一、Redis
1、简介
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
2、优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
3、Redis与其他key-value存储有什么不同?
-
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
-
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
4、Redis 安装
下载地址:https://github.com/MSOpenTech/redis/releases。
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis
打开一个 cmd 窗口 使用cd命令切换目录到 C: edis 运行 redis-server.exe redis.windows.conf 。
如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面:
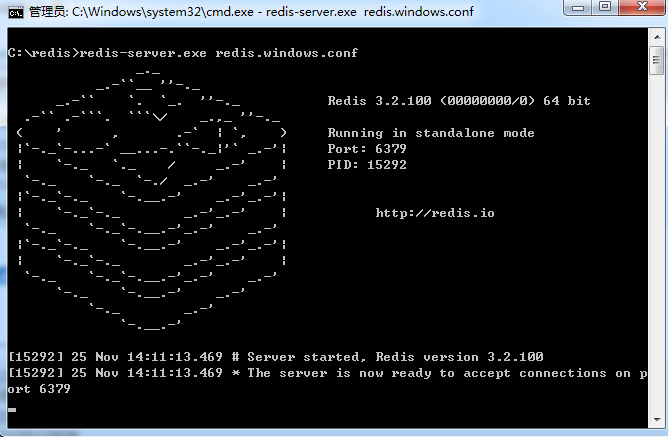
这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。
切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 。
设置键值对 set myKey abc
取出键值对 get myKey
5、安装目录的文件
redis-server : 服务器
redis-cli :命令行客户端
redis-benchmark 性能工具测试
redis-check-aof ADF文件修复工具
redis-check-dump RDB文件检测工具
redis.conf是redis的配置文件
将配置文件中的daemonize yes 以守护进程的方式来使用 cd到redis的安装目录下 启动和停止 启动 : redis-server 停止:shutdown 命令返回值 1)状态回复 pong set test "this is a test" 2)错误回复 (error) ERR unknown command 'testerror' 3)整数回复: (integer) 4 4)字符串回复 get 'test' (nil) 代表空的结果 5)多行字符串回复 KEYS * 得到当前数据库中的存在的键值名
6、Redis配置选项相关的内容
1>动态设置/获取配置选项的值 获取 CONFIG GET port 1)"post" 2)"6379" 动态设置 CONFIG GET warning 2>Redis配置文件redis.conf选项相关 ---- 连接选项 ---- port 6379 默认端口 bind 127.0.01 默认绑定的主机地址 timeout 0 客户端闲置多久后自动关闭连接 0 代表没有启动这个选项 loglevel notice 日志的记录级别 debug 调试的很详细的信息:适合开发和测试 verbose 包含很多不太有用的信息 notice 生产环境 warning 警告信息 logfile stdout 指定日志的记录方式 默认是标准输出 database 16 设置默认数据库的数量,默认是16个 SETECT 1 选择数据库 默认编号是0 ----- 快照相关 ------ 多少秒有多少次改变将其同步到磁盘中的数据文件中 save 900 1 900代表秒数 900秒内有一个更改就记录到磁盘中 save 300 10 save 60 10000 rdbcompression yes 存储本地数据库是是否启动压缩, 默认yes dbfilename dump.db 指定本地数据库的文件名
7、Redis的数据类型
1》String类型


1 一个键最多存储512MB 2 1》SET 设置key 对应的值为value 3 4 语法:SET key value [EX seconds] [PX milliseconds] [NX|XX] 5 6 EX seconds 设置key的过期时间 SET key value EX seconds == SETEX 7 PX milliseconds 以毫秒的形式设置过期时间 SET key value PX milliseconds -- PSETEX 8 NX :只有键不存在的时候才会设置成功 --SETNX 9 XX :只有key已经存在的时候才可以设置 10 11 SET test16 'this is a test' EX 100 12 SET test17 'this is a test17' PX 20000 13 SET test18 'this is a test18' NX 14 SET test18 'this is a test18888' XX 15 16 SET test19 'this is a test19' EX 100 NX 17 18 SET test20 'this is a test20' EX 100 PX 300000 NX 19 20 21 注意: 如果key存在,同名会产生覆盖 22 23 SET testStr1 "this is a test" 24 25 2》GET key 根据key找到对应的值 26 27 语法: GET key 28 29 注意:如果key不存在,返回nil 30 如果key不是字符串,会报错 31 32 3》GETGANGE: 返回字符串中的一部分 33 34 语法:GETRANGE key start end 35 36 GETGANGET testStr2 0 4 37 GETGANGET testStr2 0 -3 38 GETGANGET testStr2 -4 -2 39 GETGANGET testStr2 0 1000 40 41 4》GETSET:设定指定可以的值,返回原来的值 42 计数器的清零效果 43 44 语法:GETSET key value 45 SET testStr3 'king' 46 47 GET testStr3 48 49 GETSET testStr3 'queen' 50 51 注意:当key不存在返回nil 如果key不是字符串会报错 52 53 5》MSET 一次设置多个 54 55 语法:MSET key value [key value...] 