对于查找数据来说,最简单的方法就是从列表的第一个元素开始对列表元素逐个进行判断,直到找到了想要的结果,或者直到列表结尾也没有找到,这种方法称为顺序查找。
一、基本写法
顺序查找的实现很简单。只要从列表的第一个元素开始循环,然后逐个与要查找的数据进 行比较。如果匹配到了,则结束查找。如果到了列表的结尾也没有匹配到,那么这个数据 就不存在于这个列表中。
// 顺序查找 function sequenceSearch($arr, $search) { for ($i = 0; $i < count($arr); $i++) { if ($arr[$i] == $search) { return $i; // 如果在数组中找到了参数search,返回该值的下标。 } } return -1; // 如果没有找到要查找的数据,则返回-1。 } // 测试 $arr = array(1, 2, 4, 11, 25, 39, 78); $res1 = sequenceSearch($arr, 333); echo $res1; // -1 $res2 = sequenceSearch($arr, 11); echo $res2; // 3
二、自组织方式的查找
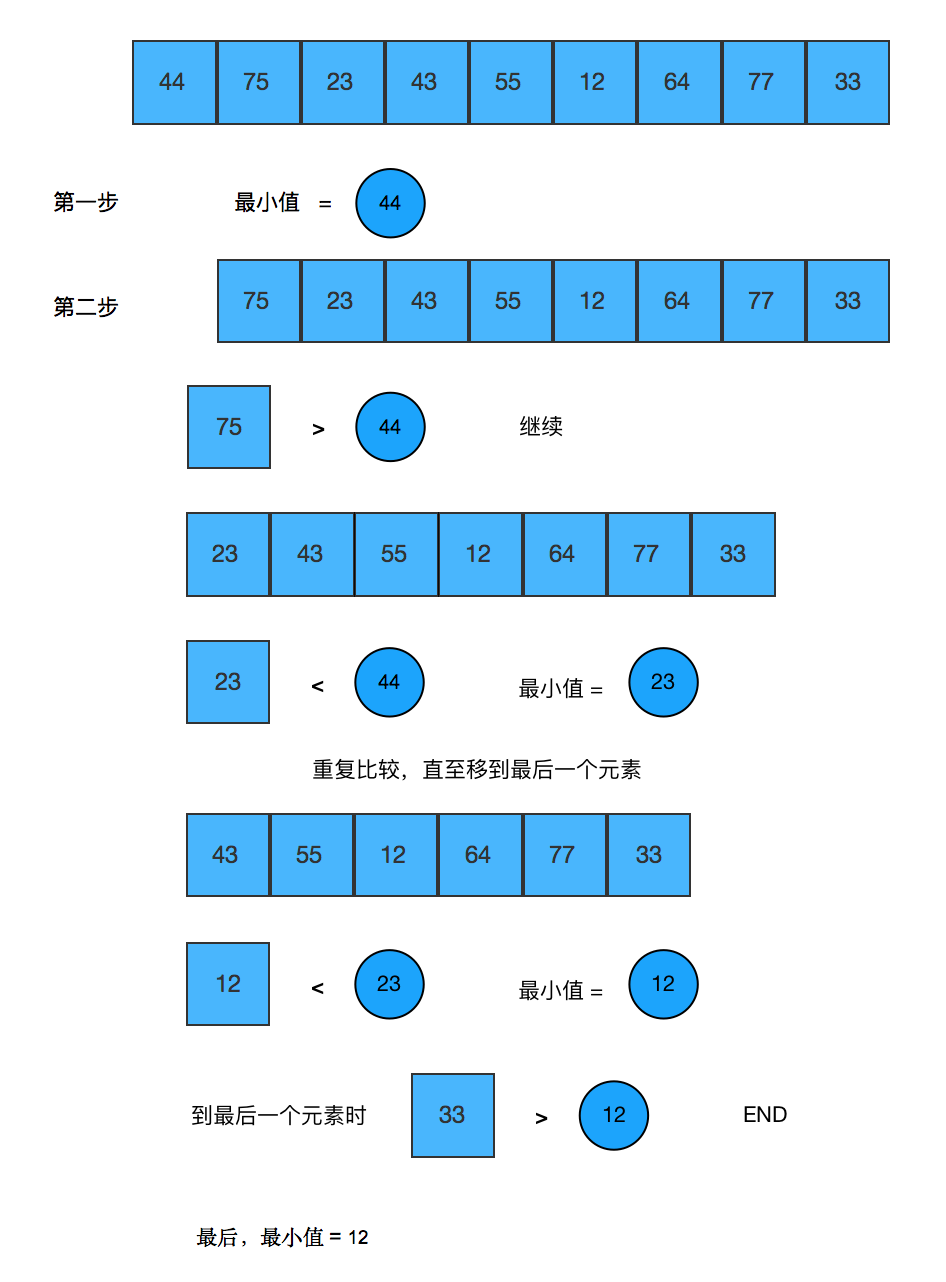
如果在未排序的数组中查找最小值,思路如下:
(1) 将数组第一个元素赋值给一个变量,把这个变量作为最小值。
(2) 开始遍历数组,从第二个元素开始依次同当前最小值进行比较。
(3) 如果当前元素数值小于当前最小值,则将当前元素设为新的最小值。
(4) 移动到下一个元素,并且重复步骤 3。
(5) 当程序结束时,这个变量中存储的就是最小值。
下图演示了该算法的运行过程:
查找最大值算法的思路与查找最小值算法类似,先将数组的第一个元素设为最大值,然后循环对数组剩下的每个元素与当前最大值进行比较。
如果当前元素的值大于当前的最大值,则将该元素的值赋值给最大值变量。代码如下:
function findMin($arr) { $min = $arr[0]; for ($i = 1; $i < count($arr); $i++) { if ($arr[$i] < $min) { $min = $arr[$i]; } } return $min; } function findMax($arr) { $max = $arr[0]; for ($i = 1; $i < count($arr); $i++) { if ($arr[$i] > $max) { $max = $arr[$i]; } } return $max; }
这种对数据的查找遵循“80-20 原则”,即对某一数据集执行的 80% 的查找操作都是对其中 20% 的数据元素进行查找。自组织的方式最终会把这 20% 的数据置于数据集的起始位置,这样便可以通过一个简单的顺序查找快速找到它们。
