索引维护的两个重要方面是索引碎片和统计信息。
一:索引碎片
降低碎片的产生,当索引上的页不在具有物理连续性时,就会产生碎片,下面的情景会产生碎片:
INSERT操作、UPDATE操作、DBCC SHRINKDATABASE操作
除了查询数据之外,对索引的绝大部分操作都会引起碎片,当然如果数据库是只读的则另当别论。创建索引后,需要实时或者周期性监控索引的碎片,以便降低碎片带来的性能影响。
1.产生碎片的操作
碎片问题主要通过sys.dm_db_index_physical_stats来查看,当索引上的页不在具有连续性时就会产生碎片,碎片就是索引上页拆分的物理结果。
(1)插入操作 INSERT操作子聚集索引和非聚集索引上都可以产生碎片。
在设计聚集索引时,有时会使用业务键或者GUID等类型做聚集索引,这时候就很容易产生碎片。
使用NEWGUID产生的唯一键具有唯一性,但又很随机。当一个新数据插入聚集索引时,很高几率会插在一个已经存在数据的页上,当空间不够时,就会产生分页,从而导致碎片。
IF OBJECT_ID('dbo.Table_GUID') IS NOT NULL
DROP TABLE dbo.Table_GUID
CREATE TABLE Table_GUID
(
RowID UNIQUEIDENTIFIER CONSTRAINT DF_GUIDValue DEFAULT NEWID()--使用GUID作为默认值
,Name sysname,Value VARCHAR(2000) );
--插入数据,注意此时还没有创建索引
INSERT INTO dbo.Table_GUID
( Name, Value )
SELECT name,REPLICATE('X',2000)
FROM sys.columns
--在列上创建聚集索引
CREATE CLUSTERED INDEX CLUS_UsingUniqueidentifier ON dbo.Table_GUID(RowID);
--查看平均碎片
SELECT
index_type_desc,
index_depth,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Table_GUID'),NULL,NULL,'DETAILED')
平均碎皮为0,因为在插入后才建索引:

--执行插入操作
--插入新数据
INSERT INTO dbo.Table_GUID
( Name, Value )
SELECT name,REPLICATE('X',2000) FROM sys.objects
--查看平均碎片
SELECT
index_type_desc,
index_depth,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Table_GUID'),NULL,NULL,'DETAILED')

碎片迅速增长,这种情况不是简单的重建、重组索引可以解决的,更主要的是改变索引的设计,业务键和GUID存在类似的情况
另外一个在INSET操作过程中产生碎片的地方就是在非聚集索引上,非聚集索引上没有强烈要求自增,当对一个产品名加非聚集索引时,下一个新的数据可能以M字母开头,这样一来,就必须存放在接近索引的中间部分。如果没有空间,同样也会产生分页从而导致碎片。
--在前面的例子中加一个非聚集索引
CREATE NONCLUSTERED INDEX IX_Name ON dbo.Table_GUID(Name) INCLUDE (Value);
--查看平均碎片 再次执行相同的插入,然后再次检查
INSERT INTO dbo.Table_GUID
( Name, Value )
SELECT name,REPLICATE('X',2000) FROM sys.objects
--查看平均碎片
SELECT
index_type_desc,
index_depth,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Table_GUID'),NULL,NULL,'DETAILED')

碎片迅速增加,当INSET操作发生时,产生碎片在所难免,唯一要做的是,尽可能降低碎片的产生速率
(2)跟新操作
IF OBJECT_ID('dbo.Update_Fr') IS NOT NULL
DROP TABLE dbo.Update_Fr;
CREATE TABLE dbo.Update_Fr
(
RowID INT IDENTITY(1,1),
Name sysname,
Value VARCHAR(2000)
);
INSERT INTO dbo.Update_Fr
(
name,Value
)SELECT name,REPLICATE('X',1000)
FROM sys.columns
