天行健,君子以自强不息;地势坤,君子以厚德载物。——《易经》
本章导读
Spark的初始化阶段、任务提交阶段、执行阶段,始终离不开存储体系。
Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息、计算结果等数据存入内存,极大的提升了系统的执行效率。
4.1 存储体系的概述
4.1.1 块管理器BlockManager的实现
块管理器BlockManager是Spark存储体系中的核心组件,Driver Application和Executor都会创建BlockManager。
BlockManager主要由以下部分组成:
1.shuffle客户端ShuffleClient;
2.BlockManagerMaster(对存在于所有Executor上的BlockManager统一管理)
3.磁盘块管理器DiskBlockManager
4.内存存储MemoryStore
5.磁盘存储DiskStore
6.Tachyon存储TachyonStore
7.非广播Block清理器metadataCleaner和广播Block清理器broadcastCleaner
8.压缩算法实现CompressionCodec
BlockManager要生效,必须要初始化。
初始化代码如下:
def initialize(appId: String): Unit = {
//blockTransferSevice的初始化
blockTransferService.init(this)
//shuffleClient的初始化
//书中解释ShuffleClient默认是BlockTransferService,当有外部的ShuffleService时,调用外部ShuffleService的初始化方法
shuffleClient.init(appId)
blockReplicationPolicy = {
val priorityClass = conf.get(
"spark.storage.replication.policy", classOf[RandomBlockReplicationPolicy].getName)
val clazz = Utils.classForName(priorityClass)
val ret = clazz.getConstructor().newInstance().asInstanceOf[BlockReplicationPolicy]
logInfo(s"Using $priorityClass for block replication policy")
ret
}
//BlockManagerID的创建
val id =
BlockManagerId(executorId, blockTransferService.hostName, blockTransferService.port, None)
val idFromMaster = master.registerBlockManager(
id,
maxOnHeapMemory,
maxOffHeapMemory,
slaveEndpoint)
blockManagerId = if (idFromMaster != null) idFromMaster else id
//shuffleServerId的创建。当有外部的ShuffleService时,创建新的BlockManagerId,否则ShuffleServerId默认使用当前的BlockManager的BlockManagerId
shuffleServerId = if (externalShuffleServiceEnabled) {
logInfo(s"external shuffle service port = $externalShuffleServicePort")
BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort)
} else {
blockManagerId
}
// Register Executors' configuration with the local shuffle service, if one should exist.
//向BlockManagerMaster注册BlockManagerId,当有外部的ShuffleService时,还需要BlockManagerMaster注册ShuffleServerId
if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {
registerWithExternalShuffleServer()
}
logInfo(s"Initialized BlockManager: $blockManagerId")
}
4.1.2 Spark存储体系架构
Spark存储体系的架构关系说明:
- 第一号表示Executor的BlockManager与Driver的BlockManager进行消息通信,例如,注册BlockManager、更新BlockManager、获取Block所在的BlockManager、删除BlockExecutor等;
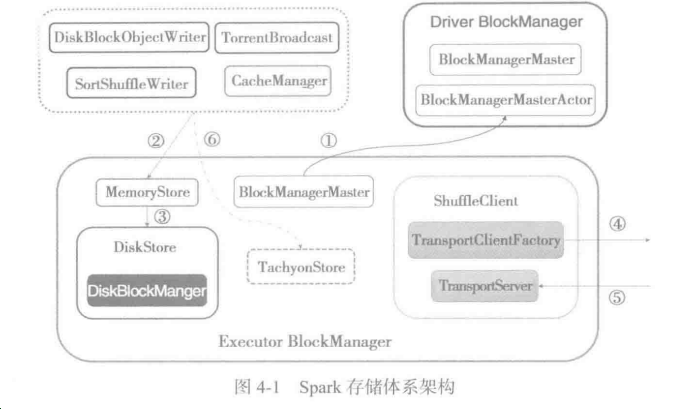