56 MSET testStr5 'king' testStr6 'sk' testStr7 'queen' 57 58 6》MGET 一次获得多个 59 60 语法:MGET key key 61 MGET testStr5 testStr6 testStr7 62 63 7》STRLEN:获取key的字符串的长度 64 65 语法:STRLEN key 66 67 注意:对于不存在的key获取其长度返回的是0 68 69 8》SETRANGE:相当于字符串替换的效果 70 71 语法:8》SETRANGE key offset value 72 73 注意:如果设置的key原来的字符串长度要比偏移量小,就会以零字节(x00)来填充 74 75 SET testStr9 'hello king' 76 77 SETRANGE testStr9 6 'queen' 78 79 对于不存在的key使用SETRANGE 80 81 EXISTS testStr10 检测key是否存在 82 83 SETRANGE testStr10 5 'king' 84 85 9》SETNX 只有key不存在才能设置成功 86 87 语法:SETNX key value 88 89 10》SETEX:key 设置key并且设置过期时间,以秒为单位 90 91 语法:SETEX key seconds value 原子性操作 92 TTL 得到键的生存周期 93 94 注意:SETEX 是原子性操作,相当于执行了SET key value ,又对这个key设置了过期时间 EXPIRE key seconds 95 96 97 SET expireStr1 'test1' 98 99 EXPIRE expireStr1 10 100 101 SETEX test12 1000 'a' 102 103 GET test12 104 105 11》 MSETNX 一次设置多个key-value ,只有所有的key都不存在的时候才会成功 106 107 语法 MSETNX key value [key value] 108 109 MSETNX test13 'a' test14 'b' test15 'c' 110 111 12》PSETEX:以毫秒为单位设置key的生存周期 112 113 语法:PSETEX key milliseconds value 114 115 PSETEX test16 2000 'hell0 king' 116 117 PTTL 118 13》INCR 对key中存储的数字+1 119 120 语法:INCR key 121 122 SET counter 1 123 124 INCR counter 125 126 注意:key如果不存在会先初始化为0,在进行INCR操作, 127 对于不是数值的值会报错 128 129 14》INCR BY : 将key中存储的数字加上指定增量 130 131 语法:INCRBY key INCREMENT 132 133 SET counter2 10 134 INCRBY counter2 5 135 INCRBY counter2 1.2 不能用浮点数 136 15》INCRBYFLOAT : 给key中存储的数字加上指定的浮点数 137 138 语法:INCRBYFLOAT key increment 139 140 SET counter3 1 141 142 INCRBYFLOAT counter3 1.2 143 144 16》DECR:给将key中存储的数字减1 145 146 语法:DECR key 147 148 17》DECYBY:将key中存储的数值减去指定的值 149 150 语法:DECRBY key decrement 151 152 18》APPEND:将值追加到字符串的末尾 153 154 语法:APPEND key value
2》Hash类型
1 Hash类型(散列表) 2 在配置文件中可以通过配置 3 hash-max-ziplist-entries 512 512个字节 4 hash-max-ziplist-value 64 字段数目 5 6 Hash相关命令 7 1》HSET : 将哈希表key中域field设置成指定的value 8 9 语法 : HSET key field value 10 11 HSET userInfo1 username 'king' 12 13 HSET userInfo1 password '123456' 14 15 HSET userInfo1 email '18368827317@163.com' 16 17 HSET username 'queen' 18 19 注意:如果哈希表中key中field不存在相当于新建field,设置成功返回1 20 如果哈希表中key中field存在,相当于重新赋值,成功返回0 21 22 2》HGET :返回哈希表中给定field的值 23 24 语法:HGET key field 25 26 HGET userInfo1 username 27 28 注意:如果key中field不存在,返回的是nil 29 30 3》HSETNX: 将哈希表中的field设定成指定的值,只有field不在的时候才能成功,如果filed存在,操作无效 31 32 语法:HSETNX key filed value 33 34 HSETNX testHash1 test 'a' 35 36 4》 HMSET :通过将多个field-value设置到hash表key中 37 38 语法:HMSET key value filed value ... 