CREATE CLUSTERED INDEX CLUS_UsingUniqueidentifier ON dbo.Update_Fr(RowID);
--检查一下索引情况
SELECT
index_type_desc,
index_depth,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.Table_GUID'),NULL,NULL,'DETAILED')

--更新数据,让数据变长
UPDATE dbo.Update_Fr
SET Value= REPLICATE('X',2000)
WHERE RowID%5=1
同样碎片增长非常快。
第二种情况,即键值上的改变致使碎片产生。当索引上键值改变时,数据必须更改存放位置,如果在聚集索引上的键值经常需要改变,意味着聚集索引设计的不合理
创建一个非聚集索引
--创建一个非聚集索引 CREATE NONCLUSTERED INDEX IX_Name ON dbo.Update_Fr(Name) INCLUDE (Value);
--通过REVERSE函数把名称反转,监控更新前后的碎片操作
SELECT
index_type_desc,
index_depth,
index_level,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Update_Fr'),NULL,NULL,'DETAILED')
UPDATE dbo.Update_Fr
SET name =REVERSE(Name) WHERE RowID%9=1
SELECT
index_type_desc,
index_depth,
index_level,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Update_Fr'),NULL,NULL,'DETAILED')


3.收缩操作:
收缩可以控制数据库或者文件的大小,执行的时候,从数据文件中最大的页号所在的区开始向前回收,但是这个操作不会考虑已经被移除的数据页,只会从文件的最后一页开始向前回收。
--收缩操作
GO
IF DB_ID(N'Fragmentation') IS NOT NULL
DROP DATABASE Fragmentation
GO
CREATE DATABASE Fragmentation
GO
USE Fragmentation
GO
IF OBJECT_ID('dbo.FirstTable') IS NOT NULL
DROP TABLE dbo.FirstTable
CREATE TABLE dbo.FirstTable
(
RowID INT IDENTITY(1,1),
Name sysname,
value VARCHAR(2000),
CONSTRAINT PK_FirstTable PRIMARY KEY CLUSTERED(RowID)
);
INSERT INTO dbo.FirstTable
( Name, value )
SELECT name,REPLICATE('X',2000) FROM sys.columns
IF OBJECT_ID('dbo.SecondTable') IS NOT NULL
DROP TABLE dbo.SecondTable
CREATE TABLE dbo.SecondTable
(
RowID INT IDENTITY(1,1),
Name sysname,
value VARCHAR(2000),
CONSTRAINT PK_SecondTable PRIMARY KEY CLUSTERED(RowID)
);
INSERT INTO dbo.SecondTable
( Name, value )
SELECT name,REPLICATE('X',2000) FROM sys.columns
GO
INSERT INTO dbo.FirstTable
( Name, value )
SELECT name,REPLICATE('X',2000) FROM sys.columns
INSERT INTO dbo.SecondTable
( Name, value )
SELECT name,REPLICATE('X',2000) FROM sys.columns
--检查索引碎片,在删除表SecondTable
SELECT
index_type_desc,
index_depth,
index_level,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.FirstTable'),NULL,NULL,'DETAILED')
GO
IF OBJECT_ID('dbo.SecondTable') IS NOT NULL
DROP TABLE dbo.SecondTable;
GO
SELECT
index_type_desc,
index_depth,
