一、编程环境
以下为Mac系统上单机版Spark练习编程环境的配置方法。
注意:仅配置练习环境无需安装Hadoop,无需安装Scala。
1,安装Java8
注意避免安装其它版本的jdk,否则会有不兼容问题。
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2,下载spark并解压
http://spark.apache.org/downloads.html
解压到以下路径:
Users/yourname/ProgramFiles/spark-2.4.3-bin-hadoop2.7
3,配置spark环境
vim ~/.bashrc
插入下面两条语句
export SPARK_HOME=/Users/yourname/ProgramFiles/spark-2.4.3-bin-hadoop2.7export PATH=$PATH:$SPARK_HOME/bin
4,配置jupyter支持
若未有安装jupyter可以下载Anaconda安装之。使用toree可以安装jupyter环境下的Apache Toree-Scala内核,以便在jupyter环境下运行Spark。
pip install toreejupyter toree install --spark_home=Users/yourname/ProgramFiles/spark-2.4.3-bin-hadoop2.7
二、运行Spark
Spark可以通过以下一些方式运行。
1,通过spark-shell进入Spark交互式环境,使用Scala语言。
2,通过spark-submit提交Spark应用程序进行批处理。
这种方式可以提交Scala或Java语言编写的代码编译后生成的jar包,也可以直接提交Python脚本。
3,通过pyspark进入pyspark交互式环境,使用Python语言。
这种方式可以指定jupyter或者ipython为交互环境。
4,通过zepplin notebook交互式执行。
zepplin是jupyter notebook的apache对应产品。
5,安装Apache Toree-Scala内核。
可以在jupyter 中运行spark-shell。
使用spark-shell运行时,还可以添加两个常用的两个参数。
一个是master指定使用何种分布类型。
第二个是jars指定依赖的jar包。
#local本地模式运行,默认使用4个逻辑CPU内核spark-shell#local本地模式运行,使用全部内核,添加 code.jar到classpathspark-shell --master local[*] --jars code.jar#local本地模式运行,使用4个内核spark-shell --master local[4]#standalone模式连接集群,指定url和端口号spark-shell --master spark://master:7077#客户端模式连接YARN集群,Driver运行在本地,方便查看日志,调试时推荐使用。spark-shell --master yarn-client#集群模式连接YARN集群,Driver运行在集群,本地机器计算和通信压力小,批量任务时推荐使用。spark-shell --master yarn-cluster
#提交scala写的任务--master yarn--deploy-mode cluster--driver-memory 4g--executor-memory 2g--executor-cores 1--queue thequeueexamples/jars/spark-examples*.jar 10
#提交python写的任务--executor-memory 6G--driver-memory 6G--deploy-mode cluster--num-executors 600--conf spark.yarn.maxAppAttempts=1--executor-cores 1--conf spark.default.parallelism=2000--conf spark.task.maxFailures=10--conf spark.stage.maxConsecutiveAttempts=10test.py
三、创建RDD
创建RDD的基本方式有两种,第一种是使用textFile加载本地或者集群文件系统中的数据。第二种是使用parallelize方法将Driver中的数据结构并行化成RDD。
1,textFile
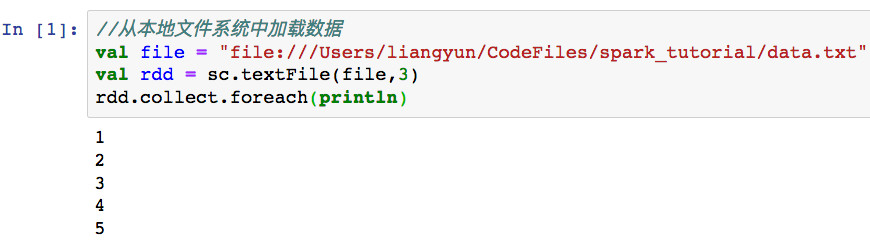