39 40 HMSET userInfo2 username(域) 'king'(值) kickname 'freeyman' 41 42 5》HMGET : 一次获得hash表key中多个filed的值 43 44 语法:HMGET key field field 45 46 注意:如果hash表中field不存在,会返回nil 47 48 6》HGETALL:返回哈希表key中所有的field和value 49 50 语法:HGETALL key 51 52 7》HKEYS:返回hash中key的所有的filed 53 54 语法: HKEYS key 55 56 8》HVALS :返回所有hash中key中field所有的对应的值 57 58 语法:HVALS key 59 60 9》HEXISTS :检测hash表中key的field是否存在 61 62 语法:HEXISTS key field 63 64 HEXISTS userInfo2 username 65 66 HEXISTS userInfo2 notExists 67 68 10》HLEN: 返回hash表中keyfield的数量 69 70 语法:HLEN key 71 72 11》HINCRBY:给hash中key的field做增量操作 73 74 语法:HINCRBY key field increment 75 76 12》HINCRBYFLOAT: 给hash中key的field做增量操作 家浮点数 77 78 语法:HINCRBYFLOAT key field increment 79 80 HSET userInfo3 salary '12343.341' 81 82 HINCRBYFLOAT userInfo3 salary '0.214' 83 84 13》HDEL :删除hash中key的指定域,可以删除一个也可以删除多个 85 86 语法:HDEL key field field 87 88 HGETALL userInfo2 89 90 HDEL userInfo2 username
3》List类型
1 双向链表实现的两边的获取速度快) 2 3 1》LPUSH:向列表左端添加元素 4 5 语法:LPUSH key value... 从左到右依次插入 6 7 LPUSH myList1 a b c 8 9 2》RPUSH :向列表右端添加元素 10 11 语法:RPUSH key value... 12 13 RPUSH myList1 test1 test2 test3 14 15 3》LPUSHX:向列表头部添加元素,只有key存在在来添加 只能添加一个值, 16 17 语法:LPUSHX key value 18 19 LPUSH myList2 test4 20 21 4》RPUSHX:向列表尾部添加元素,只有key存在在来添加 22 23 语法:RPUSHX key value 24 25 RPUSH myList2 test4 26 27 5》LPOP :将列表头部的元素弹出 28 29 语法:LPOP myList1 30 31 6》RPOP : 将列表尾部的元素弹出 32 33 语法:RPOP myList1 34 35 7》LLEN : 得到列表的长度 36 37 语法:LLEN key 38 39 8》LRANGE : 获取列表片段 40 41 语法:LRANGE key start stop 42 43 LRANGE myList1 0 -1 44 45 注意:如果start下标比列表的最大的下标end大,返回空列表 46 如果stop比列表长度大,返回列表的末尾 47 48 9》LREM:删除列表中指定的值 49 50 语法:LRME key count value 51 52 count>0 从列表的头开始,向尾部搜索,移除与value相等的元素,移动count个 53 54 count<0 从列表的尾部向头搜索,移除与value相等的元素,移除count个 55 56 count=0 移除列表所有与count相等的值 57 58 LPUSH myList3 a b c d a b c d b e f b g e b 59 60 LREM myList3 2 b 61 62 LREM myList3 -1 a 63 64 LREM myList3 0 e 65 66 10》LINDEX:获取指定索引元素的值 67 68 语法:LINDEX key index 69 70 LINDEX myList3 3 71 72 LINDEX myList3 -2 73 74 11》LSET :设置指定索引元素的值 75 76 LSET key index value 77 78 12》LTRIM :只保留列表的片段 79 80 语法:LTRIN key start stop 81 82 LPUSH myList4 log1 log2 log3 log4 log5 83 84 LRTIM myList4 0 1 85 86 LPUSH myList4 a b c d e f g 87 88 LTRIM myList4 1 -1 89 90 LTRIM myList4 1 91 92 13》LINSERT 向列表插入元素 93 94 语法:LINSERT key BEFORE|AFTER pivot value 95 96 LPUSH myList6 a b c d 97 98 LINSERT myList6 BEFORE "b" "king" 99 100 如果没有成功返回-1 成功返回当前列表的长度 对于空列表返回0 不成功 101 102 14》RPOPLPUSH:将一个元素从一个列表转移到另一个列表(原子性操作) 103 104 语法:RPOPLPUSH source destination 105 106 RPOPLPUSH myList1 myList6 107 108 15》BLPOP:BLPOP是LPOP 的一个阻塞版本 109 110 语法: BLPOP key [key...] timeout 111 112 LPUSH myList9 a b c 113 114 LPUSH myList10 d e f 115 116 BLPOP myList8 myList9 myList10 0 117 118 BLPOP myList8 8 0