index_level,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.FirstTable'),NULL,NULL,'DETAILED')
由于SQL Server不会自动回收,所以调用DBCC SHRINKDATABASE命令来收缩数据库。
DBCC SHRINKDATABASE(Fragmentation)
查看索引碎片:
SELECT
index_type_desc,
index_depth,
index_level,
page_count,
record_count,
CAST(avg_fragmentation_in_percent AS DECIMAL(6,2)) AS avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
CAST(avg_page_space_used_in_percent AS DECIMAL(6,2)) AS avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.FirstTable'),NULL,NULL,'DETAILED')
碎片明显增加
2.碎片带来的问题
1.带来额外的I/O
2.影响连续性读
数据页越多,延时越久,性能越差
IF OBJECT_ID('dbo.IndexIO') IS NOT NULL
DROP TABLE dbo.IndexIO;
CREATE TABLE dbo.IndexIO(
RowID INT IDENTITY(1,1),
Name sysname,
Value NVARCHAR(2000)
);
INSERT INTO dbo.IndexIO
( RowID, Name, Value )
SELECT name,REPLICATE('X',1000) FROM sys.columns
CREATE CLUSTERED INDEX CLUS_IndexIO ON dbo.IndexIO(RowID);
UPDATE dbo.IndexIO
SET Value=REPLICATE('X',2000) WHERE RowID%5=1
--查看索引占用的页数
SELECT i.name,ps.in_row_data_page_count
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats ps
ON i.object_id=ps.object_id AND i.index_id=ps.index_id
WHERE i.name='CLUS_IndexIO'
--重建索引
ALTER INDEX CLUS_IndexIO ON dbo.IndexIO REBUILD
--再次查看
SELECT i.name,ps.in_row_data_page_count
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats ps
ON i.object_id=ps.object_id AND i.index_id=ps.index_id
WHERE i.name='CLUS_IndexIO'
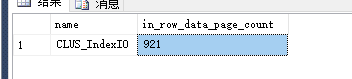
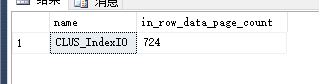
在表上创建索引,并进行了一次UPDATA操作后,产生了碎片,索引占用页变成了921;而在重建索引之后,占用的页减少到了724,随着操作的增多,索引所占的页也会增多,操作时所用的I/O也增多。
(2)连续读
碎片的另外一个影响就是降低连续读,把连续的数据页一次性加载到内存中,供后续使用,这样能很大程度上降低每次读取的I/O数量
3.降低碎片的操作
索引重建、索引重组、和删除重建
(1)索引重建
创建一个与现有索引定义一样,同时保存原有索引可用的方法,在创建完毕后,就删除索引。
好处:重建的索引是按照原有索引定义的,而且它是一个具有连续页的索引,在高度碎片化的索引中,重建是最快的方式,
提示:当聚集索引包含了image、ntext、text、varchar(max)、nvarchar(max)、varbinary(max)、xml等这些类型时,不能使用这种方式。
CREATE INDEX 和ALTER INDEX重建时,需要考虑下面的因素:
索引的定义需要修改,比如增、删列等,用CREATE INDEX
索引需要移动到别的文件组,用CREATE INDEX
索引分区需要改变,也用CREATE INDEX
多于一个索引需要在同一个语句中创建时,或者索引中的一个分区需要重建,用ALTER INDEX语句
重建索引的负面影响之一是重建过程中对空间的占用会很高,平均需要占用120%的额外空间,
(2)重组索引
