hystrix,框架,提供了高可用相关的各种各样的功能,然后确保说在hystrix的保护下,整个系统可以长期处于高可用的状态,100%。
高可用系统架构:
资源隔离、限流、熔断、降级、运维监控
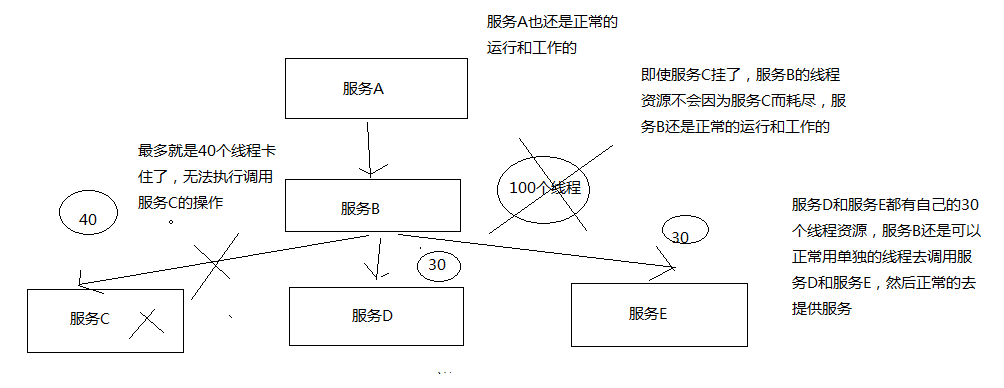
资源隔离:让你的系统里,某一块东西,在故障的情况下,不会耗尽系统所有的资源,比如线程资源。
限流:高并发的流量涌入进来,比如说突然间一秒钟100万QPS,废掉了,10万QPS进入系统,其他90万QPS被拒绝了。
熔断:系统后端的一些依赖,出了一些故障,比如说mysql挂掉了,每次请求都是报错的,熔断了,后续的请求过来直接不接收了,拒绝访问,10分钟之后再尝试去看看mysql恢复没有
降级:mysql挂了,系统发现了,自动降级,从内存里存的少量数据中,去提取一些数据出来
运维监控:监控+报警+优化,各种异常的情况,有问题就及时报警,优化一些系统的配置和参数,或者代码。
1、Hystrix是什么?
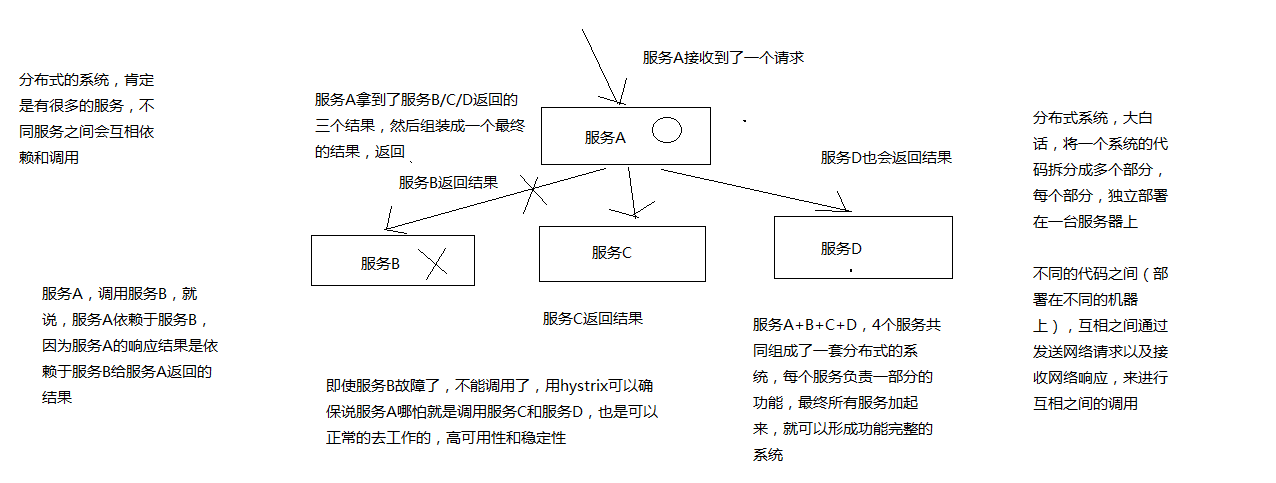
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。
Hystrix可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制.