- 第二号表示对BlockManager的读操作和写操作;
- 第三号表示当MemoryStore的内存不足是,写入DiskStore,而DiskStore实际上依赖于DiskBlockManager;
- 第四号表示通过远端节点的Executor的BlockManager的TransportServer提供的RPC服务下载或者上传Block;
- 第五号表示远端节点的Executor的BlockManager访问本地Executor的BlockManager中的TransportServer提供的RPC服务下载或者上传Block;
- 第六号表示当存储体系选择为Tachyon作为存储时,对于BlockManager的读写操作实际上调用了TachyonStore的putBytes、putArray、putIterator、getBytes、getValues等;
Spark目前支持HDFS、Amazon S3两种主流分布式存储系统。
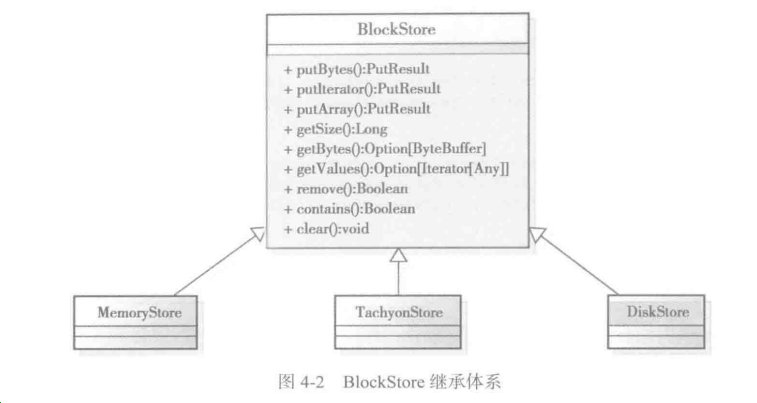
Spark定义了抽象类BlockStore,用于制定所有存储类型的规范。BlockStore的继承体系如下:
4.2 shuffle服务与客服端
Spark分布式部署,每个Task最终运行在不同的机器节点上。map输出与reduce任务极有可能不在同一机器上运行
所以要远程下载map任务的中间输出,因此将ShuffleClient放在存储体系最为合适。
ShuffleClient将Shuffle文件上传到其他Executor或者下载本地的客户端,也提供被其他Executor访问的shuffle的服务。
Spark与hadoop都是采用Netty作为shuffle server。当有外部的ShuffleClient时,新建ExternalShuffleClient,否则默认为BlockTransferService。
BlockTransferService只有在其init方法调用,即被初始化后才提供服务,以默认的NettyBlockTransferService的init方法为例。
NettyBlockTransferService的初始化步骤如下:
1>创建RpcServer
2>构造TransportContext
3>创建RPC客户端工厂TransportClientFactory
4>创建Netty服务器TransportServer,可以修改属性spark.blockManager.port(默认为0,表示随机选择)改变TransferServer的端口。
4.2.1 Block的RPC服务
当map任务与reduce任务处于不同节点时,reduce任务需要从远端节点下载map任务的中间输出,因此NettyBlockRpcServer提供打开,即下载Block文件的功能;
一些情况下,为了容错,需要将Block的数据备份到其他节点上,所以NettyBlockRpcServer还提供了上传Block文件的RPC服务。
NettyBlockRpcServer的实现代码清单:
class NettyBlockRpcServer(
appId: String,
serializer: Serializer,
blockManager: BlockDataManager)
extends RpcHandler with Logging {
private val streamManager = new OneForOneStreamManager()
override def receive(
client: TransportClient,
rpcMessage: ByteBuffer,
responseContext: RpcResponseCallback): Unit = {
val message = BlockTransferMessage.Decoder.fromByteBuffer(rpcMessage)
logTrace(s"Received request: $message")
message match {
case openBlocks: OpenBlocks =>
val blocksNum = openBlocks.blockIds.length
val blocks = for (i <- (0 until blocksNum).view)
yield blockManager.getBlockData(BlockId.apply(openBlocks.blockIds(i)))
val streamId = streamManager.registerStream(appId, blocks.iterator.asJava)
logTrace(s"Registered streamId $streamId with $blocksNum buffers")
responseContext.onSuccess(new StreamHandle(streamId, blocksNum).toByteBuffer)
case uploadBlock: UploadBlock =>
// StorageLevel and ClassTag are serialized as bytes using our JavaSerializer.