4》Set类型
1 sns 和 博客系统 可以通过集合类型实现 2 3 1》SADD :向集合中添加元素 4 5 语法:SADD key member [,...] 6 7 SADD web sunkai.clog.com 8 9 2》SMEMBERS :返回指定集合中的元素 10 11 语法:SMEMBERS key 12 13 3》SISMEMBER : 检测member是否是集合中的成员 14 15 语法:SISMEMBER key member 16 17 4》SREM :删除 18 19 语法:SREM key member 20 21 5》SPOP :随机删除并返回集合中的删除的元素 22 23 语法:SPOP key 24 25 6》SRANDMEMBER :随机返回集合中的元素 26 27 语法:SRANDMEMBER key counter 28 29 注意:count 为正数,而且小于集合中的元素,返回的一个包含随机元素的集合数组;count如果大于集合中的元素,这个时候会返回整个集合 30 count 为负数,返回一个数组,数组中的成员可能出现重复,数组的长度是count取绝对值 31 32 7》SDIFF 返回集合间的差集 33 34 语法:SDIFF key key 35 36 SADD couser2 java PHP js jq Python 37 38 SADD couser1 iOS anzhuo Python 39 40 SDIFF couser2 couser1 41 42 8》SINTER 返回集合间的交集 43 44 语法:SINTER key key ... 45 46 SINTER couser2 couser1 47 48 9》SUNION :返回集合间的并集 49 50 语法:SUNION key key 51 52 10》SCARD :返回集合的长度 53 54 语法:SCARD 55 56 11》SDIFFSTORE :讲差集结果保存到指定集合中 57 58 语法:SDIFFSTORE destination key key ... 59 60 SDIFFSTORE diffSET couser2 couser1 61 62 12》SINTERSTORE 63 64 13》SUNIONSTORE 65 66 14》SMOVE 将集合中的元素移动到另一个集合中(原子性操作) 67 68 语法:SMOVE source destination member
5》Zset(sorted set)有序集合类型
1 1》ZADD :将元素及其分数添加到集合中 2 3 语法: ZADD key score member [score member] 4 5 ZADD PYTHONcourse 100 king 6 7 ZADD PYTHONcourse 98 queen 98 test 78 test1 8 9 ZADD PYTHONcourse +inf maxInt -inf minInx 正无穷大,负无穷大 10 11 2》ZSCORE :获得集合中的指定元素的分数 12 13 语法:ZSCORE key member 14 15 3》ZRANGE :按照元素分数从小到大的顺序返回指定索引start到stop之间的所有元素(包含两端) 16 17 语法:ZRANGE key start stop WITHSCORES 带分数 18 19 注意:当元素的两个元素的分数相同的时候,redis在排序按照字典的顺序排列 20 21 4》ZREVRANGE: 和ZRANGE 相反,按照从大到小的顺序返回 22 23 语法:ZREVRANGE key start stop [WITHSCORES] 24 25 5》ZRANGEBYSCORE :获取指定分数范围内的元素,按照从小到大的顺序,返回的是分数在指定的min到max之间 26 27 语法:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 28 29 获得分数80~90之间的所有元素 30 31 ZRANGEBYSCORE PYTHONcourse 80 90 32 33 ZRANGEBYSCORE PYTHONcourse 80 (90 不包含90 34 35 注意:通过左括号代表不包含端点 36 37 6:ZREVRANGEBYSCORE 和上面的相反 38 39 语法:ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 40 41 7》ZINCRBY : 操作某个元素的分数,返回操作之后的分数 42 43 语法:ZINCRBY key increment member 44 45 8》ZCARD :获得集合中元素的数量 46 47 语法:ZCARD key 48 49 9》ZCOUNT 获得指定分数内元素的数量 50 51 语法:ZCOUNT PYTHONcourse 80 90 52 53 10》ZREM :删除一个或多个元素,返回删除元素的个数 54 55 语法:ZREM key member ... 