看完了常量,那我们来看下变量。
变量顾名思义,也就是能变化的量,也就是说已经定义之后它的值仍然是可以变的,不像常量一经定义便不能够改变了。比如说现在我们需要一个数,需要用户输入之后才能,确定这个数是几,如何计算。例如,现在有一个程序,可以根据用户输入的数字,输出对应的星期。那么,用户输入的数字,是我们写程序的时候无法确定的,是变化的,那么此时我们就需要有这么一个量,来存储这个变化的值,那么这个值就是一变量。
int week;//用户可能输入的数字,可变的无法确定的,此时就需要有一个变量来存储这个值
(疑问?常量和变量在内存中是如何存储的???希望知道的拍砖)。
一、变量的分类
那么变量都分哪几类呢?
|--整型变量 byte(一个字节),short(二个字节),int(四个字节),long(八个字节)
|--浮点型变量 float(四个字节),double(八个字节)
|--基本类型变量 |--字符变量char(2个字节)
| |--字符串变量
| |--布尔值变量(一个字节)
变量类型--|
| |--类变量 class
|--引用类型变量 |--接口变量 interface
|--数组变量 array[]
因为java是一种强类型语言,声明一个变量的时候必须以固定的形式来声明即:
变量类型 合法标志符 值 example: int a = 10; char a='a'; byte b = 3
二、不同类型变量之间的相互转换
一个类型的变量只能接受与其相对应的类型的常量
eg: int a = 'a';//这样赋值到底合不合法呢?
class Trans{
public static void main(String[] args) {
int a = 'a';
System.out.print(a);
}
}
运行代码之后我们得到了 97 也就是'a' 在ascii中a对应的阿斯科码,这种转换是编译器底层给予的变换,也叫做隐式变换。
在隐式变换中单个字符串就对应ascii中的码表 做相应的整数变换。
小空间类型只能向大精度类型做变换,当需要大类型向小类型变换的时候,叫做有损转换,此时需要做强制转换。
几种特殊情况:
1、int a = 'a';//是合法的 会隐式取a在ascii中码表的对应数字做替代
2、byte a = 10;//因为10默认是int类型(同时浮点型默认的是double类型),此时编译器首先验证byte类型能否存放得了10这个数,byte的取值范围是-128-127,所以可以,因此这个赋值是合法的。所以编译器没有提示,直接赋值完成。但是如果我们给a赋值为10000,此时就超出了byte所能承载的最大值,这个时候就会报错,“可能损失精度”编译失败。
还有一种情况是:
byte a = 10;
byte b = 20;
byte c = a+b;
这种能否编译成功呢,我们编译一下
class Trans{
public static void main(String[] args) {
byte a = 10;
byte b = 10;
byte c = a+b;
System.out.print(a);
}
}
此时编译仍然是失败的,提示损失精度,这是为何?
因为在编译过程中a,b是不确定的一个数,随时可变的,编译器无法确定,只能报错警告。(我也有一个地方不是很明白,上面两个不是已经具体赋值了么?有知道的解释下:) )
自问自答:
class Trans{
public static void main(String[] args) {
byte a = 10;
byte b;
byte c = a+b;
System.out.println(c);
}
}
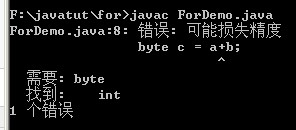
上图中的ForDemo 换成 Trans 哈......(*^__^*) 嘻嘻
按照正常的编译顺序应该先提示b没有初始化才对啊,但是这里却是先提示的“可能损失精度”,从这一点,也就解释了上面为什么初始化了,但是结果还是损失精度。在编译的过程中,是先求证byte c这个变量是否可能损失精度,再去找byte a; byte b的值进行计算。因此在可能损失精度的情况下,是无法编译通过的。
3、但是如果我们把byte类型换成int类型则不会报错,为什么?因为在编译器中默认的就是int类型,即使这个数字太大造成溢出,此时仍然是int,尽管损失精度。JVM就是这个样子规定的。
4、隐式转换之整数和浮点数:
当整数和浮点数做运算的时候,此时会以存储空间大的一个为基准,进行隐式转换。【在运算符当中会讲到】
布尔类型不能强转,boolean b = true;(char)b,是编译不过的。
5、char类型是可以放中文的,之所以可以放中文是因为,char本身就是两个字节,一个汉字恰好能够放两个字节,所以char b="孙";这个是可以编译通过的。char类型当中只能够放单个字符,并且要用单引号括起来。