val (level: StorageLevel, classTag: ClassTag[_]) = {
serializer
.newInstance()
.deserialize(ByteBuffer.wrap(uploadBlock.metadata))
.asInstanceOf[(StorageLevel, ClassTag[_])]
}
val data = new NioManagedBuffer(ByteBuffer.wrap(uploadBlock.blockData))
val blockId = BlockId(uploadBlock.blockId)
logDebug(s"Receiving replicated block $blockId with level ${level} " +
s"from ${client.getSocketAddress}")
blockManager.putBlockData(blockId, data, level, classTag)
responseContext.onSuccess(ByteBuffer.allocate(0))
}
}
override def receiveStream(
client: TransportClient,
messageHeader: ByteBuffer,
responseContext: RpcResponseCallback): StreamCallbackWithID = {
val message =
BlockTransferMessage.Decoder.fromByteBuffer(messageHeader).asInstanceOf[UploadBlockStream]
val (level: StorageLevel, classTag: ClassTag[_]) = {
serializer
.newInstance()
.deserialize(ByteBuffer.wrap(message.metadata))
.asInstanceOf[(StorageLevel, ClassTag[_])]
}
val blockId = BlockId(message.blockId)
logDebug(s"Receiving replicated block $blockId with level ${level} as stream " +
s"from ${client.getSocketAddress}")
// This will return immediately, but will setup a callback on streamData which will still
// do all the processing in the netty thread.
blockManager.putBlockDataAsStream(blockId, level, classTag)
}
override def getStreamManager(): StreamManager = streamManager
}
4.2.2构造传输上下文TransportContext
TransportContext用于维护传输上下文。
public TransportContext(
TransportConf conf,
RpcHandler rpcHandler,
boolean closeIdleConnections) {
this(conf, rpcHandler, closeIdleConnections, false);
}
TransportContext即可以创建Netty服务,也可以创建Netty访问客户端。TransportContext的组成如下:
TransportConf:主要控制Netty框架提供的shuffle的I/O交互的客户端和服务端线程数目。
RPCHandle:负责shuffle的I/O服务端在接收端到客户端的RPC请求之后,提供打开Block或者上传Block的RPC处理,此处即为NettyBlockRpcServer;
decoder:在shuffle的IO服务端对客户端传来的ByteBuf进行解析,防止丢包和解析错误。
encoder:在shuffle的IO客户端对消息内容进行编码,防止服务端丢包和解析错误。
一个探讨:基于流传输的是一个字节队列,要整理解析成更好理解的数据。
4.2.3RPC客户端工厂TransportClientFactory
TransportClientFactory是创建Netty客户端TransportClient的工厂类,TransportClient用于向Netty服务端发送RPC请求。
TransportContext的createClientFactory方法用于创建TransportClientFactory。
public TransportClientFactory createClientFactory(List<TransportClientBootstrap> bootstraps) {
return new TransportClientFactory(this, bootstraps);
}
以下为TransportClientFactory的代码:
TransportClientFactory由以下几个部分组成:
clientBootstraps:用于缓存客户端列表。
connectionPool:用于缓存客户端连接。
numConnectionPerPeer:节点之间去数据的连接数。
public TransportClientFactory(
TransportContext context,
List<TransportClientBootstrap> clientBootstraps) {
this.context = Preconditions.checkNotNull(context);
this.conf = context.getConf();
//缓存客户端列表
this.clientBootstraps = Lists.newArrayList(Preconditions.checkNotNull(clientBootstraps));
//缓存客户端连接
this.connectionPool = new ConcurrentHashMap<>();
//节点之间取数据的连接数
this.numConnectionsPerPeer = conf.numConnectionsPerPeer();
this.rand = new Random();
IOMode ioMode = IOMode.valueOf(conf.ioMode());
//客户端channel被创建时使用的类
this.socketChannelClass = NettyUtils.getClientChannelClass(ioMode);
//根据Netty的规范,客户端只有Work组,所以此处创建workerGroup,实际上是NioEventLoopGroup
this.workerGroup = NettyUtils.createEventLoop(
ioMode,
conf.clientThreads(),
conf.getModuleName() + "-client");
//汇集ByteBuf但对本地线程缓存禁用的分配器
this.pooledAllocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), false /* allowCache */, conf.clientThreads());
this.metrics = new NettyMemoryMetrics(
