This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees Vs SVM: Part I
In this part we’ll discuss how to choose between Logistic Regression , Decision Trees and Support Vector Machines. The most correct answer as mentioned in the first part of this 2 part article , still remains it depends. We’ll continue our effort to shed some light on, it depends on what. All three of these techniques have certain properties inherent by their design, we’ll elaborate on some in order to provide you with few pointers on their selection for your particular business problem.
We’ll start with Logistic Regression , the most prevalent algorithm for solving industry scale problems, although its losing ground to other techniques with progress in efficiency and implementation ease of other complex algorithms.
A very convenient and useful side effect of a logistic regression solution is that it doesn’t give you discrete output or outright classes as output. Instead you get probabilities associated with each observation. You can apply many standard and custom performance metrics on this probability score to get a cutoff and in turn classify output in a way which best fits your business problem. A very popular application of this property is scorecards in the financial industry ,where you can adjust your threshold [cutoff ] to get different results for classification from the same model. Very few other algorithms provide such scores as a direct result. Instead their outputs are discreet direct classifications. Also, logistic regression is pretty efficient in terms of time and memory requirement. It can be applied on distributed data and it also has online algorithm implementation to handle large data on less resources.
In addition to above , logistic regression algorithm is robust to small noise in the data and is not particularly affected by mild cases of multi-collinearity. Severe cases of multi-collinearity can be handled by implementing logistic regression with L2 regularization, although if a parsimonious model is needed , L2 regularization is not the best choice because it keeps all the features in the model.
Where logistic regression starts to falter is , when you have a large number of features and good chunk of missing data. Too many categorical variables are also a problem for logistic regression. Another criticism of logistic regression can be that it uses the entire data for coming up with its scores. Although this is not a problem as such , but it can be argued that “obvious” cases which lie at the extreme end of scores should not really be a concern when you are trying to come up with a separation curve. It should ideally be dependent on those boundary cases, some might argue. Also if some of the features are non-linear, you’ll have to rely on transformations, which become a hassle as size of your feature space increases. We have picked few prominent pros and cons from our discussion to summaries things for logistic regression.
Logistic Regression Pros:
- Convenient probability scores for observations
- Efficient implementations available across tools
- Multi-collinearity is not really an issue and can be countered with L2 regularization to an extent
- Wide spread industry comfort for logistic regression solutions [ oh that’s important too!]
Logistic Regression Cons:
- Doesn’t perform well when feature space is too large
- Doesn’t handle large number of categorical features/variables well
- Relies on transformations for non-linear features
- Relies on entire data [ Not a very serious drawback I’d say]
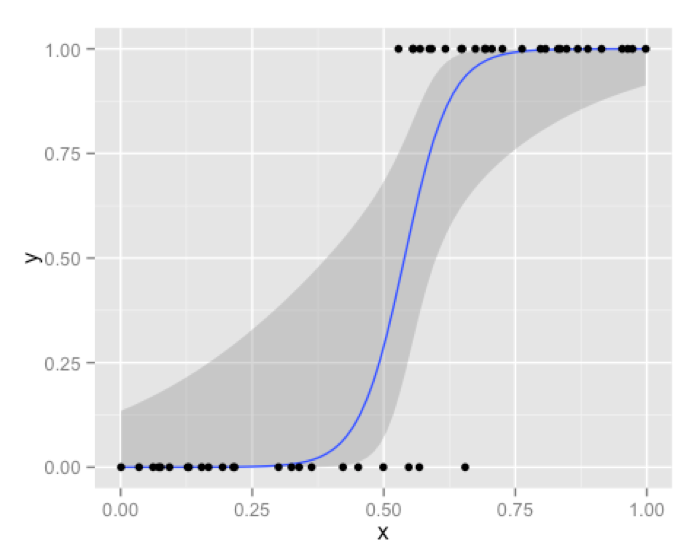
Let’s discuss Decision Trees and Support Vector Machines .
Decision trees are inherently indifferent to monotonic transformation or non-linear features [ this is different from non linear correlation among predictors] because they simply cut feature space in rectangles [ or (hyper)cuboids] which can adjust themselves to any monotonic transformation. Since decision trees anyway are designed to work with discrete intervals or classes of predictors, any number of categorical variables are not really an issue with decision trees. Models obtained from decision tree is fairly intuitive and easy to explain to business. Probability scores are not a direct result but you can use class probabilities assigned to terminal nodes instead. This brings us to the biggest problem associated with Decision Trees, that is, they are highly biased class of models. You can make a decision tree model on your training set which might outperform all other algorithms but it’ll prove to be a poor predictor on your test set. You’ll have to rely heavily on pruning and cross validation to get a non-over-fitting model with Decision Trees.
This problem of over-fitting is overcome to large extent by using Random Forests, which are nothing but a very clever extension of decision trees. But random forest take away easy to explain business rules because now you have thousands of such trees and their majority votes to make things complex. Also by decision trees have forced interactions between variables , which makes them rather inefficient if most of your variables have no or very weak interactions. On the other hand this design also makes them rather less susceptible to multicollinearity. Whew!
