一 索引原理
如果一本新华字典假如没有目录,想要查找某个字,就不得不从第一页开始查找,一直找到最后一页(如果要找的字在最后一页),这个过程非常耗时,这种场景相当于数据库中的全表扫描的概念,也就是循环表中的每一条记录看看该记录是否满足条件,扫描次数为表的总记录数。
新华字典中都会有目录都有查找方法(比如按拼音查找、按部首查找),假如按拼音查找,我们根据拼音就能瞬速定位到要找的汉字,而这个汉字后面还有这个汉字对应的页数,我们直接翻到该页就能找到,整个查找过程非常快,用时非常短。这个原理就是数据库中索引的原理。这里的按拼音查找、按部首查找是两种不同的查找方式,通过每种方式都能快速找到,在数据库中也有很多查找方式,称之为索引方法,有BTREE、HASH两种方式。
BTREE:一颗倒立的树,每个节点都有父节点,父节点下面的节点称之为子节点(叶子节点),比父节点值小的位于父节点下面的左方,比父节点值大的子节点放置在父节点下面的右下方。
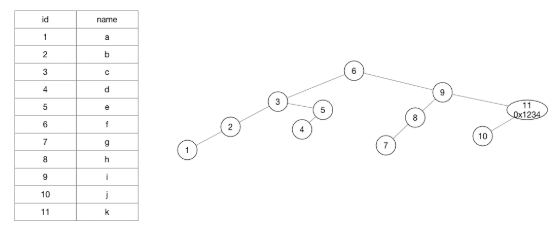
记录索引列的值和对应的记录所在的磁盘位置,每次排除掉一半, 检索一次相当排除掉2的n次幂,使用二叉树排除30次相当于全表排除10亿次。比如查询id=11的值,首先和6比,比6大就排除掉左边的,继续和9比较,11比9大,又排除掉左边的一般,和11进行比较,相等就找到了结果。当数据量很大的时候,每次都排除掉一半,排除的数据量是非常惊人的。
Hash:Hash索引只能等值匹配,想范围查询,左前缀查询都不适用, 其余大部分场景
为什么要使用索引?
索引大大减少了存储引擎需要扫描的数据量
索引可以帮助我们进行排序以避免使用临时表
索引可以把随机IO变为顺序IO
二 索引类型
主键索引(primary key):添加了主键就有了主键索引,可以在创建表的时候指定主键,也可以在创建成功之后再增加
唯一索引(unique):添加了唯一约束就有了唯一索引,唯一索引可以有多个null
普通索引(normal):一般是先建表,后面再创建索引,普通索引使用的最多
全文索引(fulltext):主要针对文本段落等,全文索引只能应用MyISAM引擎
空间索引(spatial): 使用较少,并且mysql支持的还不好
关于唯一性有两种做法:
通过程序来保证数据的唯一性
业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。(来自阿里巴巴Java开发手册)
关于全文索引:
全文索引只能用于MyISAM引擎,通常如果用到全文索引一般通过Elasticsearch、Solr、Lucene等技术来实现。
三:索引语法
1. 创建索引
①:语法
-- 创建普通索引:
create index 索引名 on 表(列1【ASC|DESC】, 列2 ASC|DESC】)
-- 创建唯一索引
create unique index on 表名(列名)
1
2
3
4
5
②:索引命名规则
主键索引名为 pk_字段名,pk即 primary key
唯一索引名为 uk_字段名; uk即 unique key
普通索引名则为 idx_字段名;idx即index的简称。
③:索引字段
一个索引可以针对一个字段进行创建,也可以指定多个字段创建复合索引。
④:在哪些列上适合添加索引
频繁作为查询条件的列或者连接条件的列适合创建索引,即Where中的列或者是连接子句指定的列
唯一性太差的字段不适合创建索引,如性别
更新非常频繁的字段不适合创建索引
不作为where条件的字段不要创建索引
选用NOT NULL的列
尽量使用字段长度小的列作为索引
使用数据类型简单的列(int 型,固定长度)
⑤:索引顺序
ASC | DESC 选项 除非显式指定降序 (DESC),否则列以升序 (ASC) 排序。不管索引是升序排列还是降序排列,在执行升序或降序 ORDER BY 操作时都会使用索引。但是如果通过混合的升序和降序属性来执行 ORDER BY,则仅当索引是用同样的升序和降序属性创建的时才使用索引。
-- 可以显式指定索引字段的顺序,默认为升续
CREATE INDEX idx_username ON tbl_user(username ASC);
-- 对于较长的字符内容可以指定前N个字节创建索引,没必要为整个值都创建索引
CREATE INDEX idx_username ON tbl_user(contnet(20) ASC);
-- 复合索引:基于多个字段共同创建索引(区分度最大的字段放在前面,经常会被使用到的列在前面)
CREATE INDEX idx_username_email ON tbl_user(username, email);
-- 删除索引
DROP INDEX idx_username ON tbl_user;
-- 查看某个表的索引,两种方式效果一样
SHOW INDEX FROM tbl_user;
SHOW KEYS FROM tbl_user;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
⑥:注意
如果是先建表,表中有比较多的数据,此时再创建索引,创建完索引需要等一会,让索引在后台创建完再使用
索引数量控制,单张表中索引数量不应超过5个,单个索引中的字段数不超过5个。
索引存储的位置位于mysql安装的/xxx/data目录下, 索引能提高查询速度,但对update/delete/insert变慢,因为还要重新维护索引文件,一般情况下查询次数远大于增删改
2. 查询索引
show index from 表名;
show keys from 表名;
1
2
3. 修改索引
一般是先删除再创建
4. 删除索引
alter table xxx drop index 索引名;
alter table xxx drop primary key;
1
2
3
- 删除重复和冗余的索引(第三方工具需要额外安装)
pt-duplicate-key-checker h=127.0.0.1
-- 更新索引统计信息及减少索引碎片
ANALYZE TABLE <table_name>
-- 清理碎片(注意会锁表)
OPTIMIZE table <table_name>
1
2
3
4
5
6
7
8
查询没有使用到的索引
SELECT
object_schema,
object_name,
index_name,
b.table_rows
FROM performance_schema.table_io_waits_summary_by_index_usage a
JOIN information_schema.tables b ON a.object_schema = b.table_schema AND a.object_name = b.table_name
WHERE index_name IS NOT NULL
AND count_star = 0
ORDER BY object_schema, object_name;