this.pooledAllocator, conf.getModuleName() + "-client", conf);
}
关于NIO,为所有的原始类型提供Buffer缓存支持;字符集编码解码解决方案;提供一个新的原始IO抽象Channel,
支持锁和内存映射文件的文件访问接口,提供多路非阻塞式的高伸缩性网络IO。
4.2.4 Netty服务器TransportServer
TransportServer提供Netty实现的服务器端,用于提供RPC服务(比如上传、下载等)。
主要函数init函数,主要根据IP和端口号初始化。
public TransportServer(
TransportContext context,
String hostToBind,
int portToBind,
RpcHandler appRpcHandler,
List<TransportServerBootstrap> bootstraps) {
this.context = context;
this.conf = context.getConf();
this.appRpcHandler = appRpcHandler;
this.bootstraps = Lists.newArrayList(Preconditions.checkNotNull(bootstraps));
boolean shouldClose = true;
try {
init(hostToBind, portToBind);
shouldClose = false;
} finally {
if (shouldClose) {
JavaUtils.closeQuietly(this);
}
}
}
Init函数的代码情况:
主要用于对TransportServer初始化,通过使用Netty框架的EventLoopGroup和ServerBootstrap等API创建shuffle的IO交互的客户端。
private void init(String hostToBind, int portToBind) {
IOMode ioMode = IOMode.valueOf(conf.ioMode());
EventLoopGroup bossGroup =
NettyUtils.createEventLoop(ioMode, conf.serverThreads(), conf.getModuleName() + "-server");
EventLoopGroup workerGroup = bossGroup;
PooledByteBufAllocator allocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), true /* allowCache */, conf.serverThreads());
bootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NettyUtils.getServerChannelClass(ioMode))
.option(ChannelOption.ALLOCATOR, allocator)
.option(ChannelOption.SO_REUSEADDR, !SystemUtils.IS_OS_WINDOWS)
.childOption(ChannelOption.ALLOCATOR, allocator);
this.metrics = new NettyMemoryMetrics(
allocator, conf.getModuleName() + "-server", conf);
if (conf.backLog() > 0) {
bootstrap.option(ChannelOption.SO_BACKLOG, conf.backLog());
}
if (conf.receiveBuf() > 0) {
bootstrap.childOption(ChannelOption.SO_RCVBUF, conf.receiveBuf());
}
if (conf.sendBuf() > 0) {
bootstrap.childOption(ChannelOption.SO_SNDBUF, conf.sendBuf());
}
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
RpcHandler rpcHandler = appRpcHandler;
for (TransportServerBootstrap bootstrap : bootstraps) {
rpcHandler = bootstrap.doBootstrap(ch, rpcHandler);
}
context.initializePipeline(ch, rpcHandler);
}
});
InetSocketAddress address = hostToBind == null ?
new InetSocketAddress(portToBind): new InetSocketAddress(hostToBind, portToBind);
channelFuture = bootstrap.bind(address);
channelFuture.syncUninterruptibly();
port = ((InetSocketAddress) channelFuture.channel().localAddress()).getPort();
logger.debug("Shuffle server started on port: {}", port);
}
4.2.5获取远程shuffle文件
NettyBlockTransferService的fetchBlocks方法用于获取远程shuffle文件,实际上是利用NettyBlockTransferService创建Netty服务。
4.2.6 上传shuffle文件
NettyBlockTransferService的uploadBlock方法用于上传shuffle文件到远程Executor,实际上也是利用NettyBlockTransferService中创建的Netty服务。
1>创建Netty服务的客户端,客户端连接的hostname和port正是我们随机选择的BlockManager的hostname和port。
2>将Block的存储界别StorageLevel序列化。
3>将Block的ByteBuffer转化为数组,便于序列化。
4>将appId、execId、blockId、序列化的StorageLevel、转换位数组的Block封装为UploadBlock,并将UploadBlock序列化为字节数组。
5>最终调用Netty客户端的sendRpc方法将字节数组上传,回调函数RpcResponseCallback,根据RPC的结果更改上传状态。
override def uploadBlock(
hostname: String,
port: Int,
execId: String,
blockId: BlockId,
blockData: ManagedBuffer,
level: StorageLevel,
classTag: ClassTag[_]): Future[Unit] = {
val result = Promise[Unit]()
val client = clientFactory.createClient(hostname, port)
// StorageLevel and ClassTag are serialized as bytes using our JavaSerializer.