Summarizing Decision Trees:
Decision Trees Pros:
- Intuitive Decision Rules
- Can handle non-linear features
- Take into account variable interactions
Decision Trees Cons:
- Highly biased to training set [Random Forests to your rescue]
- No ranking score as direct result
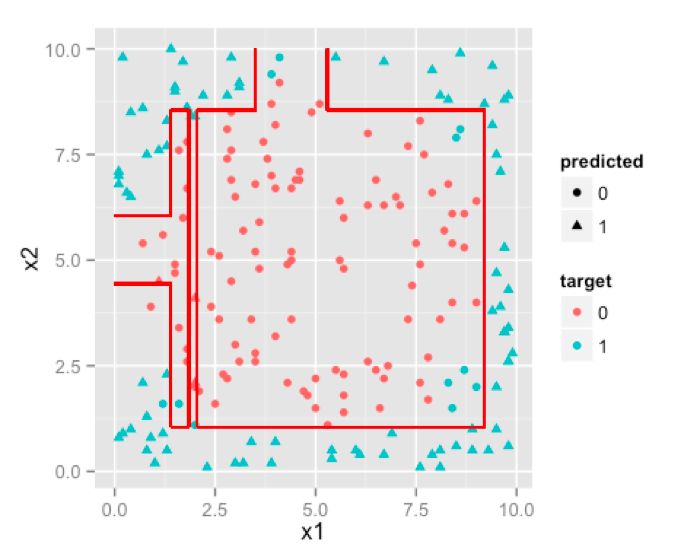
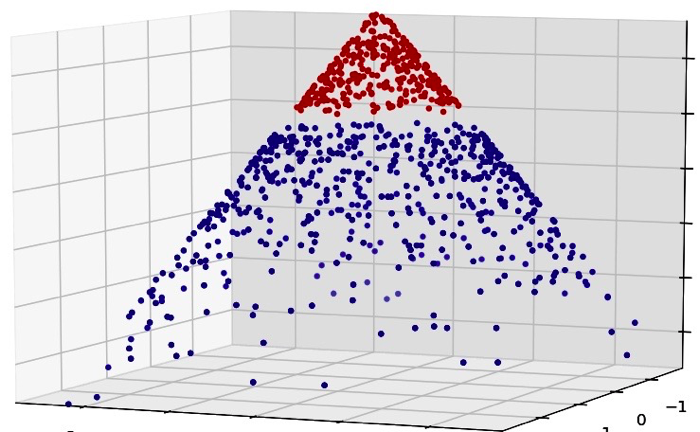
Now to Support Vector Machines. The best thing about support vector machines is that they rely on boundary cases to build the much needed separating curve. They can handle non linear decision boundaries as we saw earlier. Reliance on boundary cases also enables them to handle missing data for “obvious” cases. SVM can handle large feature spaces which makes them one of the favorite algorithms in text analysis which almost always results in huge number of features where logistic regression is not a very good choice.
Result of SVMs are not as not as intuitive as decision trees for a layman. With non linear kernels, SVMs can be very costly to train on huge data. In Summary:
SVM Pros:
- Can handle large feature space
- Can handle non-linear feature interactions
- Do not rely on entire data
SVM Cons:
- Not very efficient with large number of observations
- It can be tricky to find appropriate kernel sometimes
I have tried to compile a simple workflow for you to decide which algorithm to use out of these three, which is as follows:
- Always start with logistic regression, if nothing then to use the performance as baseline
- See if decision trees (Random Forests) provide significant improvement. Even if you do not end up using the resultant model, you can use random forest results to remove noisy variables
- Go for SVM if you have large number of features and number of observations are not a limitation for available resources and time
At the end of the day, remember that good data beats any algorithm anytime. Always see if you can engineer a good feature by using your domain knowledge. Try various iterations of your ideas while experimenting with feature creation. Another thing to try with efficient computing infra available these days is to use ensembles of multiple models. We’ll discuss them next, so, stay tuned!