56 57 11》ZREMRANGEBYRANK: 按照排名范围删除元素,按照分数从小到大的顺序删除所有指定的排名范围内的所有元素 58 59 语法:ZREMRANGEBYRANK key start stop 60 61 12》ZREMRANGEBYSCORE:按照分数范围内删除元素 62 63 语法:ZREMRANGEBYSCORE key min max 64 65 13》ZRANK :获得指定元素的排名,根据分数从小到大的顺序 66 67 语法:ZRANK key member 68 69 14》ZREVRANK:获得指定元素的排名,根据分数从大到小的顺序 70 71 语法:ZREVRANK key member 72 73 15》ZINTERSTORE: 计算有序集合的交集,并将结果保存起来 74 75 语法:ZINTERSTORE destination numkeys key key ... WEIGHTS weight weight AGGREGATE [SUM|MIN|MAX] 76 77 ZADD testSortedSet1 1 a 2 b 3 c 78 79 ZADD testSortedSet2 10 a 20 b 30 c 80 81 ZINTERSTORE testSorted1 2 testSortedSet1 testSortedSet2 82 83 ZRANGE testSorted1 0 -1 WITHSCORES 84 85 ZINTERSTORE testSorted2 2 testSortedSet1 testSortedSet2 AGGREGATE SUM 86 87 ZINTERSTORE testSorted3 2 testSortedSet1 testSortedSet2 AGGREGATE MIN 88 89 16》ZUNIONSTORE :计算有序集合并集,并将结果保存起来 90 91 语法:ZUNIONSTORE destination numkeys key key ... WEIGHTS weight weight AGGREGATE [SUM|MIN|MAX]
未完待续。。。。。。
二、RabbitMQ
1、简介
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。RabbitMQ可以,多个程序同时使用RabbitMQ ,但是必须队列名称不一样。采用erlang语言,属于爱立信公司开发的。
消息中间件 --->就是消息队列
异步方式:不需要立马得到结果,需要排队
同步方式:需要实时获得数据,坚决不能排队
subprocess 的Q也提供不同进程之间的沟通
应用场景:
电商秒杀活动
抢购小米手机
堡垒机批量发送文件
2、Centos6.x系统编译安装RabbitMQ
一、安装erlang
依赖包:
yum -y install gcc ncurses ncurses-base ncurses-devel ncurses-libs ncurses-static ncurses-term ocaml-curses ocaml-curses-devel openssl-devel zlib-devel openssl-devel perl xz xmlto kernel-devel m4 这是一行
1、下载otp_src_19.3.tar.gz
2、tar xvf otp_src_19.3.tar.gz
3、cd opt_src_19.3.tar.gz
4、./configure --prefix=/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe --without-javac
5、make && make install
5、配置erlang环境:
vi /etc/profile
export PATH=$PATH:/usr/local/erlang/bin
source /etc/profile # 环境变量重启生效
二、安装rabbitmq
1、下载rabbitmq-server-generic-unix-3.6.5.tar.xz
2、tar xvf rabbitmq-server-generic-unix-3.6.5.tar.xz
3、mv rabbitmq_server-3.6.5/ /usr/local/rabbitmq
4、启动:
#启动rabbitmq服务
/usr/local/rabbitmq/sbin/rabbitmq-server
#后台启动
/usr/local/rabbitmq/sbin/rabbitmq-server -detached
#关闭rabbitmq服务
/usr/local/rabbitmq/sbin/rabbitmqctl stop
或
ps -ef | grep rabbit 和 kill -9 xxx 杀死服务
#开启插件管理页面
/usr/local/rabbitmq/sbin/rabbitmq-plugins enable rabbitmq_management
#创建用户
/usr/local/rabbitmq/sbin/rabbitmqctl add_user rabbitadmin 123456
/usr/local/rabbitmq/sbin/rabbitmqctl set_user_tags rabbitadmin administrator
./rabbitmqctl set_permissions -p / rabbitadmin ".*" ".*" ".*" 为这个用户授权
5、登录
#WEB登录
http://10.10.3.63:15672 自己的IP地址
用户名:rabbitadmin
密码:123456
三、几种队列通信
1、实现最简单的队列通信

sender
import pika
# 认证
credentials = pika.PlainCredentials('rabbitadmin', '123456') # 一定要认证
# 连接这台机器
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.14.38',credentials=credentials)) #主机IP 和验证
channel = connection.channel() # 建立了rabbitmq的协议通道
# 声明queue队列
channel.queue_declare(queue='hello')
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
# 发送消息
channel.basic_publish(exchange='', exchange表示交换器,能精确指定消息应该发送到哪个队列,
routing_key='hello', #
body='Hello World!')#routing_key设置为队列的名称,body就是发送的内容
print(" [x] Sent 'Hello World!'")