// Everything else is encoded using our binary protocol.
val metadata = JavaUtils.bufferToArray(serializer.newInstance().serialize((level, classTag)))
val asStream = blockData.size() > conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM)
val callback = new RpcResponseCallback {
override def onSuccess(response: ByteBuffer): Unit = {
logTrace(s"Successfully uploaded block $blockId${if (asStream) " as stream" else ""}")
result.success((): Unit)
}
override def onFailure(e: Throwable): Unit = {
logError(s"Error while uploading $blockId${if (asStream) " as stream" else ""}", e)
result.failure(e)
}
}
if (asStream) {
val streamHeader = new UploadBlockStream(blockId.name, metadata).toByteBuffer
client.uploadStream(new NioManagedBuffer(streamHeader), blockData, callback)
} else {
// Convert or copy nio buffer into array in order to serialize it.
val array = JavaUtils.bufferToArray(blockData.nioByteBuffer())
client.sendRpc(new UploadBlock(appId, execId, blockId.name, metadata, array).toByteBuffer,
callback)
}
result.future
}
4.3 BlockManagerMaster对BlockManager的管理
BlockManagerMaster的主要作用是什么?
答案:Driver上的BlockManagerMaster对于存在于Executor上的BlockManager统一管理,比如Executor需要向Driver发送注册BlockManager、
更新Executor上Block的最新信息、询问所需要的Block目前所在的位置以及当Executor运行结束需要将次Executor移除等。
第二个问题:Driver与Executor位于不同机器中,该如何实现?
Driver上的BlockManagerMaster会持有BlockManagerMasterActor,所有Executor也会从ActorSystem中获取BlockManagerMasterActor的引用。
4.3.1 BlockManagerMasterActor
BlockManagerMasterActor只存在于Driver上,Executor从ActorSystem获取的BlockManagerMasterActor的引用,然后给BlockManagerMasterActor发送消息,
实现和Driver交互。
BlockManagerMasterActor维护的很对缓存数据结构。
blockManagerInfo:缓存所有的BlockManagerId以及BlockManager的信息。
blockManagerIdByExecutor:缓存executorId与其拥有的BlockManagerId之间的映射关系。
blockLocations:缓存Block与BlockManagerId的映射关系。
4.3.2 询问Driver并获取回复方法
4.3.3 向BlockManagerMaster注册BlockManagerId
4.4 磁盘块管理器DiskBlockManager
4.4.1 DiskBlockManager的构造过程。
BlockManager初始化会创建DiskBlockManager
4.4.2 获取磁盘文件方法getFile
很多代码中使用DiskBlockManager的getFile方法,获取磁盘上的文件。
通过对于getFile的分析,能够掌握Spark磁盘散列文件存储的实现机制。
1>根据文件名计算哈希值。
2>根据哈希值与本地文件一级目录的总数求余数。即为dirId
3>根据哈希值与本地文件一级目录的总数求商数,此商数与二级 目录的数目再求余数,即为subDirId
4>如果dirId/subDirId目录存在,获取dirId/subDirId
def getFile(filename: String): File = {
// Figure out which local directory it hashes to, and which subdirectory in that
val hash = Utils.nonNegativeHash(filename)
val dirId = hash % localDirs.length
val subDirId = (hash / localDirs.length) % subDirsPerLocalDir
// Create the subdirectory if it doesn't already exist
val subDir = subDirs(dirId).synchronized {
val old = subDirs(dirId)(subDirId)
if (old != null) {
old
} else {
val newDir = new File(localDirs(dirId), "%02x".format(subDirId))
if (!newDir.exists() && !newDir.mkdir()) {
throw new IOException(s"Failed to create local dir in $newDir.")