/**************************************************************************/
在这篇文章,我们将讨论如何在逻辑回归、决策树和SVM之间做出最佳选择。其实 第一篇文章已经给出了很好的回答,不过在这里再补充一些。下面将继续深入讨论这个主题。事实上,这三个算法在其设计之初就赋予了一定的内部特性,我们将其分析透彻的主要目的在于:当你面临商业问题时,这些算法的特性可以让你在选择这些算法时得到一些灵感。
首先,我们来分析下逻辑回归(Logistic Regression),它是解决工业规模问题最流行的算法,尽管与其他技术相比,其在效率和算法实现的易用性方面并不出众。
逻辑回归非常便利并且很有用的一点就是,它输出的结果并不是一个离散值或者确切的类别。相反,你得到的是一个与每个观测样本相关的概率列表。你可以使用不同的标准和常用的性能指标来分析这个概率分数,并得到一个阈值,然后使用最符合你业务问题的方式进行分类输出。在金融行业,这种技术普遍应用于记分卡中,对于同一个模型,你可以调整你的阈值【临界值】来得到不同的分类结果。很少有其它算法使用这种分数作为直接结果。相反,它们的输出是严谨的直接分类结果。同时,逻辑回归在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。
除此之外,逻辑回归算法对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,不过如果要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。
当你的特征数目很大并且还丢失了大部分数据时,逻辑回归就会表现得力不从心。同时,太多的类别变量对逻辑回归来说也是一个问题。逻辑回归的另一个争议点是它使用整个数据来得到它的概率分数。虽然这并不是一个问题,但是当你尝试画一条分离曲线的时候,逻辑回归可能会认为那些位于分数两端“明显的”数据点不应该被关注。有些人可能认为,在理想情况下,逻辑回归应该依赖这些边界点。同时,如果某些特征是非线性的,那么你必须依靠转换,然而当你特征空间的维数增加时,这也会变成另一个难题。所以,对于逻辑回归,我们根据讨论的内容总结了一些突出的优点和缺点。
逻辑回归的优点:
- 便利的观测样本概率分数;
- 已有工具的高效实现;
- 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决;
- 逻辑回归广泛的应用于工业问题上(这一点很重要)。
逻辑回归的缺点:
- 当特征空间很大时,逻辑回归的性能不是很好;
- 不能很好地处理大量多类特征或变量;
- 对于非线性特征,需要进行转换;
- 依赖于全部的数据(个人觉得这并不是一个很严重的缺点)。

下面让我们来讨论下决策树和支持向量机。
决策树固有的特性是它对单向变换或非线性特征并不关心[这不同于预测器当中的非线性相关性>,因为它们简单地在特征空间中插入矩形[或是(超)长方体],这些形状可以适应任何单调变换。当决策树被设计用来处理预测器的离散数据或是类别时,任何数量的分类变量对决策树来说都不是真正的问题。使用决策树训练得到的模型相当直观,在业务上也非常容易解释。决策树并不是以概率分数作为直接结果,但是你可以使用类概率反过来分配给终端节点。这也就让我们看到了与决策树相关的最大问题,即它们属于高度偏见型模型。你可以在训练集上构建决策树模型,而且其在训练集上的结果可能优于其它算法,但你的测试集最终会证明它是一个差的预测器。你必须对树进行剪枝,同时结合交叉验证才能得到一个没有过拟合的决策树模型。
随机森林在很大程度上克服了过拟合这一缺陷,其本身并没有什么特别之处,但它却是决策树一个非常优秀的扩展。随机森林同时也剥夺了商业规则的易解释性,因为现在你有上千棵这样的树,而且它们使用的多数投票规则会使得模型变得更加复杂。同时,决策树变量之间也存在相互作用,如果你的大多数变量之间没有相互作用关系或者非常弱,那么会使得结果非常低效。此外,这种设计也使得它们更不易受多重共线性的影响。
决策树总结如下:
决策树的优点:
- 直观的决策规则
- 可以处理非线性特征
- 考虑了变量之间的相互作用
决策树的缺点:
- 训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
- 没有将排名分数作为直接结果

现在来讨论下支持向量机(SVM, Support Vector Machine)。支持向量机的特点是它依靠边界样本来建立需要的分离曲线。正如我们 之间看到的那样,它可以处理非线性决策边界。对边界的依赖,也使得它们有能力处理缺失数据中“明显的”样本实例。支持向量机能够处理大的特征空间,也因此成为文本分析中最受欢迎的算法之一,由于文本数据几乎总是产生大量的特征,所以在这种情况下逻辑回归并不是一个非常好的选择。
对于一个行外人来说,SVM的结果并不像决策树那样直观。同时使用非线性核,使得支持向量机在大型数据上的训练非常耗时。总之:
SVM的优点:
- 能够处理大型特征空间
- 能够处理非线性特征之间的相互作用
- 无需依赖整个数据
SVM的缺点:
- 当观测样本很多时,效率并不是很高
- 有时候很难找到一个合适的核函数
为此,我试着编写一个简单的工作流,决定应该何时选择这三种算法,流程如下:
- 首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考;
- 然后试试决策树(随机森林)是否可以大幅度提升模型性能。即使你并没有把它当做最终模型,你也可以使用随机森林来移除噪声变量;
- 如果特征的数量和观测样本特别多,那么当资源和时间充足时,使用SVM不失为一种选择。

最后,大家请记住,在任何时候好的数据总要胜过任何一个算法。时常思考下,看看是否可以使用你的领域知识来设计一个好的特征。在使用创建的特征做实验时,可以尝试下各种不同的想法。此外,你还可以尝试下多种模型的组合。这些我们将在下回讨论,所以,整装待发吧!