白了系统调用,只需要一次复制,就可以完成任务,而I/O库函数需要两次复制,即从内核到内部缓冲区再到程序缓冲区
实践代码:
void main()
{
FILE *fp;
int c;
fp=fopen("exist","r");
while((c=fgetc(fp))!=EOF)
printf("%c",c);
fclose(fp);
}

结构化的知识:
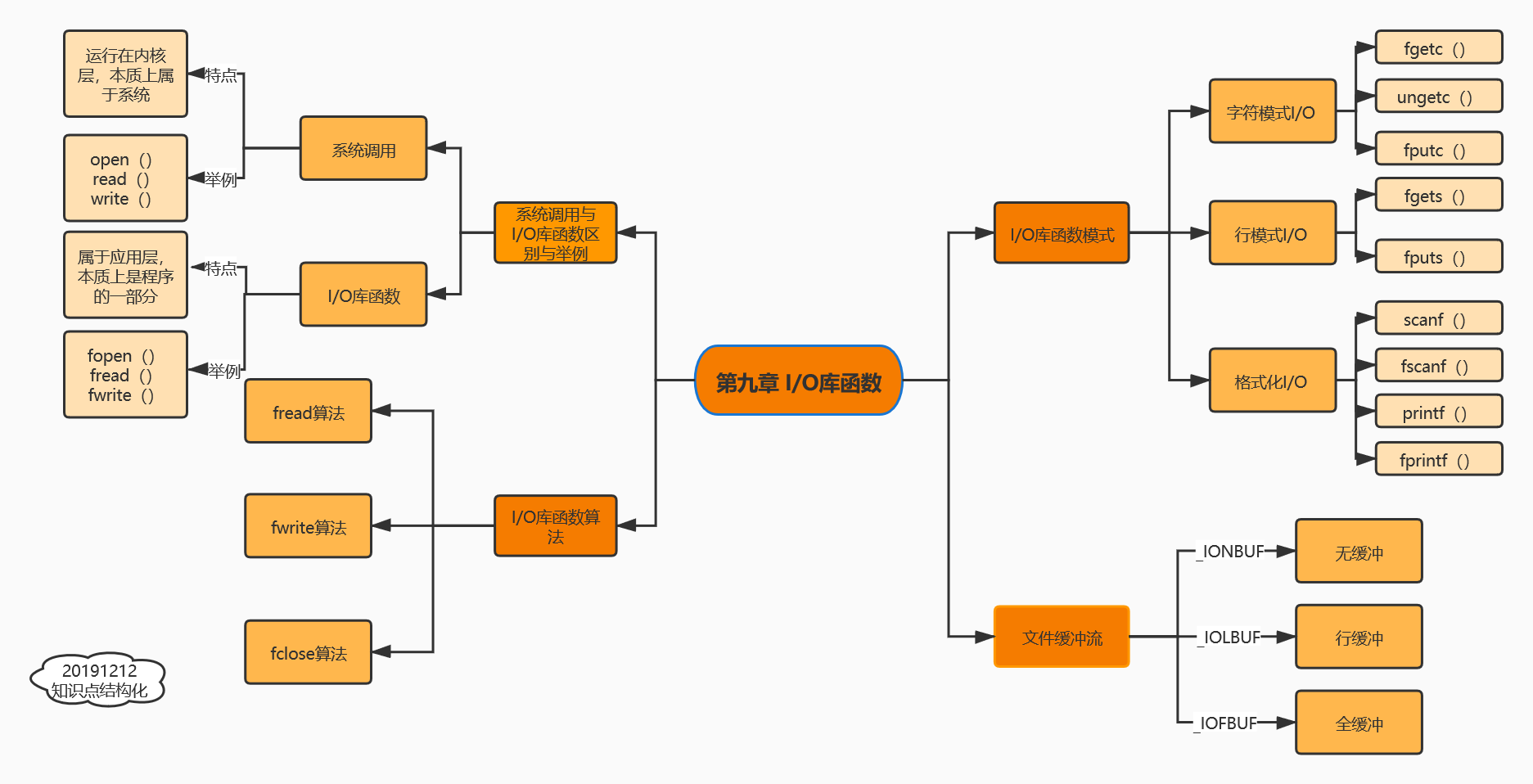
总结:
这一章的内容主要是以I/O库函数展开,系统地阐述了C语言的文件操作。经过这一章大的学习,我了解了系统调用与C语言库函数之间的联系与区别,以及几种模式的C语言库函数,在9.6中,我学习了无缓冲、行缓冲、全换冲三种缓冲流。整个第九章与大一下学习的C语言联系在了一起,学习以后我的知识体系更加完善了。