// 包含自组织方式的 seqSearch() 函数 function seqSearch(&$arr, $data) { for ($i = 0; $i < count($arr); $i++) { if ($arr[$i] == $data) { if ($i > 0) { swap($arr, $i, $i - 1); } return true; } } return false; } function swap(&$arr, $a, $b) { $temp = $arr[$a]; $arr[$a] = $arr[$b]; $arr[$b] = $temp; return $arr; } // 观察 66 被连续查找 3 次之后是如何冒泡到列表前面去的 $arr = array(1, 78, 4, 66, 25, 39, 3); for ($i = 1; $i <= 3; $i++) { seqSearch($arr, 66); print_r($arr); echo '<br>'; } // 输出结果如下: // 1, 78, 66, 4, 25, 39, 3 // 1, 66, 78, 4, 25, 39, 3 // 66, 1, 78, 4, 25, 39, 3
另外一种给顺序查找算法添加自组织数据的方法是:将找到的元素移动到数据集的起始位置,如果这个元素已经很接近起始位置,就不会对它的位置进行交换。要实现这个目标,只需对距离数组起始位置一定范围外的元素进行交换即可——定义哪些是离数组起始位置足够近的元素,通过这个来决定是否需要将元素移动到接近数组的起始位置。再次参照“80-20原则”,我们可以确定以下原则:仅当数据位于数据集的前20%元素之外时,该数据才需要被重新移动到数据集的起始位置。
function seqSearch(&$arr, $data) { $len = count($arr); for ($i = 0; $i < $len; $i++) { if ($arr[$i] == $data && $i > $len * 0.2) { swap($arr, $i, 0); return true; } elseif ($arr[$i] == $data) { return true; } } return false; } function swap(&$arr, $a, $b) { $temp = $arr[$a]; $arr[$a] = $arr[$b]; $arr[$b] = $temp; return $arr; } // test $arr = [4, 5, 1, 8, 10, 1, 3, 0, 1]; $res = seqSearch($arr, 3); var_dump($res); print_r($arr); // 输出结果如下: // true // 3, 5, 1, 8, 10, 1, 4, 0, 1