connection.close()
import pika
import time
credentials = pika.PlainCredentials('rabbitadmin', '123456')
# 连接这台机器
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.14.38',credentials=credentials))
channel = connection.channel() # 建立了rabbitmq的协议通道
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print("received msg...start processing....",body)
time.sleep(20)
print(" [x] msg process done....",body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
2、Work Queues (一个发消息,两个收消息,收消息是公平的依次分发)

在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多。
消息提供者代码
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
# 声明queue
channel.queue_declare(queue='task_queue')
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
import sys
message = ' '.join(sys.argv[1:]) or "Hello World! %s" % time.time()
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent %r" % message)
connection.close()
import pika, time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(20)
print(" [x] Done")
print("method.delivery_tag",method.delivery_tag)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback,
queue='task_queue',
no_ack=True
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
此时,先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上
3、消息持久化
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储:
将队列(Queue)与消息(Message)都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果需要对这种小概率事件也要管理起来,那么要用到事务。由于这里仅为RabbitMQ的简单介绍,所以不讲解RabbitMQ相关的事务。
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel() # 建立了rabbit 协议的通道
# durable=True 声明持久化存储
channel.queue_declare(queue='task_queue', durable=True)
channel.basic_publish(exchange='',
routing_key='task_queue',
body='Hello World!',
# 在发送任务的时候,用delivery_mode=2来标记消息为持久化存储
properties=pika.BasicProperties(
delivery_mode=2,
))
print(" [x] Sent 'Hello World!'")
connection.close()
sender.py
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, properties, body):
print("received msg...start processing....",body)
time.sleep(20)
print(" [x] msg process done....", body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(
callback,
queue='task_queue',
no_ack=False # 默认为False
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
4、消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。

channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发的完整代码
生产者端
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
消费者端
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
5、PublishSubscribe(消息发布订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
交流是一个非常简单的事情。一方面它收到消息从生产者和另一边推他们队列。交换必须知道如何处理接收到的消息。应该是附加到一个特定的队列吗?应该是附加到多队列?或者应该丢弃。交换的规则定义的类型。
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers: 通过headers 来决定把消息发给哪些queue

消息publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
消息subscriber
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
6、有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]
" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
7、更细致的消息过滤
Although using the direct exchange improved our system, it still has limitations - it can't do routing based on multiple criteria.
In our logging system we might want to subscribe to not only logs based on severity, but also based on the source which emitted the log. You might know this concept from the syslog unix tool, which routes logs based on both severity (info/warn/crit...) and facility (auth/cron/kern...).
That would give us a lot of flexibility - we may want to listen to just critical errors coming from 'cron' but also all logs from 'kern'.
