题记
开始学习python开发工具了,不得不说,确实简单好用。我打算先整个批量验证thinkphp日志泄露的流程性代码。下载安装了pycharm,激活码却没用。谁有新的激活码可以帮帮我,等到期了看看要不要整个补丁,先用着玩吧。
一、先学会获取第一页的内容,首先从链接开始。
//这里的意思是把要请求的第一页的链接构造好然后经过requests请求获取页面信息。
import requests import base64 search_data='app="thinkphp"' url='https://fofa.so/result?qbase64=' #这里需要强制转换下编码 search_data_bs=str(base64.b64encode(search_data.encode('utf-8')),"utf-8") urls=url+search_data_bs result=requests.get(urls).content print(result.decode('utf-8'))
//成功获取响应内容,然后在内容里找到我们需要的东西,ip地址。
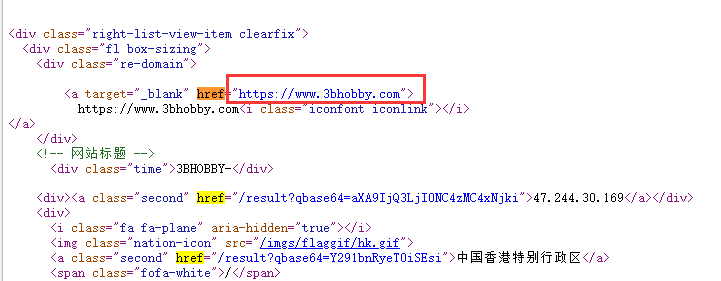
二、获取第一页内ip
import requests from lxml import etree import base64 search_data='app="thinkphp"' url='https://fofa.so/result?qbase64=' #这里需要强制转换下编码 search_data_bs=str(base64.b64encode(search_data.encode('utf-8')),"utf-8") urls=url+search_data_bs #获取访问fofa后的内容 result=requests.get(urls).content #将结果传为能被etree分解的形式 soup = etree.HTML(result) #取想要的字段href,按照特征去除干扰内容 ip_data=soup.xpath('//div[@class="re-domain"]/a[@target="_blank"]/@href') #将数组化形式的内容一个个分隔开来 ipdata=' '.join(ip_data) print(ipdata)
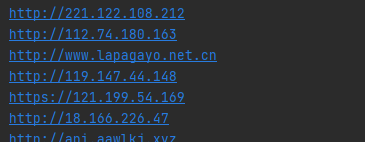
#创建ip.txt并存起来 with open(r'ip.txt','a+') as f: f.write(ipdata+' ') f.close()
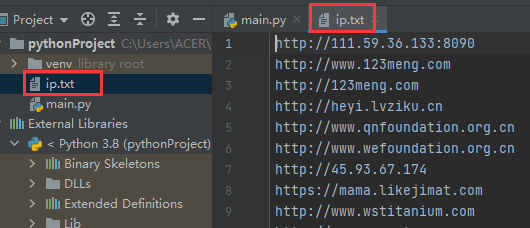
三、翻页加登录状态载入
//这里主要加了page变量与登录验证,通过cookie获取内容,用的时候cookie处换成你自己的就行,因为我不是会员这里只能获取5页。
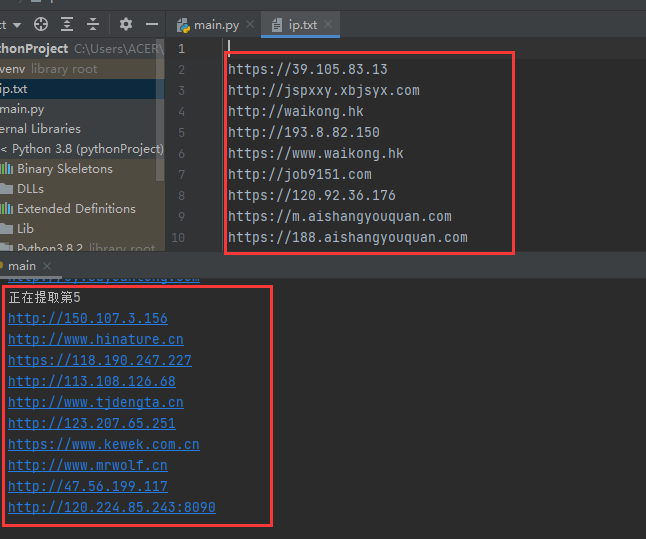
import requests from lxml import etree import base64 import time search_data='app="thinkphp" && country="CN"' headers={ 'cookie':'Hm_lvt_9490413c5eebdadf757c2be2c816aedf=1616029,161698533,16447,16171152; search_history=app%3D%22thinkphp%22; _fofapro_ars_session=1e1e66e681f5ca085635005; referer_url=%2Fresult%3Fq%3Dapp%253D%2522thinkphp%2522%26qbase64%3DYXBwPSJ0aGlua3BocCI%253D%26file%3D%26file%3D; Hm_lpvt_9490413c5eebdadf757c2be2c816aedf=16175430' } for yeshu in range(1,6): url='https://fofa.so/result?page='+str(yeshu)+'&qbase64=' #这里需要强制转换下编码 search_data_bs=str(base64.b64encode(search_data.encode('utf-8')),"utf-8") urls=url+search_data_bs print('正在提取第'+str(yeshu)) try: #获取访问fofa后的内容 result=requests.get(urls,headers=headers,timeout=3).content #将结果传为能被etree分解的形式 soup = etree.HTML(result) #取想要的字段href,按照特征去除干扰内容 ip_data=soup.xpath('//div[@class="re-domain"]/a[@target="_blank"]/@href') #将数组化形式的内容一个个分隔开来 ipdata=' '.join(ip_data) print(ipdata) #创建ip.txt并存起来 with open(r'ip.txt','a+') as f: f.write(ipdata+' ') f.close() except Exception as e: pass
//成功获取并存入到ip.txt
当然,你们可以自己改改,比如加个sys模块进行参数化传值,我觉得反正用户版每次都要复制cookie,还不如复制cookie的时候把该改的一起在页面改了。如果你是永久用户可以找一个key值身份验证的脚本那样当然也方便,或者找个软件。当然也可以参数化一下,然后把python打包成exe。
参考文章
解决PyCharm无法使用lxml库的问题(图解):http://iis7.com/a/nr/wz/202102/8956.html
友情感谢:小迪python开发课