Hystrix通过将依赖服务进行资源隔离,进而组织某个依赖服务出现故障的时候,这种故障在整个系统所有的依赖服务调用中进行蔓延,同时Hystrix还提供故障时的fallback降级机制
总而言之,Hystrix通过这些方法帮助我们提升分布式系统的可用性和稳定性
2.Hystrix的设计原则是什么?
hystrix为了实现高可用性的架构,设计hystrix的时候,一些设计原则是什么???
(1)对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护
(2)在复杂的分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延,服务A->服务B->服务C,服务C故障了,服务B也故障了,服务A故障了,整套分布式系统全部故障,整体宕机
(3)提供fail-fast(快速失败)和快速恢复的支持
(4)提供fallback优雅降级的支持
(5)支持近实时的监控、报警以及运维操作
调用延迟+失败,提供容错
阻止故障蔓延
快速失败+快速恢复
降级
监控+报警+运维
4、Hystrix要解决的问题是什么?
在复杂的分布式系统架构中,每个服务都有很多的依赖服务,而每个依赖服务都可能会故障
如果服务没有和自己的依赖服务进行隔离,那么可能某一个依赖服务的故障就会拖垮当前这个服务
举例来说,某个服务有30个依赖服务,每个依赖服务的可用性非常高,已经达到了99.99%的高可用性
那么该服务的可用性就是99.99%的30次方,也就是99.7%的可用性
99.7%的可用性就意味着3%的请求可能会失败,因为3%的时间内系统可能出现了故障不可用了
4.Hystrix的更加细节的设计原则是什么?
(1)阻止任何一个依赖服务耗尽所有的资源,比如tomcat中的所有线程资源
(2)避免请求排队和积压,采用限流和fail fast来控制故障
(3)提供fallback降级机制来应对故障
(4)使用资源隔离技术,比如bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术),来限制任何一个依赖服务的故障的影响
(5)通过近实时的统计/监控/报警功能,来提高故障发现的速度
(6)通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
(7)保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
调用这个依赖服务的时候,client调用包有bug,阻塞,等等,依赖服务的各种各样的调用的故障,都可以处理

6、Hystrix是如何实现它的目标的?
(1)通过HystrixCommand或者HystrixObservableCommand来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离
(2)对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是99.5%的访问时间,但是一般我们可以自己设置一下
(3)为每一个依赖服务维护一个独立的线程池,或者是semaphore,当线程池已满时,直接拒绝对这个服务的调用
(4)对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计
(5)如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
(6)当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制
(7)对属性和配置的修改提供近实时的支持
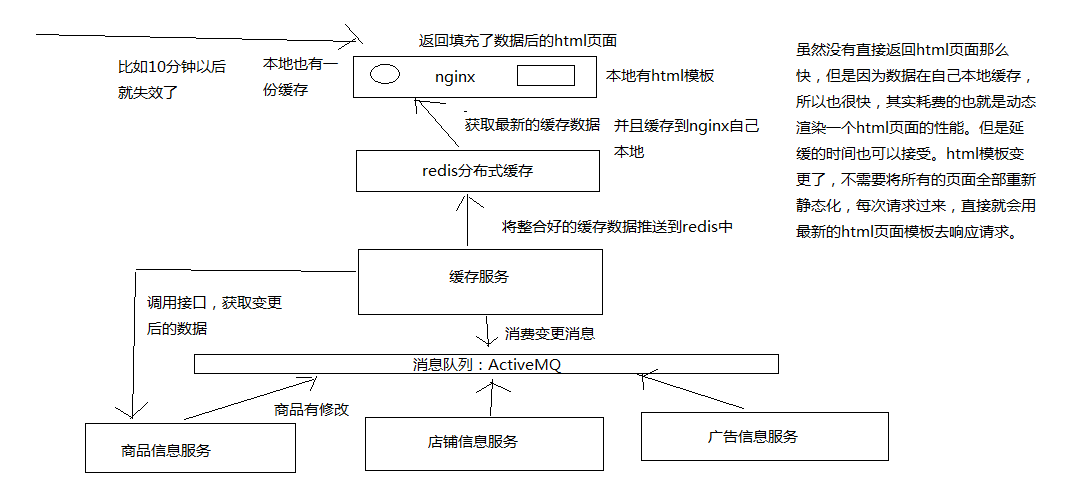
缓存服务,订阅一个MQ的消息变更,如果有消息变更的话,那么就会发送一个网络请求,调用一个底层的对应的源数据服务的接口,去获取变更后的数据
将获取到的变更后的数据填充到分布式的redis缓存中去。
商品服务接口调用故障,导致缓存服务资源耗尽