}
subDirs(dirId)(subDirId) = newDir
newDir
}
}
new File(subDir, filename)
}
4.4.3 临时创建Block方法createTempShuffleBlock
当ShuffleMapTask运行结束需要把中间结果临时保存,此时就调用createTempShuffleBlock方法创建临时的Block,并返回TempShuffleBlockId与其文件的对偶。
4.5 磁盘存储DiskStore
当MemoryStore没有足够空间时,就会使用DiskStore将块存入磁盘,DiskStore继承自BlockStore,并实现了getBytes、putBytes等方法。
4.5.1 NIO读取getBytes
getBytes方法通过DiskBlockManager的getFile方法获取文件。然后使用NIO将文件读取到ByteBuffer。
def getBytes(blockId: BlockId): BlockData = {
val file = diskManager.getFile(blockId.name)
val blockSize = getSize(blockId)
securityManager.getIOEncryptionKey() match {
case Some(key) =>
// Encrypted blocks cannot be memory mapped; return a special object that does decryption
// and provides InputStream / FileRegion implementations for reading the data.
new EncryptedBlockData(file, blockSize, conf, key)
case _ =>
new DiskBlockData(minMemoryMapBytes, maxMemoryMapBytes, file, blockSize)
}
}
4.5.2 NIO写入方法putBytes
putBytes方法的作用是通过DiskBlockManager的getFile方法获取文件。然后使用NIO的channel将ByteBuffer写入文件。
4.5.3 数组写入方法putArray
4.5.4 Itetator写入方法putIterator
4.6 内存存储MemoryStore
MemoryStore负责将没有序列化的Java对象数组或者序列化的ByteBuffer存储到内存中。
先看MemoryStore的数据结构。
private[spark] class MemoryStore(
conf: SparkConf,
blockInfoManager: BlockInfoManager,
serializerManager: SerializerManager,
memoryManager: MemoryManager,
blockEvictionHandler: BlockEvictionHandler)
extends Logging {
...
// Note: all changes to memory allocations, notably putting blocks, evicting blocks, and
// acquiring or releasing unroll memory, must be synchronized on `memoryManager`!
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
// A mapping from taskAttemptId to amount of memory used for unrolling a block (in bytes)
// All accesses of this map are assumed to have manually synchronized on `memoryManager`
private val onHeapUnrollMemoryMap = mutable.HashMap[Long, Long]()
// Note: off-heap unroll memory is only used in putIteratorAsBytes() because off-heap caching
// always stores serialized values.
private val offHeapUnrollMemoryMap = mutable.HashMap[Long, Long]()
// Initial memory to request before unrolling any block
private val unrollMemoryThreshold: Long =
conf.getLong("spark.storage.unrollMemoryThreshold", 1024 * 1024)
/** Total amount of memory available for storage, in bytes. */
private def maxMemory: Long = {
memoryManager.maxOnHeapStorageMemory + memoryManager.maxOffHeapStorageMemory
}
if (maxMemory < unrollMemoryThreshold) {
logWarning(s"Max memory ${Utils.bytesToString(maxMemory)} is less than the initial memory " +
s"threshold ${Utils.bytesToString(unrollMemoryThreshold)} needed to store a block in " +
s"memory. Please configure Spark with more memory.")
}
logInfo("MemoryStore started with capacity %s".format(Utils.bytesToString(maxMemory)))
/** Total storage memory used including unroll memory, in bytes. */
private def memoryUsed: Long = memoryManager.storageMemoryUsed
/**
* Amount of storage memory, in bytes, used for caching blocks.
* This does not include memory used for unrolling.