2,parallelize(或makeRDD)

四、常用Action操作
Action操作将触发基于RDD依赖关系的计算。
1,collect

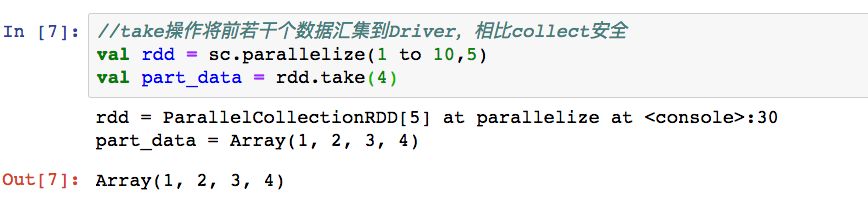
2,take

3,takeSample
4,first

5,count
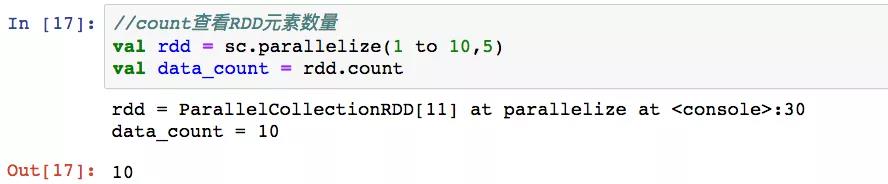
6,reduce

7,foreach

8,coutByKey

9,saveAsFile

五、常用Transformation操作
Transformation转换操作具有懒惰执行的特性,它只指定新的RDD和其父RDD的依赖关系,只有当Action操作触发到该依赖的时候,它才被计算。
1,map

2,filter

3,flatMap

4,sample

5,distinct

6,subtract

7,union

8,intersection

9,cartesian

10,sortBy

11,pipe

六、常用PairRDD转换操作
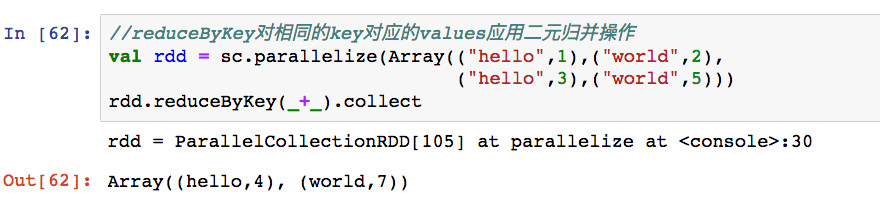
PairRDD指的是数据为Tuple2数据类型的RDD,其每个数据的第一个元素被当做key,第二个元素被当做value。
1,reduceByKey
2,groupByKey

3,sortByKey

4,join

5,leftOuterJoin

6,rightOuterJoin

7,cogroup

8,subtractByKey

9,foldByKey

七、持久化操作
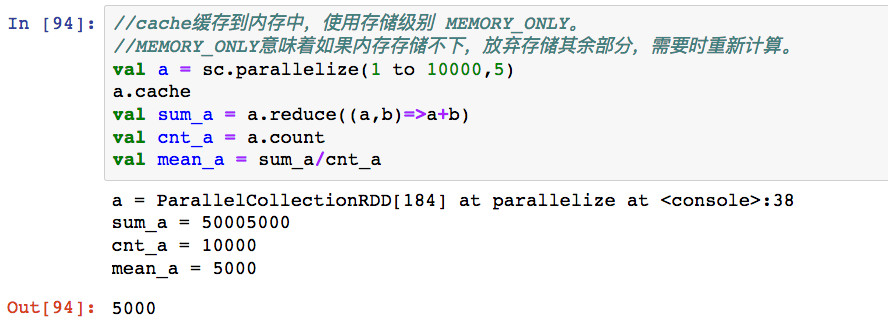
如果一个RDD被多个任务用作中间量,那么对其进行cache,缓存到内存中会对加快计算非常有帮助。
声明对一个RDD进行cache后,该RDD不会被立即缓存,而是等到它第一次因为某个Action操作触发后被计算出来时才进行缓存。
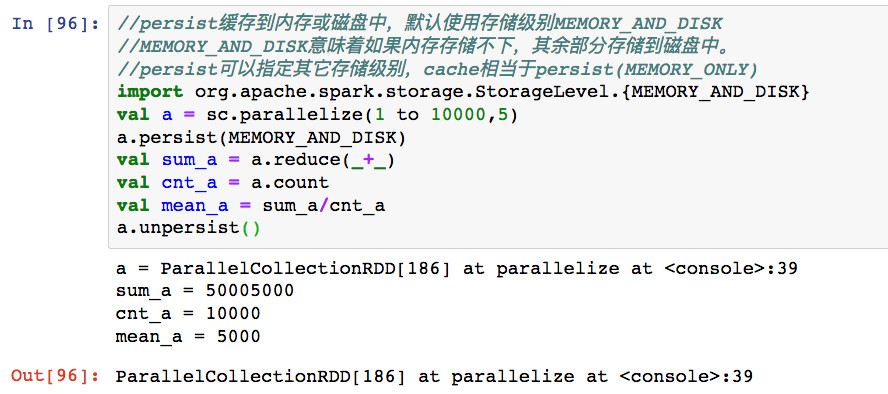
可以使用persist明确指定存储级别,常用的存储级别是MEMORY_ONLY和MEMORY_AND_DISK。
1,cache
2,persist
八、共享变量
当Spark集群在许多节点上运行一个函数时,默认情况下会把这个函数涉及到的对象在每个节点生成一个副本。但是,有时候需要在不同节点或者节点和Driver之间共享变量。
Spark提供两种类型的共享变量,广播变量和累加器。
广播变量是不可变变量,实现在不同节点不同任务之间共享数据。广播变量在每个节点上缓存一个只读的变量,而不是为每个task生成一个副本,可以减少数据的传输。
累加器主要用于不同节点和Driver之间共享变量,只能实现计数或者累加功能。累加器的值只有在Driver上是可读的,在节点上只能执行add操作。
1,broadcast

2,Accumulator

九、分区操作
分区操作包括改变分区方式,以及和分区相关的一些转换操作。
1,coalesce

2,repartition

3,partitionBy

4,mapPartitions

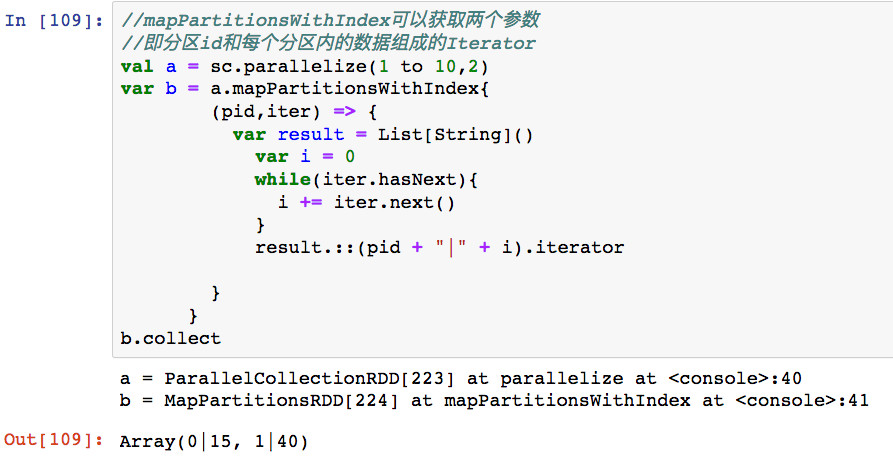
5,mapPartitionsWithIndex

6,foreachPartitions

7,aggregate

8,aggregateByKey