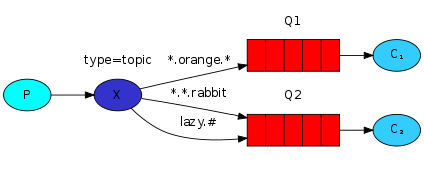
topi: 意思是话题
To receive all the logs run:
python receive_logs_topic.py "#" #绑定#号,就是收所有消息,相当于广播
To receive all logs from the facility "kern":
python receive_logs_topic.py "kern.*" #以kern开头
Or if you want to hear only about "critical" logs:
python receive_logs_topic.py "*.critical" #以critical结尾
You can create multiple bindings:
python receive_logs_topic.py "kern.*" "*.critical" #收kern开头并且以critical结尾(相当于收两个)
And to emit a log with a routing key "kern.critical" type:
python emit_log_topic.py "kern.critical" "A critical kernel error" #发消息到kern.critical里,内容是:
A critical kernel error
示例:
rabbit_topic_send.py (生产者是发送端)
1 import pika
2 import sys
3
4 credentials = pika.PlainCredentials('nulige', '123456')
5 connection = pika.BlockingConnection(pika.ConnectionParameters(
6 host='192.168.1.118',credentials=credentials))
7
8 channel = connection.channel()
9
10 channel.exchange_declare(exchange='topic_logs',type='topic') #指定类型
11
12 routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
13
14 message = ' '.join(sys.argv[2:]) or 'Hello World!' #消息
15
16 channel.basic_publish(exchange='topic_logs',
17 routing_key=routing_key,
18 body=message)
19 print(" [x] Sent %r:%r" % (routing_key, message))
20 connection.close()
rabbit_topic_recv.py (消费者是接收端)单向的
1 import pika
2 import sys
3
4 credentials = pika.PlainCredentials('nulige', '123456')
5 connection = pika.BlockingConnection(pika.ConnectionParameters(
6 host='192.168.1.118',credentials=credentials))
7
8 channel = connection.channel()
9 channel.exchange_declare(exchange='topic_logs',type='topic')
10
11 result = channel.queue_declare(exclusive=True)
12 queue_name = result.method.queue
13
14 binding_keys = sys.argv[1:]
15 if not binding_keys:
16 sys.stderr.write("Usage: %s [binding_key]...
" % sys.argv[0])
17 sys.exit(1)
18
19 for binding_key in binding_keys:
20 channel.queue_bind(exchange='topic_logs',
21 queue=queue_name,
22 routing_key=binding_key)
23
24 print(' [*] Waiting for logs. To exit press CTRL+C')
25
26 def callback(ch, method, properties, body):
27 print(" [x] %r:%r" % (method.routing_key, body))
28
29 channel.basic_consume(callback,queue=queue_name)
30
31 channel.start_consuming()
执行结果:
1 #接收端 2 D:pythonday42>python3 rabbit_topic_recv.py error 3 [*] Waiting for logs. To exit press CTRL+C 4 [x] 'error':b'mysql has error' 5 6 7 D:pythonday42>python3 rabbit_topic_recv.py *.warning mysql.* 8 [*] Waiting for logs. To exit press CTRL+C 9 [x] 'mysql.error':b'mysql has error' 10 11 12 D:pythonday42>python3 rabbit_topic_send.py mysql.info "mysql has error" 13 [x] Sent 'mysql.info':'mysql has error' 14 15 16 D:pythonday42>python3 rabbit_topic_recv.py *.error.* 17 [*] Waiting for logs. To exit press CTRL+C 18 [x] 'mysql.error.':b'mysql has error' 19 20 21 #发送端 指定类型:error 消息内容 22 D:pythonday42>python3 rabbit_topic_send.py error "mysql has error" 23 [x] Sent 'error':'mysql has error' 24 25 26 D:pythonday42>python3 rabbit_topic_send.py mysql.error "mysql has error" 27 [x] Sent 'mysql.error':'mysql has error' 28 [x] 'mysql.info':b'mysql has error' 29 30 31 D:pythonday42>python3 rabbit_topic_send.py mysql.error. "mysql has error" 32 [x] Sent 'mysql.error.':'mysql has error'
