算法流程图
- Q-learning

- SARSA

- 对比:Q-learning算法根据当前状态 S 选择执行一个动作A,执行后观测执行后的奖励和转移到的状态S1。在状态S1下计算采取哪个a可以获得最大的Q值,并没有真的采取这个a。Q-learning选择到新状态之后能够得到的最大的Q值来更新当前的Q值。
而Sarsa是转移到动作S1时,真的采取了动作A1。然后根据Q(S1,A1)来更新Q值。 - Q值更新对比:
Sarsa:动作a的选取遵循e-greedy策略,目标Q值的计算也是根据(e-greedy)策略得到的动作a'计算得来
Q-learning:动作a的选取遵循e-greedy策略,目标Q值的计算也是根据(e-greedy)策略得到的动作a'计算得来
代码实现:
SARSA:
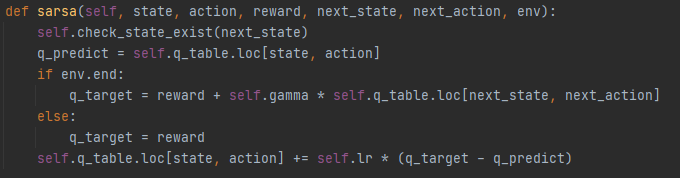
代码需要的参数有:状态,选择的动作,带来的奖励,下一个状态,下一个动作。
代码步骤:
-
检测下一个状态是否存在于Q表中,如果不在的话就插入一个以下一个状态为索引的Series。
-
算出Q表中的当前状态和当前动作的Q值q_predict
-
如果当前状态是结束状态,q_target等于执行动作后的奖励+γ*下一个状态和下一个动作的Q值。
-
否则q值等于奖励
-
更新Q表,q值=当前Q值+学习率lr*(q_target-q_predict)
理解:根据当前状态和选择的动作找到现在的Q表。根据下一个状态和下一个动作找到Q值1.用Q值1和当前Q值来更新目前Q值。
Q-learning:
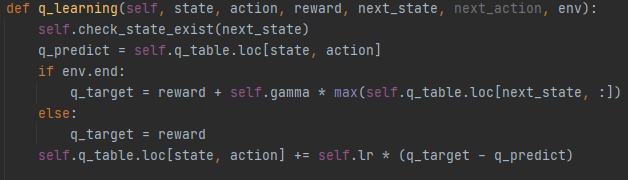
代码需要的参数有:状态,选择的动作,带来的奖励,下一个状态。
代码步骤: -
检测下一个状态是否存在于Q表中,如果不在的话就插入一个以下一个状态为索引的Series。
-
算出Q表中的当前状态和当前动作的Q值q_predict
-
如果当前状态是结束状态,q_target等于执行动作后的奖励+γ*下一个状态中最大的Q值。
-
否则Q值等于奖励
-
更新Q表,q值=当前Q值+学习率lr*(q_target-q_predict)