一、文件读写的读书笔记
1、常见问题:
写入文件只能写入一行,在循环中将内容写入文件,但是代码在第一次循环中将文件关闭了,所以后边的写不进去,文件读写可能产生IOError为了保证无论是否出错都能正确地关闭文件,我们可以使用
try ... finally来实现:
ft = open("a", 'w')
for entry in result :
print entry try: ft.write(entry+'
') except: pass ft.close()#在内容写完后再关闭文件2.with方法:
with open('/path/to/file','r') as f:3.文件小的时候
read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便: for line in f.readlines(): print(line.strip()) # 把末尾的'
'删掉注释:strip
函数原型:s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
声明:s为字符串,rm为要删除的字符序列
当rm为空时,默认删除空白符(包括' ', ' ', ' ', ' ')
4.把两个路径合成一个时
把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。
在Linux/Unix/Mac下,os.path.join()返回这样的字符串:
part-1/part-2
而Windows下会返回这样的字符串:
part-1part-2
5.拆分路径
要拆分路径时,也不要直接去拆字符串,而要通过os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
os.path.splitext()可以直接让你得到文件扩展名
# 对文件重命名:
os.rename('test.txt', 'test.py')
删掉文件:
os.remove('test.py')
1 #使用Python内置的 open()函数,传入文件名和标示符: 2 f = open('/Users/michael/test.txt', 'r') 3 4 #'r'为标示符,包含: 5 'r': 默认值,表示从文件读取 6 'w': 表示要向文件写入数据,并截断以前的内容 7 'a': 表示要向文件写入数据,添加到当前内容尾部 8 'r+': 表示对文件进行可读写操作(删除以前的所有数据) 9 'r+a': 表示对文件可进行读写操作(添加到当前文件尾部) 10 'b': 表示要读写二进制数据 11 12 #若要读取二进制文件,比如图片、视频等,使用'rb'模式打开文件即可: 13 f = open('/Users/michael/test.jpg', 'rb') 14 f.read() 15 b'xffxd8xffxe1x00x18Exifx00x00...' # 十六进制表示的字节 16 17 #如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示: 18 f.read() 19 'Hello, world!' 20 21 #最后一步是调用 close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的: 22 f.close() 23 24 #为了防止忘记关闭文件导致内存占用,推荐使用with语句来自动帮调用close()方法: 25 with open('/path/to/file', 'r') as f: 26 print(f.read())
二、将excel文件存为csv格式
将两个excel文件合并为一个excel文件:转换为csv格式,并将里面的优秀变成90分,良好变成80分,及格变成60分,不交变成0分。
1 # -*- coding: utf-8 -*- 2 ''' 3 author:一枚小可爱 4 function:put two excel file into one excel file 5 6 ''' 7 #导入需要使用的包 8 import xlrd #读取Excel文件的包 9 import xlsxwriter #将文件写入Excel的包 10 11 import pandas as pd 12 import numpy as np 13 import matplotlib.pyplot as plt 14 15 #打开一个excel文件 16 def open_xls(file): 17 f = xlrd.open_workbook(file) 18 return f 19 20 #获取excel中所有的sheet表 21 def getsheet(f): 22 return f.sheets() 23 24 #获取sheet表的行数 25 def get_Allrows(f,sheet): 26 table=f.sheets()[sheet] 27 return table.nrows 28 29 #读取文件内容并返回行内容 30 def getFile(file,shnum): 31 f=open_xls(file) 32 table=f.sheets()[shnum] 33 num=table.nrows 34 for row in range(num): 35 rdata=table.row_values(row) 36 datavalue.append(rdata) 37 return datavalue 38 39 40 #获取sheet表的个数 41 def getshnum(f): 42 x=0 43 sh=getsheet(f) 44 for sheet in sh: 45 x+=1 46 return x 47 48 #函数入口 49 if __name__=='__main__': 50 #定义要合并的excel文件列表 51 allxls=['D:我的文件Python课件Python成绩.xlsx','D:我的文件Python课件Python成绩登记信计.xlsx'] #列表中的为要读取文件的路径 52 #存储所有读取的结果 53 datavalue=[] 54 for fl in allxls: 55 f=open_xls(fl) 56 x=getshnum(f) 57 for shnum in range(x): 58 print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...") 59 rvalue=getFile(fl,shnum) 60 #定义最终合并后生成的新文件 61 endfile=('D:我的文件Python课件Python成绩(1).xlsx') 62 wbl=xlsxwriter.Workbook(endfile) 63 #创建一个sheet工作对象 64 ws=wbl.add_worksheet() 65 for a in range(len(rvalue)): 66 for b in range(len(rvalue[a])): 67 c=rvalue[a][b] 68 ws.write(a,b,c) 69 wbl.close() 70 print("文件合并完成")
显示如下:
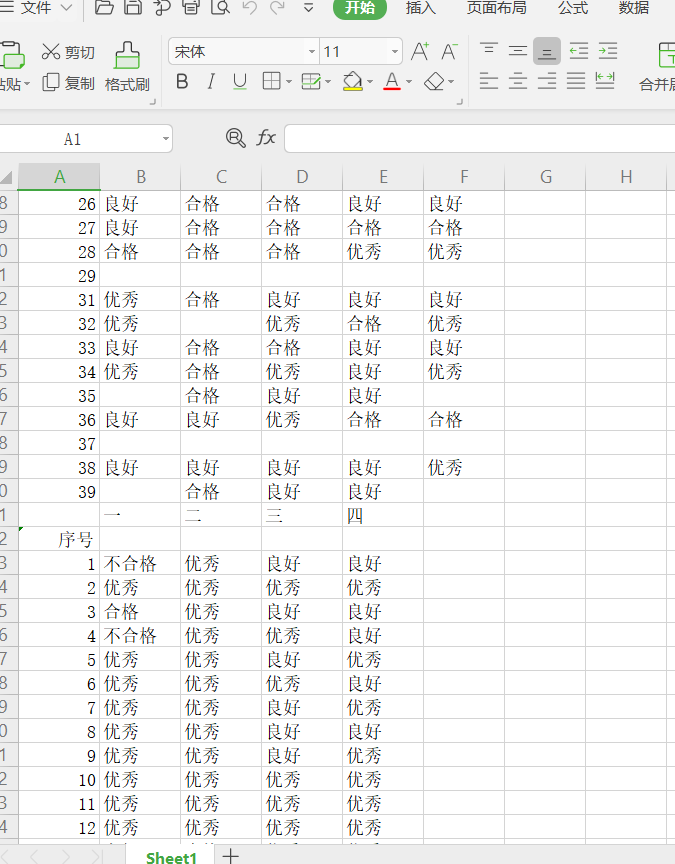
将excel文件转换为csv格式,并将里面的优秀变成90分,良好变成80分,及格变成60分,不交变成0分:
1 # -*- coding: utf-8 -*- 2 """ 3 author:一枚小可爱 4 function:put excel file into csv file 5 6 """ 7 import pandas as pd 8 import numpy as np 9 import matplotlib.pyplot as plt 10 #df.to_excel('C:/Users/Asus/Desktop/1.xlsx',sheet_name='dfg') 11 df=pd.read_excel('D:/我的文件/Python课件/Python成绩(1).xlsx',index_col=None,na_values=['NA']) 12 print(df) 13 for i in range(len(df.index)): 14 # print(df.iloc[i,1]) 15 for j in range(1,len(df.columns)): 16 if df.iloc[i,j]=='优秀': 17 df.iat[i,j]=90 18 elif df.iloc[i,j]=='良好': 19 df.iat[i,j]=80 20 elif df.iloc[i,j]=='合格': 21 df.iat[i,j]=60 22 else: 23 df.iat[i,j]=1 24 df.to_csv('D:/我的文件/Python课件/Python成绩1.csv') 25 print(df)
显示如下:
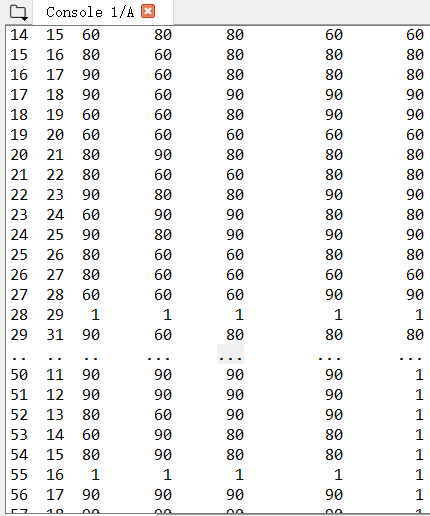
三、将csv文件转换html文件