通过重组索引,索引上的逻辑顺序和物理顺序就相同了,重组索引相对开销比较低,比较适合常规使用,重组时使用ALTER INDEX并带上REORGANIZE选项,还能对单一分区的索引进行重组,这是REBUILD 选项中不支持的
(3)删除并重建索引索引除了性能之外还有组织数据的功能,如果对大表频繁操作的表、资源压力很大的系统进行这种删除操作,除了增加压力之外,还容易导致数据混乱。建议使用如下脚本重建索引:CREATE NONCLUSTERED COLUMNSTORE INDEX csindx_simple ON simpletable(orderDateKey,DueDateKey,ShipDateKey) WITH(DROP_EXISTING)
如果索引是聚集索引,那么表上其他索引都会在删除聚集索引后被迫全部重建,因为聚集索引和堆表以不同结构存放数据。没有聚集索引的表就是堆表,所以删除聚集索引之后的表就成了堆表。
如果索引上是主键或者具有唯一性约束,或者有外键,那么即使删除也会增加数据混乱的分险
让SqlServer自己维护统计信息
1.使用DMO:
SELECT DueDate FROM sales.SalesOrderHeader
WHERE duedate ='2001-07-13 00:00:00.000'
AND OrderDate='2001-07-13 00:00:00.000'
GO
SELECT DueDate FROM sales.SalesOrderHeader
WHERE OrderDate BETWEEN '20010701' AND '20010731'
AND duedate BETWEEN '20010701' AND '20010731'
GO
SELECT DueDate,OrderDate FROM sales.SalesOrderHeader
WHERE duedate BETWEEN '20010701' AND '20010731'
GO
SELECT CustomerID,OrderDate FROM sales.SalesOrderHeader
WHERE DueDate BETWEEN '20010701' AND '20010731'
AND OrderDate BETWEEN '20010701' AND '20010731'
--使用DMO展示信息的产生
SELECT DB_NAME(mid.database_id) AS database_name, OBJECT_NAME(mid.object_id,mid.database_id) AS table_name, mid.equality_columns, mid.inequality_columns, mid.included_columns, (migs.user_seeks + migs.user_scans)* migs.avg_user_impact AS Impact, migs.avg_total_user_cost * (migs.avg_user_impact/100.0)*(migs.user_seeks+migs.user_scans) AS Score, migs.user_seeks, migs.user_scans FROM sys.dm_db_missing_index_details mid INNER JOIN sys.dm_db_missing_index_groups mig ON mid.index_handle=mig.index_handle INNER JOIN sys .dm_db_missing_index_group_stats migs ON mig.index_group_handle=migs.group_handle ORDER BY migs.avg_total_user_cost * (migs.avg_user_impact/100.0)* (migs.user_seeks+migs.user_scans) DESC

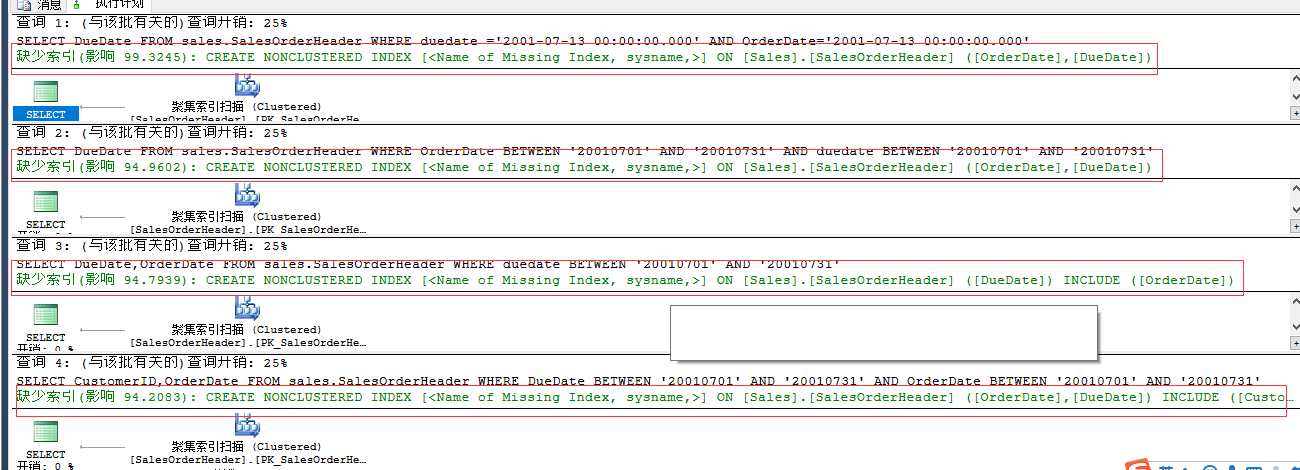
重点关注Impact和Score列,Impact列是优化器预估加了索引之后,用户的查找和扫描操作“可能”提高的程度;Score是一个预估能减少的开销百分比。
最后的缺失索引建议应该如下使用:
CREATE NONCLUSTERED INDEX missing_index_SalesOrderHeader ON Sales.SalesOrderHeader([DueDate],[OrderDate]) INCLUDE ([CustomerID])
2.数据库引擎优化顾问
DTA有一个缺点:就是强烈依赖于当前数据库的负载,少量的改动都会导致DTA给出的建议有很大误差。
(1.)针对单语句优化(缺失索引)
SELECT DueDate FROM sales.SalesOrderHeader WHERE duedate ='2001-07-13 00:00:00.000' AND OrderDate='2001-07-13 00:00:00.000'
