一、安装pt工具
二、慢查询日志整理
pt-query-digest --since '2017-09-20 00:00:00' --until '2017-09-21 00:00:00' mysql_slow_query.log > 920
三、在线执行DDL操作 不锁表
pt-online-schema-change --user=user --ask-pass --host=10.0.201.34 --alter "DROP KEY cid, ADD KEY idx_corpid_userid(f_corp_id,f_user_id) " D=confluence,t=sbtest3 --print --execute
四、慢查询分析过程
1、查看表结构、数据量和索引情况
show create table a;
select count(*) from a;
show index a;
2、查询trace_sn字段在表wt_abc_detail中数据的比例,选取最高的添加索引
select count(distinct id)/count(1) from a;
3、添加索引
alter table a add index idx_id(id)
4、explain查看执行计划
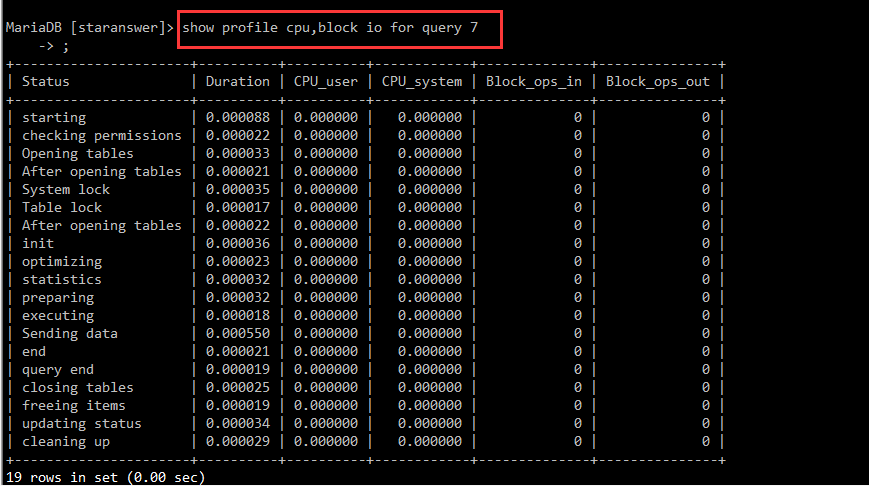
5、利用profile查看资源占用情况
#查看profiling 是否开启 show variables like '%prof%' #开启profile set profiling=on; #查找要分析的语句编号 show profiles; #分析语句资源开销,可看到哪里执行时间最长 show profile cpu,block io for query 28;
例:

三、索引添加原则
3.1 不能使用索引的情况
- LIKE:只有后边带%才会用索引,前边或者前后都带的索引不生效(LIKE '%275024%',此时不生效)
- !=:无法使用索引
- OR:需要给字段单独添加索引,否则不生效
- 索引列上有函数运算或隐式转换,导致不走索引; 如SELECT * FROM T WHERE date_format(Y) = XXX ,这时会先遍历T表Y列转换时间格式,同理函数会先遍历运算,导致用不上索引; 可以为函数加函数索引。
- 有NULL值时使用count(*)
- NOT IN 无法使用索引,最好改成IN
3.2 复合索引注意筛选最左列
引导列要选择过滤条件的列作为引导列,比如 where a.xxx='xxx' 或者 a.xxx> 或者 a.xxx< 引导列的选择性越高越好,因为选择性越高,扫描的leaf block就越少,效率就越高 (正确的顺序依赖于使用该索引的查询,并且同时需要考虑如何更好的满足排序和分组的需要。在一个多列B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的ORDER BY、GROUP BY和DISTINCT等子句的查询需求。对于如何选择索引顺序有一个经验法则:将选择性较高的列放到索引的最前列。) 尽量把join列放到组合索引最后面
3.3 join
join要保证小表驱动大表原则,如果查询计划显示大表驱动小表,可通过添加索引等方式变更驱动顺序