1 # -*- coding:utf-8 2 ''' 3 author:一枚小可爱 4 function:change csv file into html file 5 6 ''' 7 def fill_data(excel, length=4): 8 ''' 9 函数功能:填充表格的一行数据,返回html格式的字符串text 10 excel: 表格中的一行数据 11 length: 表格中需要填充的数据个数(即列数),默认为4个 12 由于生成csv文件时自动增加了1列数据,因此在format()函数从1开始 13 ''' 14 text = '<tr>' 15 for i in range(length): 16 tmp = '<td align="center">{}</td>'.format(excel[i+1]) 17 text += tmp 18 text += "</tr> " 19 return text 20 21 def GetCsv(csvFile): 22 ''' 23 函数功能:打开csv文件并获取数据,返回文件数据 24 csvFile: csv文件的路径和名称 25 ''' 26 ls = [] 27 csv = open(csvFile, 'r', encoding="utf-8") 28 for line in csv: 29 line = line.replace(' ', '') 30 ls.append(line.split(',')) 31 return ls 32 33 34 def CsvToHtml(csvFile, HTMLFILE, thNum): 35 ''' 36 函数功能:将csv格式文件转换为html格式文件 37 csvFile: 需要打开和读取数据的csv文件路径 38 HTMLFILE: 保存的html文件路径 39 thNum: csv文件的列数,需注意其中是否包括csv文件第1列无意义的数据, 40 此处包含因此在调用时需要增加1 41 ''' 42 # HTML1 HTML2 分别为html文件的首部和尾部 43 HTML1 = ''' 44 <!DOCTYPE HTML> <html> <body> <meta charset=gbk2313> 45 <h1 align=center>Python成绩表</h2> 46 <table border='blue'> ''' 47 HTML2 = "</table> </body> </html>" 48 49 csv_list = GetCsv(csvFile) # 获得csv文件数据 50 hF = open(HTMLFILE, 'w') # 创建html文件 51 hF.write(HTML1) # 写入html文件首部 52 for i in range(1, thNum+1): # 写入表格的表头(即第1行) 53 hF.write('<th width="20%">{}</th> '.format(csv_list[0][i])) 54 hF.write("</tr> ") 55 for i in range(1, len(csv_list)): # 写入表格的数据,从第2行开始为数据 56 hF.write(fill_data(csv_list[i], 5)) 57 hF.write(HTML2) # 写入html文件尾部 58 hF.close() # 关闭html文件 59 60 CsvToHtml("D:/我的文件/Python课件/Python成绩1.csv", "D:/我的文件/Python课件/Python成绩11.html", 5)
显示如下:
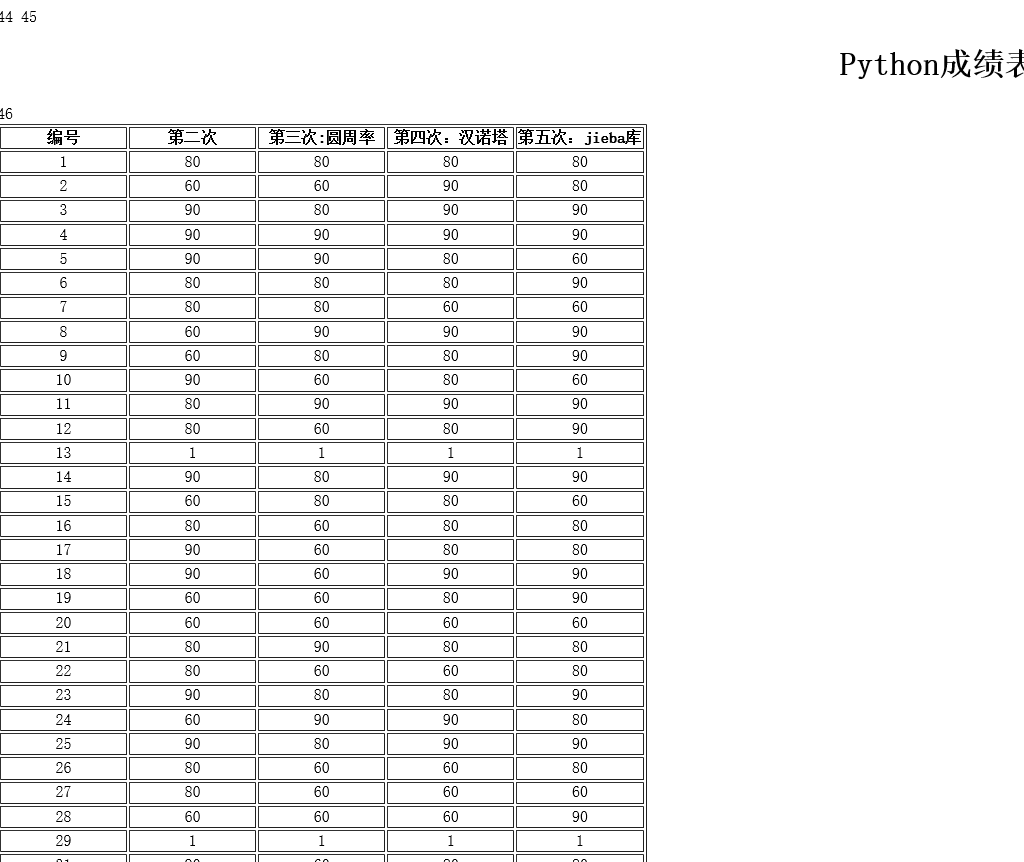
四、将csv文件转换成json格式
代码实现:
1 import json 2 fr=open("D:/我的文件/Python课件/Python成绩1.csv","r") 3 ls=[] 4 for line in fr: 5 line=line.replace(" ","") 6 ls.append(line.spilt(',')) 7 fr.close 8 fw=open("D:/我的文件/Python课件/Python成绩2.json","w") 9 for i in range(1,len(ls)): 10 ls[i]=dict(zip(ls[0]),ls[i]) 11 json.dump(ls[1:],fw,sort_keys=True,indent=4,ensure_ascii=False) 12 fw.close
实现如下:
