深层神经网络
深度学习有两个非常重要的特性——多层和非线性
线性模型的最大特点是任意线性模型的组合仍然还是线性模型
激活函数实现去线性化
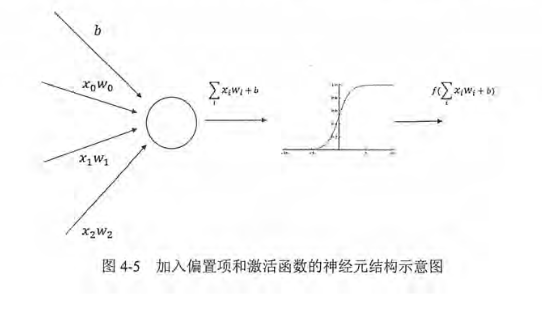
加入激活函数和偏置项后的前向传播算法的数学定义:
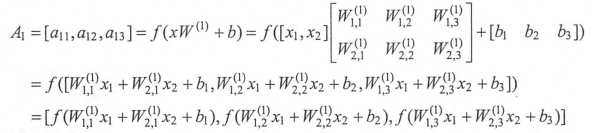
加入了偏置项,也不是传统的单纯加权和,每个节点在加权和基础上还做了一个非线性变换
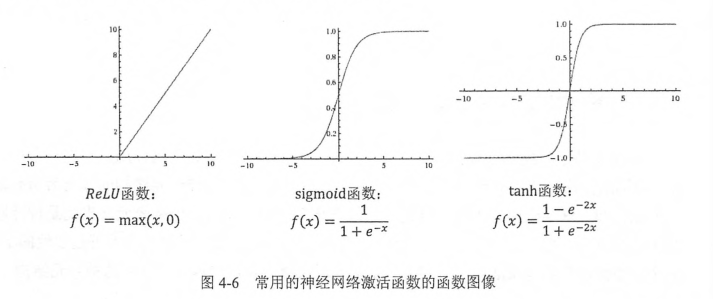
这些激活函数的图像都不是一条直线,所以通过这些激活函数,每一个节点不再是线性变换,于是整个神经网络模型也就不再是线性的
使用非线性激活函数实现神经网络的前向传播算法
a = tf.nn.relu(tf.matmul(x,w1),biases1)
y = tf.nn.relu(tf.matmul(a,w2),biases2)
经典损失函数
分类问题
通过神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数,对于每一个样例,神经网络可以得到一个n维数组作为输出结果,数组中的每一个维度对应一个类别,在理想情况下,如果一个样本属于类别k,那么这个类别所对应的输出节点输出值为1,而其他节点输出值为0,神经网络模型的输出越接近[0,0,0,0,0,1,0,0]越好。如何判断一个输出的向量和期望的向量有多接近?交叉熵是常用的评判方法之一。交叉熵刻画了两个概率分部之间的距离
交叉熵原本是用来估算平均编码长度,给定两个概率分布p和q
通过q来表示p的交叉熵为:
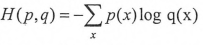
交叉熵刻画的是两个概率分布之间的距离,然而神经网络的输出却不一定是一个概率分布
将分类问题中“一个样例属于某一个类别”看成是一个概率事件,那么训练数据的正确答案就符合一个概率分布
Softmax回归经常用来把神经网络前向传播得到的结果也变成概率分布
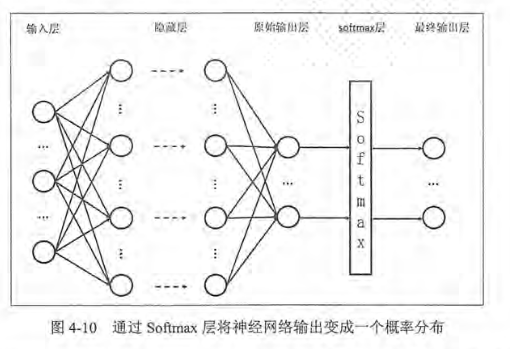
softmax回归本身可以作为一个学习算法来优化分类结果,但在Tensorflow中,softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布
假设原始的神经网络输出为y1,y2,y3...yn,经过Softmax回归处理后的结果为:
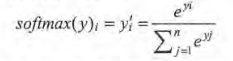
从上面公式可以看出,原始神经网络的输出被用作置信度来生成新的输出,而新的输出满足概率分布的所有要求。这个新的输出可以理解为经过神经网络的推导,一个样例为不同分布的概率是多少,这样就把神经网络的输出也变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离。
从交叉熵的公式上来看 ,交叉熵函数是不对称的(H(p,q)不等于H(q,p)),他刻画的是通过概率分布q来表达概率分布p的困难程度,因为正确答案是希望得到的结果,所以当交叉熵作为神经网络的损失函数时,p代表的是正确答案,q代表的是预测值。交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
假设有一个三分类问题,某个样例的正确答案是(1,0,0),经过模型通过softmax之后的预测答案是(0.5,0.4,0.1),那么这个预测和正确答案之间的交叉熵是
H((1,0,0),(0.5,0.4,0.1)) = -(1*log0.5+0) = 0.3
另一个的预测值时(0.8,0.1,0.1)
H((1,0,0),(0.8,0.1,0.1)) = -(1*log0.8) = 0.1
通过Tensorflow实现交叉熵
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
y_表示正确结果 y代表预测结果 tf.clip_by_value函数将一个张量中的数值限制在一个范围内,这样可以避免运算错误(log0无效)
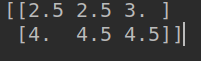
import tensorflow as tf #定义常量 v = tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]]) sess = tf.Session() print(tf.clip_by_value(v,2.5,4.5).eval(session =sess))
将v中数据上限设置到4.5 下限设置到2.5
第二个函数 tf.log这个函数依次对张量中所有元素依次求对数
第三个是乘法元素直接相乘 如果是矩阵相乘则需要通过tf.matmul函数来完成
import tensorflow as tf #定义常量 v = tf.constant([[1.0,2.0],[4.0,5.0]]) s = tf.constant([[3.0,4.0],[1.0,2.0]]) sess = tf.Session() m = v*s mut = tf.matmul(v,s) print(m.eval(session =sess)) print(mut.eval(session=sess))
上述三个运算将得到一个n*m的二维矩阵,其中n为一个batch中样例的数量,m为分类类别的数量,根据交叉熵的公式,应该将每行中的m个结果相加得到所有样例的交叉熵,再对这n行取平均得到一个batch的平均交叉熵,但因为分类问题的类别数量是不变的,所以对整个矩阵求平均并不改变计算结果的意义。
交叉熵一般会与softmax一起使用 可以通过如下代码直接实现Softmax回归之后的交叉熵损失函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)
其中y代表了原始神经网络的输出结果 而y_给出了标准答案
回归问题
与分类问题不同,回归问题解决的是对具体数值的预测。
解决回归问题的神经网络一般只有一个输出节点,这个节点的输出值就是预测值,对于回归问题,常用的损失函数是均方误差(MSE)。
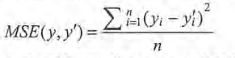
yi为一个batch中第i个数据的正确答案 yi‘为神经网络给出的预测值
mse = tf.reduce_mean(tf.square(y_-y))