上文原始Kmeans提到,由于Kmeans使用启发式迭代,所以当初始点不当时,导致得不到全局最优。
Kmeans++
这个算法思想也很简单,与原始Kmeans唯一不同的是选择初始点的方式。
如图
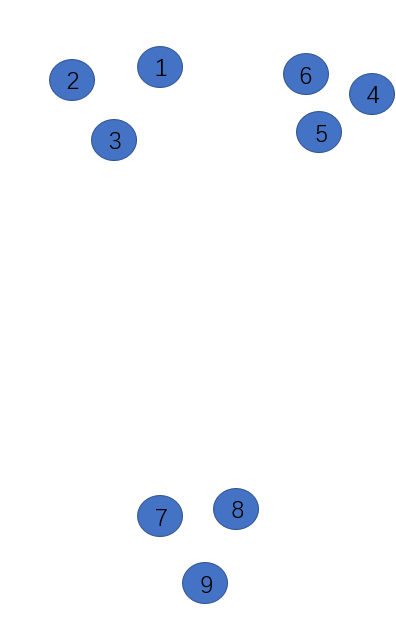
假设,我们的样本如上图分布,准备选择3个初始点,即k=3。
第一,我随机选择了1作为初始点,求所有样本点与已选择的聚类中心中最近聚类中心的距离(现在只有点1),求出其他所有点与点1的距离D(xi),选择最大的。
第二,我们现在选到了点9作为初始点(与1距离最远),然后所有样本点与已选择的聚类中心中最近聚类中心的距离,对于点2,3,4,5,6应求到1的距离,7,8求到9的距离,取最大的D(x),
应该是点1到点4最大,那么点4倍被选为初始点。
那么一共选出了点1,9,4作为初始点。
可以重复一、二步骤,选出多个初始点。
elkan K-Means
在Kmeans一文我们知道,一次质心的更新需要将所有样本点到质心的距离都算一次,比较耗时
elkan K-Means的思想是
针对一个样本点,两个质心,如果提前知道质心之间的距离D(a1,a2),那么
当2D(x,a1)≤D(a1,a2), 必有D(x,a1)≤D(x,a2),不必计算D(x,a2)
当
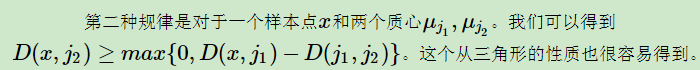
这一条不太明白,原理是三角形任意一边大于等于其他两边之差,怎么简化计算,不得而知
大样本Mini Batch K-Means
思想更简单,对大样本进行无放回随机抽样,抽取多次保证准确性。
Sequential Leader Clustering
这种方法不用预先设定K值,不需要迭代,只需将数据过一遍。需要设定一个阈值T。
用下图说明该思想
第一,任意一个数据点(假如是点1)作为质心,依次算出其他2-9到质心1的距离d,若d<T(阈值),认为这两个点属于一个簇
第二,若某样本点与现有质心的距离大于阈值T,则将这个点作为另一个质心。
重复上述两步
缺点:阈值的设定没有依据。