hive> show tables; 查看hive中的表
hive> show databases;查看数据库
hive> drop table textlines; 删除表
hive> create table textlines(line string);创建一个名字叫textlines的表,表中只有一个类型是string的字段line;
hive> load data local inpath '/Users/lihu/Desktop/crawle/wahah.txt' into table textlines; 把文件wahah.txt中的数据导入textlines表中
hive> select * from textlines;查询textlines表中的数据
hive> create table words(word string);
hive> insert overwrite table words select explode(split(line, ' ')) word from textlines; 把表textlines中的数据用空格分开然后把数据导入到words表中
hive> SELECT word,count(1) FROM words GROUP BY word ORDER BY word;并按照word字段分组排序,查询表中word字段重复的个数
hive> insert overwrite local directory '/Users/lihu/Desktop/crawle/wordcount_result' row format delimited fields terminated by ' ' SELECT word,count(1) FROM words GROUP BY word ORDER BY word;并按照word字段分组排序,查询表中word字段重复的个数并把结果写入wordcount_result
hive> create table people(id int, name string, age int, tel string) row format delimited fields terminated by ' ' stored as textfile; 创建一个名为people的表按照‘ ’来划分字段
hive> load data local inpath '/Users/lihu/Desktop/crawle/heihei.txt' into table people; 把heihei.txt中的数据导入到people中
hive> insert overwrite local directory '/Users/lihu/Desktop/crawle/people' row format delimited fields terminated by ' ' select * from people; 把people表中的数据导出到文件夹people中
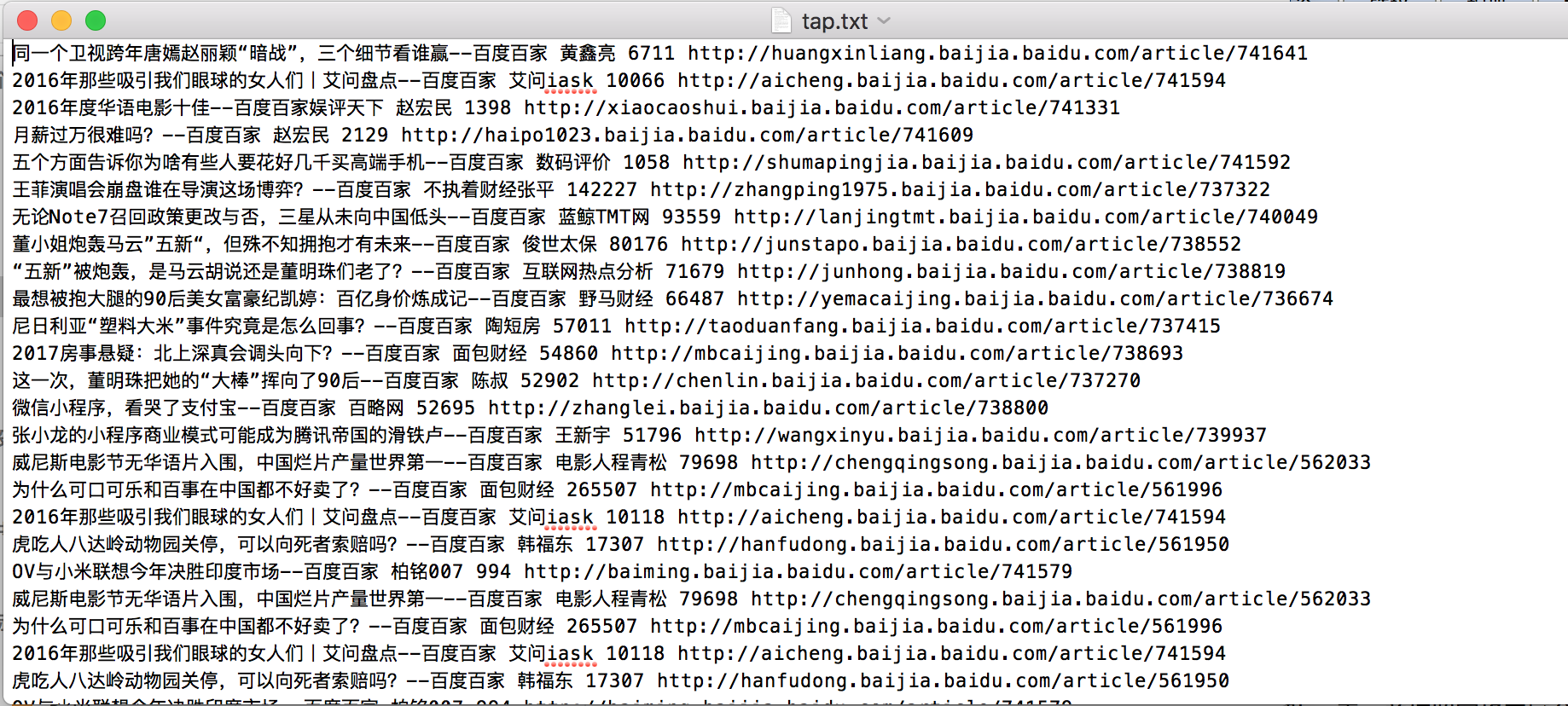
hive> create table tap (title string, author string, numberread int, url string) row format delimited fields terminated by ' ' stored as textfile; 创建tap表,并按照空格来区分字段
hive> load data local inpath '/Users/lihu/Desktop/crawle/tap.txt' into table tap;把tap中的数据导入到tap表中
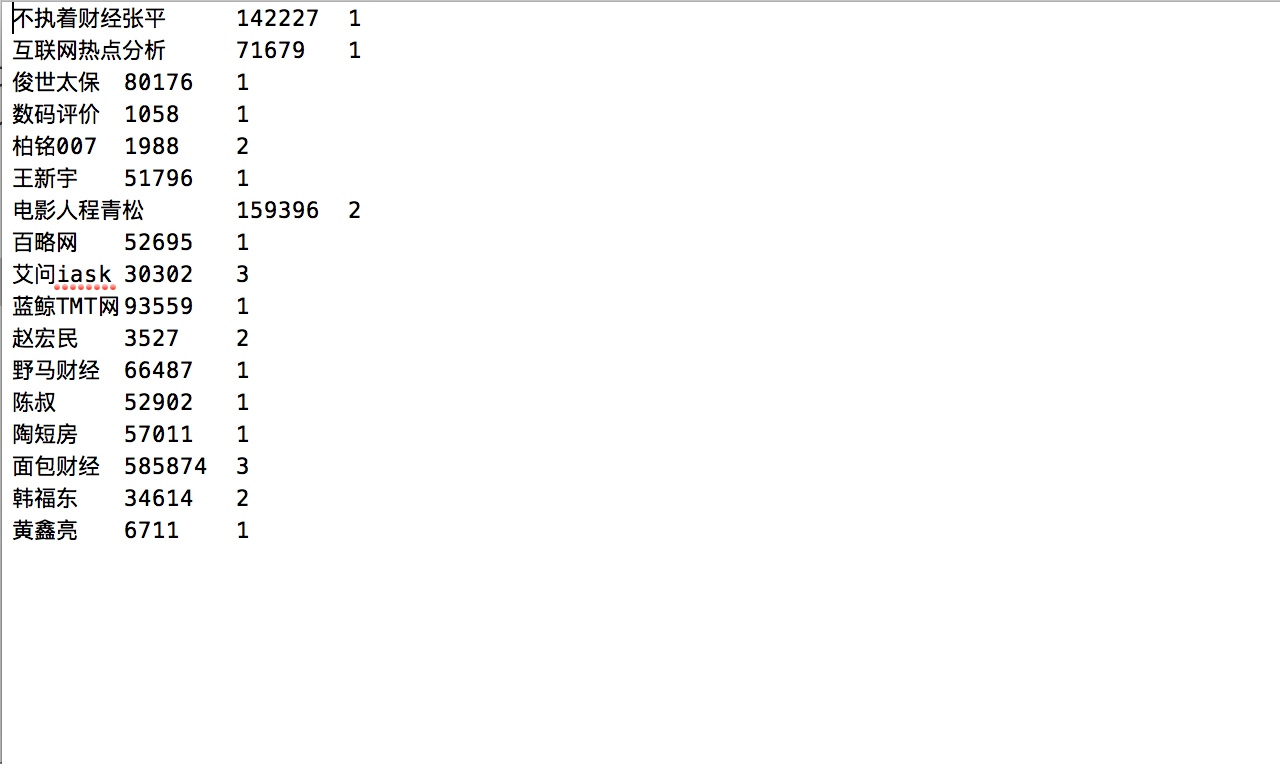
hive> select author, sum(numberread),count(1) from tap group by author;查询作者发布的文章数量和总阅读量
hive> insert overwrite local directory '/Users/lihu/Desktop/crawle/author_result' row format delimited fields terminated by ' ' select author, sum(numberread),count(1) from tap group by author;把查询结果存储在author_result中,并按照‘ ’把各个字段隔开