启动hdfs时,有时候可能会遇到这样几种情况:
1)在主节点上执行start-dfs.sh命令启动hdfs,无法启动datanode。
2)在主节点上行启动hdfs,启动成功了,在各个节点上使用jps命令也能查询到相应的SecondaryNameNode、NameNode和DataNode进程,但是通过5007页面上却查询不到datanode,或者执行hdfs dfsadmin -report(hadoop dfsadmin -report)命令是显示available datanode个数为0;
一、第一种情况
我没遇到过这种情况,不过我感觉第一步应该是先去看namenode的日志(日志在namenode节点的$HADOOP_HOME/logs目录下),另外也可以从以下几个方面排查问题:
1)看一下slaves文件有没有配置正确
2)检查从namenode节点到datanode节点的免密登录是否配置正确;
3)测试一下从namenode上能否ping通datanode,datanode节点的防火墙有没有关(或者如果你的本意就是不关闭防火墙,而是只给hadoop开启特定的端口的话,那就使用telnet命令检查一下从namenode节点到datanode节点的特定端口能不能连接上)
4)还有一种比较特殊的情况,就是你的namenode和datanode节点上,用于安装hadoop环境的用户不一样,比如在namenode节点上用u1用户安装hadoop环境,而在datanode节点上则是用u2用户安装的hadoop环境。这种时候就会有问题,因为当你在namenode上启动hdfs时,肯定是用u1用户执行的命令(因为你是用u1用户安装的hadoop嘛,环境变量是配在这个用户下的),那么当namenode节点要远程登录到datanode节点上去启动datanode时,namenode默认是会使用当前用户也就是u1用户去登录datanode节点的,这个时候就会出错,因为datanode节点上没有u1用户,根本无法登录上datanode,更别说去启动datanode了。对于这个问题,我在网上偶然看到有人的解决方法是在配置masters和slaves时,不单单是写IP(比如192.168.137.22),而是要写上用户名,比如“u2@192.168.137.22”。正如我所说的,这是个比较特殊的问题,最好还是将hadoop集群的所有节点的安装用户保持一致。另外我感觉如果集群中的不同节点是用不同用户来安装hadoop环境的话,根本无法安装成功,虽然我在网上看到有朋友说他这么安装也成功了……我觉得无法安装成功是因为,这么来安装hadoop集群环境的话,首先namenode节点到datanode节点的免密登录就没法配置,因为在namenode节点上是以u1用户生成的公钥,因此在namenode节点上无法以u2用户的身份免密登录datanode节点——额…至少以我目前了解的ssh免密登录设置的知识来说是不行的…………
二、第二种情况
就我遇到错误,下面记录一下,错误从datanode的日志中可以查看到(日志在datanode节点的$HADOOP_HOME/logs目录下)
1)INFO org.apache.hadoop.ipc.RPC: Server at node1/192.168.137.21:9000 not available yet, Zzzzz...
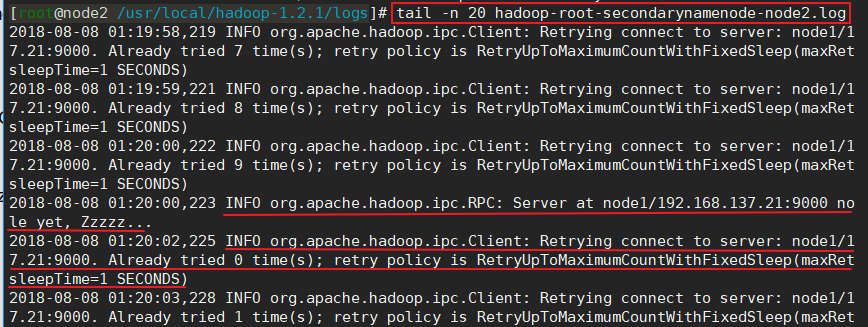
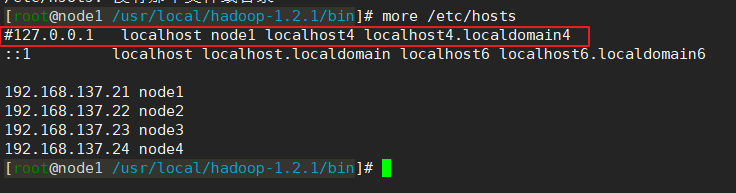
目前我在hadoop1.2.1版本中遇到过这个问题,在hadoop二点几版本中暂时没遇到过。该问题的解决可参考《org.apache.hadoop.ipc.Client: Retrying connect to server异常的解决》,不过我的解决方法跟这篇博文有些许不一样,我只将hdfs主节点的/etc/hosts文件中的“127.0.0.1 主节点主机名”这一行给注释掉(如下图),然后重启hdfs集群就可以了,不需要每个节点都做修改,并且我也没有重新格式化hdfs。因为我感觉从datanode日志上可以看出,是datanode去连接namenode节点时出现了问题,datanode节点去解析namenode的hosts文件时解析不正确了,所以才导致问题的发生,跟datanode节点的hosts文件应该是没有关系的。并且不用重新格式化是因为我感觉……不知道怎么说,总之感觉还是……没关系…………
2)java.io.IOException: Incompatible clusterIDs in /usr/local/hadoop/tmp/dfs/data: namenode clusterID = CID-8e201022-6faa-440a-b61c-290e4ccfb006; datanode clusterID = clustername
这个问题我遇到的时候没有留下截图,后面由于其他原因导致集群启动不成功之后上网找解决方法时恰好看到有人贴出来了,所以也记录一下。
出现该问题是因为hdfs格式化次数太多了出了问题,导致子节点的cluster_id跟主节点的cluster_id不一致,所以导致子节点无法向主节点发送心跳信息,那么对主节点来说,该子节点就是dead的了。
这个问题的解决方法参考《Hadoop安装遇到的各种异常及解决办法》中的第二点异常。
3)这也是个没有保留出错日志信息的问题。出错是因为我的子节点的core-site.xml文件中fs.defaultFS项配置错了。
所以如果遇到了“datanode节点启动成功,但是namenode节点却检测不到该datanode”的情况时,可以检查一下此项配置,因为core-site.xml文件中的fs.defaultFS项配置就是记录集群中namenode节点的位置,如果配置错了,datanode就无法向正确的namenode节点发送心跳信息,namenode自然感知不到该datanode的存在了。
暂时记录这么多了……