*/
private def blocksMemoryUsed: Long = memoryManager.synchronized {
memoryUsed - currentUnrollMemory
}
def getSize(blockId: BlockId): Long = {
entries.synchronized {
entries.get(blockId).size
}
}
源码中可以看出
第一个变量:
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
整个的内存存储分为两个部分,一个部分被很多的MemoryEntry占据的内存currentMemory,这些内存是通过entries持有的。
另一部分是unrollMemoryMap通过占座方式占用内存currentUnrollMemory。
maxUnrollMemory:当前Driver或者Executor最多展开的Block所占用的内存。
maxMemory:当前Driver或者Executor的最大内存。
currentMemory:当前Driver或者Executor已经使用的内存。
private def memoryUsed: Long = memoryManager.storageMemoryUsed
4.6.1 数据存储方法putBytes
4.6.2 Iterator写入方法putIterator详解
4.6.3 安全展开方法unrollSafely
为防止写入内存的数据过大,导致内存溢出,Spark采用了一种优化方案:
正式写入内存之前,先用逻辑的方式申请内存,如果申请成功,再写入内存,这个过程称为安全展开。
4.6.4确认空闲内存方法ensureFreeSpace
ensureFreeSpace方法用于确认是否具有足够的内存,如果不足,会释放MemoryEntry占用的内存。
4.6.5 内存写入方法putArray
4.6.6尝试写入内存方法tryToput
4.6.7 获取内存数据方法getBytes
用于从entries中获取MemoryEntry。
4.6.8 获取数据方法getValues
用于从entries中获取MemoryEntry 并将blockId和value返回。
4.7 Tachyon存储TachyonStrore
简介:Tachyon是一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存在tachyon里的文件。
把Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件。
主要职责是将那些不需要落地到DFS里的文件,落地到分布式内存文件系统中,来达到共享内存,从而提高效率。同时可以减少内存冗余,GC时间等。
使用Tachyon原因:
1、Spark的shuffleMapTask和ResultTask被划分为不同的Stage,ShuffleMapTask执行完毕将中间结果输出到本地磁盘文件系统中,下一个Stage中的ResultTask通过
shuffleClient下载shuffleMapTask输出到本地磁盘文件系统,读写效率比较低。
2、Spark的计算引擎和存储体系都位于Executor的同一个进程中,计算奔溃后数据丢失
3、不同的Spark可能访问相同的和数据,例如都要访问数据到内存中,重复加载到内存,对象太多导致Java GC问题。
4.7.1 Tachyon简介
位于现有大数据计算框架和大数据存储系统之间的独立一层。
4.7.2 TachyonStore的使用
4.7.3 写入Tachyon内存的方法putIntoTachyonStore
TachyonStore实现了BlockStore的getSize、putBytes、putArray等方法。
其中put方法实际调用了putIntoTachyonStore。putIntoTachyonStore用于将数据写入Tachyon的分布式内存中。
4.7.4 获取序列化数据方法getBytes
4.8 块管理器BlockManager
已经介绍了BlockManager中的主要组件了,现在看看BlockManager的自身实现。
4.8.1 移除内存方法dropFromMemory
当内存不足,可能需要腾出部分内存空间。
4.8.2 状态报告方法reportBlockStatus
reportBlockStatus用于向BlockManagerMasterActor报告Block的状态并且重新注册BlockManager.
4.8.3 单对象块写入方法putSingle
putSingle方法用于将一个对象构成的Block写入存储系统。
4.8.4 序列化字节块写入方法putBytes
putBytes方法将序列化字节组成的Block写入存储系统,实际上也是调用了doPut方法。
4.8.5 数据写入方法doPut
4.8.6 数据块备份方法replicate
4.8.7 创建DiskBlockObjectWriter的方法getDiskWriter
4.8.8 获取本地Block数据方法getBlockData
getBlockData用于从本地获取Block的数据
4.8.9 获取本地shuffle数据方法doGetLocal
当reduce和map任务在同一个节点时,不需要远程拉取,只需要调取doGetLocal方法从本地获取中间处理结果。
1.如果Block允许使用内存,调用MemoryStore的getValues或者getBytes方法获取。
2.如果Block允许使用Tachyon,调用TachyonStore的getBytes方法。
3.如果BLock允许使用DiskStore,调用DiskStore的getBytes方法。
4.8.10 远程获取Block数据方法doGetRemote
4.8.11 获取Block数据方法get
先本地后远程
4.8.12 数据流序列化方法dataSerializeStream
4.9 metadataCleaner和broadcastCleaner
为了有效利用磁盘空间和内存,metadataCleaner和broadcastCleaner分别用于清除blockinfo中很久不用的非广播和广播Block信息。
4.10 缓存管理器CacheManager
用于缓存RDD某个分区计算后的中间结果。
CacheManager只是BlockManager的代理,真正的缓存依然使用的是BlockManager。
4.11 压缩算法
配置属性:spark.io.compression.codec来确定要使用的压缩算法。默认为snappy
4.12 磁盘写入实现DiskBlockObjectWriter
被用于输出Spark任务的中间计算结果。
4.13 块索引shuffle管理器IndexShuffleBlockManager
通常用于获取Block索引文件,并且根据索引文件读取Block文件的数据。
4.14 shuffle内存管理器ShuffleMemeoryManager
用于为执行shuffle操作的线程分配内存池。
4.15 小结
目前主要有MemoryStore、DiskStore和TachyonStore三种组成