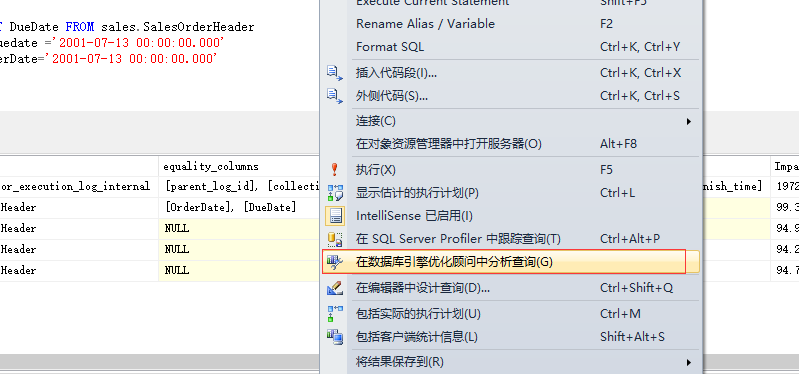
在查询界面右键,然后选择在DTA中分析查询选项即可。
--使用DMO侦测索引问题
--查找未被使用过的索引,可以考虑删除
SELECT '['+DB_NAME()+'].['+su.[name]+'].['+o.[name]+']' AS [statement],i.[name] AS [index_name],
ddius.[user_seeks]+ddius.[user_scans] +ddius.[user_lookups] AS [user_reads],
ddius.[user_updates] AS [user_writes],
SUM(sp.rows) AS [total_rows]
FROM sys.dm_db_index_usage_stats ddius
INNER JOIN sys.indexes i ON ddius.[object_id]=i.[object_id] AND i.[index_id]=ddius.[index_id]
INNER JOIN sys.partitions SP ON ddius.[object_id]=SP.[object_id] AND sp.[index_id]=ddius.[index_id]
INNER JOIN sys.objects o ON ddius.[object_id] =o.[object_id]
INNER JOIN sys.sysusers su ON o.[schema_id]=su.[uid]
WHERE ddius.[database_id] =DB_ID() --current database only
AND OBJECTPROPERTY(ddius.[object_id],'IsUserTable')=1
AND ddius.[index_id]>0
GROUP BY su.[name],o.[name],i.[name],ddius.[user_seeks]+ddius.[user_scans]+ddius.[user_lookups],ddius.[user_updates]
HAVING ddius.[user_seeks]+ddius.[user_scans]+ddius.[user_lookups]=0
ORDER BY ddius.[user_updates] DESC, su.[name],o.[name],i.[name]
--可能不合理的非聚集索引(读大于写)Insert和Update操作对索引碎片的影响非常大
SELECT
OBJECT_NAME(ddius.[object_id]) AS [Table Name],
i.name AS [Index Name],
i.index_id,
ddius.user_updates AS [Total_Writes],
ddius.user_seeks,
ddius.user_scans,
ddius.user_lookups AS [Total Reads],
ddius.user_updates-(user_seeks+ddius.user_scans+ddius.user_lookups) AS [Difference]
FROM sys.dm_db_index_usage_stats AS ddius WITH(NOLOCK)
INNER JOIN sys.indexes AS i WITH(NOLOCK) ON ddius.[object_id]=i.[object_id] AND i.index_id =ddius.index_id
WHERE OBJECTPROPERTY(ddius.[object_id],'IsUserTable')=1
AND ddius.database_id=DB_ID()
AND ddius.user_updates>(user_seeks+user_scans+user_lookups)
AND i.index_id>1
ORDER BY [Difference] DESC,[Total_Writes] DESC,[Total Reads] ASC;
--索引上的碎片,只针对页数超过500页
SELECT
'['+DB_NAME()+'].['+OBJECT_SCHEMA_NAME(ddips.[object_id],DB_ID())
+'].['+OBJECT_NAME(ddips.[object_id],DB_ID())+']' AS [statement],
i.[name] AS [index_name],ddips.[index_type_desc], ddips.[partition_number],
ddips.[alloc_unit_type_desc],ddips.[index_depth],ddips.[index_level],
