
Job, Task, and Task Attempt IDs
In Hadoop 2, MapReduce job IDs are generated from YARN application IDs that arecreated by the YARN resource manager.
The format of an application ID is composedof the time that the resource manager (not the application) started and an incrementingcounter maintained by the resource manager to uniquely identify the application to that instance of the resource manager.
So the application with this ID:
appllcation_1410450250506_0003
is the third (0003; application IDs are 1 -based) application run by the resource manager,which started at the time represented by the timestamp 1410450250506.
The counter is formatted with leading zeros to make IDs sort nicely —in directory listings, for example.
However, when the counter reaches 10000, it is not reset, resulting in longer application IDs (which don’t sort so well). The corresponding job ID is created simply by replacing the application prefix of an application ID with a job prefix:
job_1410450250506_0003
Tasks belong to a job, and their IDs are formed by replacing the job prefix of a job ID with a task prefix and adding a suffix to identify the task within the job. For example:
task_1410450250506_0003_n_000003
is the fourth (000003; task IDs are 0-based) map (n) task of the job with ID job_1410450250506_0003. The task IDs arc created for a job when it is initialized, so they do not necessarily dictate the order in which the tasks will be executed. Tasks may be executed more than once, due to failure (see MTask FailurcM on page 193) or speculative execution (see speculative Execution" on page 204), so to identify different instances of a task execution, task attempts are given unique IDs. For example:
attenpt_1410450256506_0003_n_000003_0
is the first (0; attempt IDs are O-based) attempt at running task
task_141045O250506_O003_m_000003.
Task attempts arc allocated during the job run as needed, so their ordering represents the order in which they were created to run.
简而言之,就是当yarn application id超过了4位数的范围,也就是达到10000后,yarn直接做增加位数操作,来扩展id空间范围。同时官方承认,这会导致根据id排序结果出现偏差。
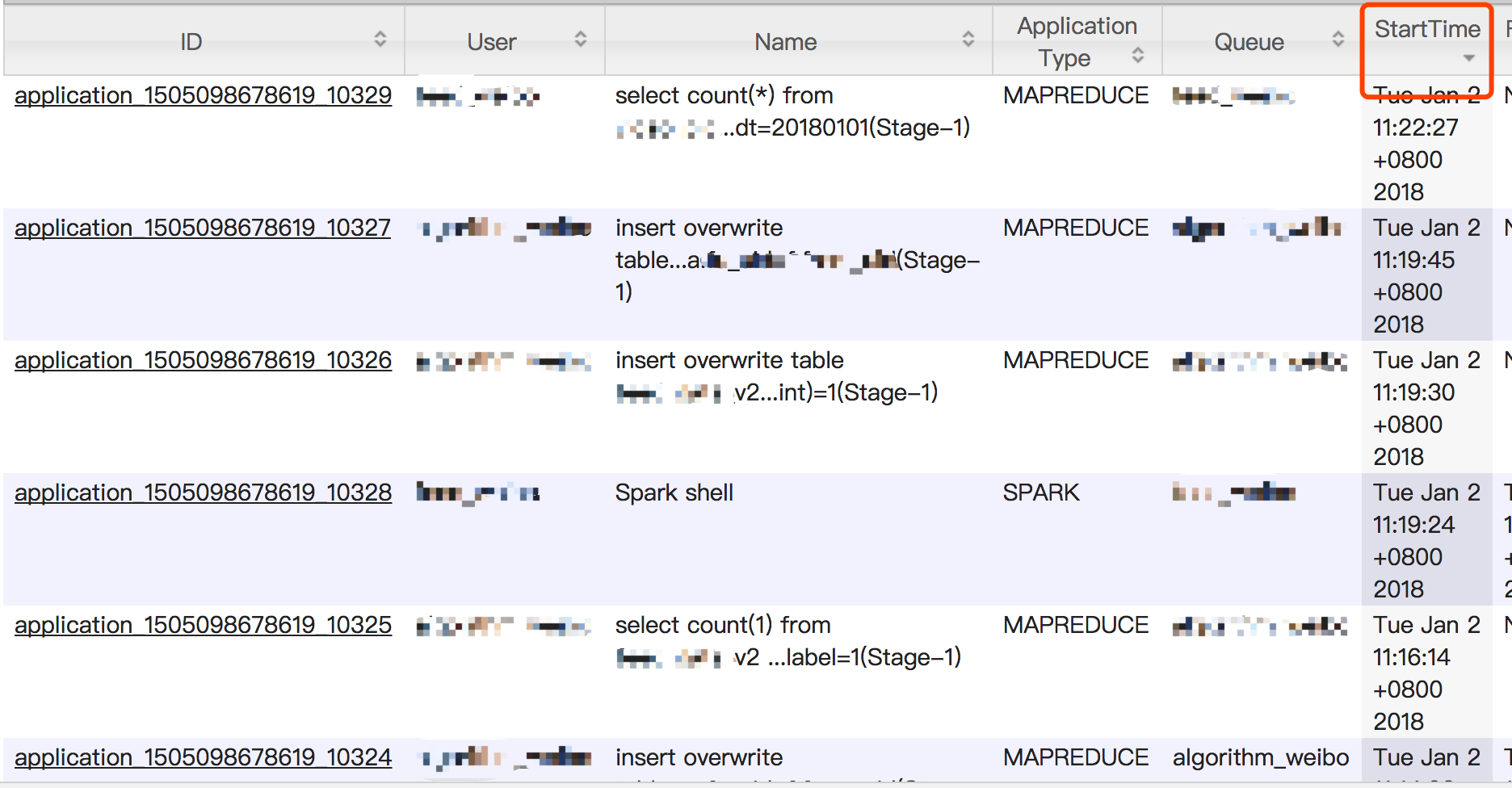
2018-01-02,实际截图补充:
按提交时间排序:
按照id排序:
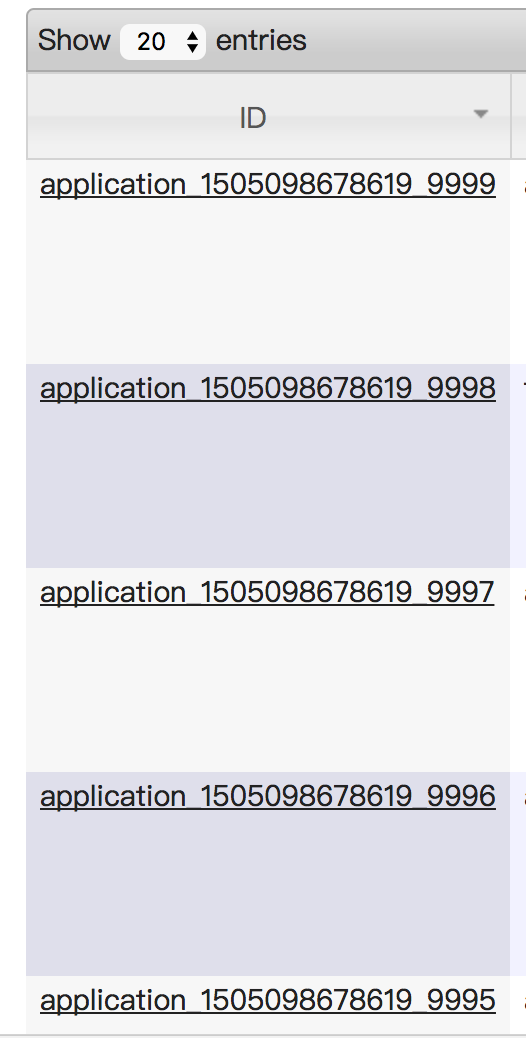
yarn application Id在到达10000后,会通过增加位数来扩展id空间容量,但这会导致页面按照ID进行排序结果出现偏差。