8、Remote procedure call (RPC) 双向的
To illustrate how an RPC service could be used we're going to create a simple client class. It's going to expose a method named call which sends an RPC request and blocks until the answer is received:
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print("fib(4) is %r" % result)
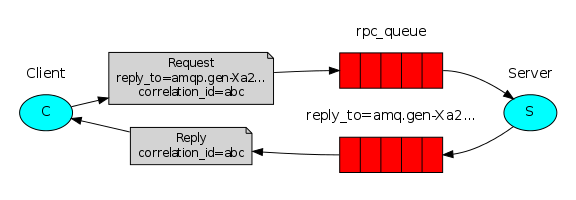
应用场景:
示例:实现RPC服务功能
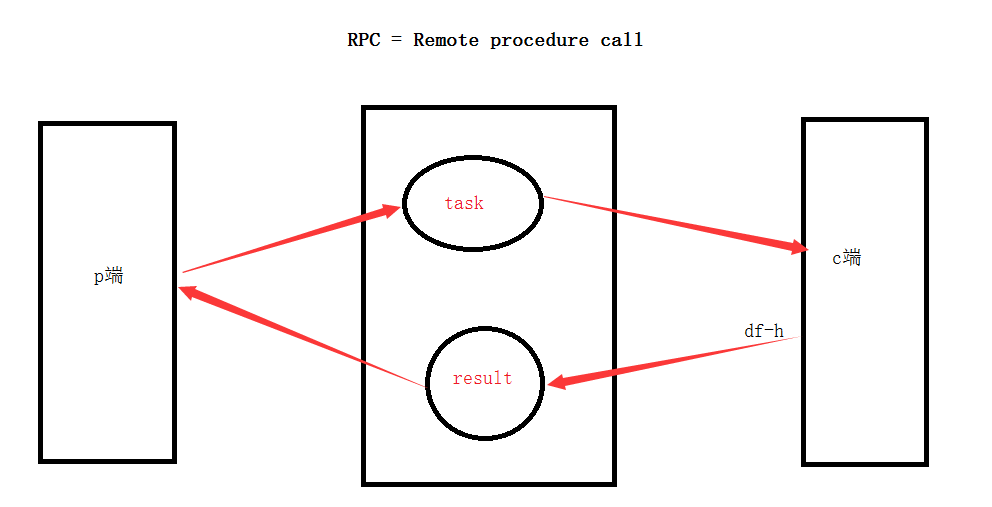
rabbit_rpc_send.py(生产者是发送端)
1 import pika
2 import uuid
3
4 class SSHRpcClient(object):
5 def __init__(self):
6 credentials = pika.PlainCredentials('nulige', '123456')
7 self.connection = pika.BlockingConnection(pika.ConnectionParameters(
8 host='192.168.1.118',credentials=credentials))
9
10 self.channel = self.connection.channel()
11
12 result = self.channel.queue_declare(exclusive=True) #客户端的结果必须要返回到这个queue
13 self.callback_queue = result.method.queue
14
15 self.channel.basic_consume(self.on_response,queue=self.callback_queue) #声明从这个queue里收结果
16
17 def on_response(self, ch, method, props, body):
18 if self.corr_id == props.correlation_id: #任务标识符
19 self.response = body
20 print(body)
21
22 # 返回的结果,放在callback_queue中
23 def call(self, n):
24 self.response = None
25 self.corr_id = str(uuid.uuid4()) #唯一标识符
26 self.channel.basic_publish(exchange='',
27 routing_key='rpc_queue3', #声明一个Q
28 properties=pika.BasicProperties(
29 reply_to=self.callback_queue,
30 correlation_id=self.corr_id,
31 ),
32 body=str(n))
33
34 print("start waiting for cmd result ")
35 count = 0
36 while self.response is None: #如果命令没返回结果
37 print("loop ",count)
38 count +=1
39 self.connection.process_data_events() #以不阻塞的形式去检测有没有新事件
40 #如果没事件,那就什么也不做, 如果有事件,就触发on_response事件
41 return self.response
42
43 ssh_rpc = SSHRpcClient()
44
45 print(" [x] sending cmd")
46 response = ssh_rpc.call("ipconfig")
47
48 print(" [.] Got result ")
49 print(response.decode("gbk"))
rabbit_rpc_recv.py(消费端是接收端)
1 import pika
2 import time
3 import subprocess
4
5 credentials = pika.PlainCredentials('nulige', '123456')
6 connection = pika.BlockingConnection(pika.ConnectionParameters(
7 host='192.168.1.118', credentials=credentials))
8
9 channel = connection.channel()
10 channel.queue_declare(queue='rpc_queue3')
11
12 def SSHRPCServer(cmd):
13
14 print("recv cmd:",cmd)
15 cmd_obj = subprocess.Popen(cmd.decode(),shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
16
17 result = cmd_obj.stdout.read() or cmd_obj.stderr.read()
18 return result
19
20 def on_request(ch, method, props, body):
21
22 print(" [.] fib(%s)" % body)
23 response = SSHRPCServer(body)
24
25 ch.basic_publish(exchange='',
26 routing_key=props.reply_to,
27 properties=pika.BasicProperties(correlation_id=
28 props.correlation_id),
29 body=response)
30
31 channel.basic_consume(on_request, queue='rpc_queue3')
32 print(" [x] Awaiting RPC requests")
33 channel.start_consuming()