CAST(ddips.[avg_fragmentation_in_percent] AS SMALLINT) AS [avg_frag_%],
CAST(ddips.[avg_fragment_size_in_pages] AS SMALLINT ) AS [avg_frag_size_in_pages],
ddips.[fragment_count],
ddips.[page_count]
FROM sys.dm_db_index_physical_stats(DB_ID(),NULL,NULL,NULL,'limited') AS ddips
INNER JOIN sys.[indexes] i ON ddips.[object_id]=i.[object_id] AND ddips.[index_id]=i.[index_id]
WHERE ddips.[avg_fragmentation_in_percent]>15
AND ddips.[page_count]>500
ORDER BY ddips.[avg_fragmentation_in_percent],
OBJECT_NAME(ddips.[object_id],DB_ID()),i.[name]
--还能监控锁情况
SELECT '['+DB_NAME(ddios.[database_id])+'].['+su.[name]+'].['+o.[name]+']' AS [statement],
i.[name] AS 'index_name',
ddios.[partition_number],
ddios.[row_lock_count],
ddios.[row_lock_wait_count],
CAST(100.0*ddios.[row_lock_wait_count]/(ddios.[row_lock_count]) AS DECIMAL(5,2)) AS [%_time_blocked],
ddios.[row_lock_wait_in_ms],
CAST(1.0*ddios.[row_lock_wait_in_ms]/ddios.[row_lock_wait_count] AS DECIMAL(15,2)) AS [avg_row_lock_wait_in_ms]
FROM sys.dm_db_index_operational_stats(DB_ID(),NULL,NULL,NULL) ddios
INNER JOIN sys.indexes i ON ddios.[object_id]=i.[object_id]
AND i.[index_id]=ddios.[index_id]
INNER JOIN sys.objects o ON ddios.[object_id]=o.[object_id]
INNER JOIN sys.sysusers su ON o.[schema_id]=su.[uid]
WHERE ddios.row_lock_wait_count>0
AND OBJECTPROPERTY(ddios.[object_id],'IsUserTable')=1
AND i.[index_id]>0
ORDER BY ddios.[row_lock_wait_count] DESC,su.[name],
o.[name],i.[name]
--识别闩锁
SELECT '['+ DB_NAME()+ '].['+ OBJECT_SCHEMA_NAME(ddios.[object_id])+'].['+ OBJECT_NAME(ddios.[object_id])+']' AS [objcet_name],
i.[name] AS index_name,
ddios.page_io_latch_wait_count,
ddios.page_io_latch_wait_in_ms,
(ddios.page_io_latch_wait_in_ms/ddios.page_io_latch_wait_count) AS avg_page_io_latch_wait_in_ms
FROM sys.dm_db_index_operational_stats(DB_ID(),NULL,NULL,NULL) ddios
INNER JOIN sys.indexes i ON ddios.[object_id]=i.[object_id] AND i.index_id=ddios.index_id
WHERE ddios.page_io_latch_wait_count>0
AND OBJECTPROPERTY(i.object_id,'IsUserTable')=1
ORDER BY ddios.page_io_latch_wait_count DESC,
avg_page_io_latch_wait_in_ms DESC