Drop out
深度神经网络包含多个非线性隐藏层,这使得它能够学习输入和输出之间的复杂关系,但我们不可否认的是:在实际情况中,即使测试集和训练集来自同一分布,训练集仍会存在噪声,那么网络就会同时学习数据和噪声的分布,这样就会容易导致过拟合。
在机器学习中,我们通常采用模型组合来提高模型的性能。然而,对于大型的神经网络来说,对多个网络模型的输出取平均的做法是耗费时间和空间的。所以提出了Dropout。Dropout就是随机丢弃神经网络中的神经元,所谓的丢弃就是将神经元从神经网络中移除,包括它与前向和后向的连接,具体哪个神经元被丢弃是随机的。在Dropout结构中,每个神经元都会有一个参数概率P,P可以由验证集进行选择,也可以设置为0.5。

dropout操作流程:参数是丢弃率p
1)在训练阶段,每个mini-batch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元置零)。用一个mask向量与该层神经元对应元素相乘,mask向量维度与输入神经一致,元素为0或1。
2)然后对神经元rescale操作,即每个神经元除以保留概率1-P,也即乘上1/(1-P)。
3)反向传播只对保留下来的神经元对应参数进行更新。
4)测试阶段,Dropout层不对神经元进行丢弃,保留所有神经元直接进行前向过程。
rescale是为了保证训练和测试分布尽量一致,或者输出能量一致。可以试想,如果训练阶段随机丢弃,那么其实dropout输出的向量,有部分被屏蔽掉了,可以等下认为输出变了,如果dropout大量应用,那么其实可以等价为进行模拟遮挡的数据增强,如果增强过度,导致训练分布都改变了,那么测试时候肯定不好,引入rescale可以有效的缓解,保证训练和测试时候,经过dropout后数据分布能量相似。如果不进行rescale,可以在测试的时候在每个神经元对应的权重w需乘以p,即。(原理:训练时dropout后的期望:
, 为了使测试时期望与之对应,需给w乘以p。)rescale和这种方法两者选一个。
dropout方法多是作用在全连接层上,在卷积层应用dropout方法意义不大。文章认为是因为每个feature map的位置都有一个感受野范围,仅仅对单个像素位置进行dropout并不能降低feature map学习的特征范围,也就是说网络仍可以通过该位置的相邻位置元素去学习对应的语义信息,也就不会促使网络去学习更加鲁邦的特征。
既然单独的对每个位置进行dropout并不能提高网络的泛化能力,那么很自然的,如果我们按照一块一块的去dropout,就自然可以促使网络去学习更加鲁邦的特征。思路很简单,就是在feature map上去一块一块的找,进行归零操作,类似于dropout,叫做dropblock。
Drop block
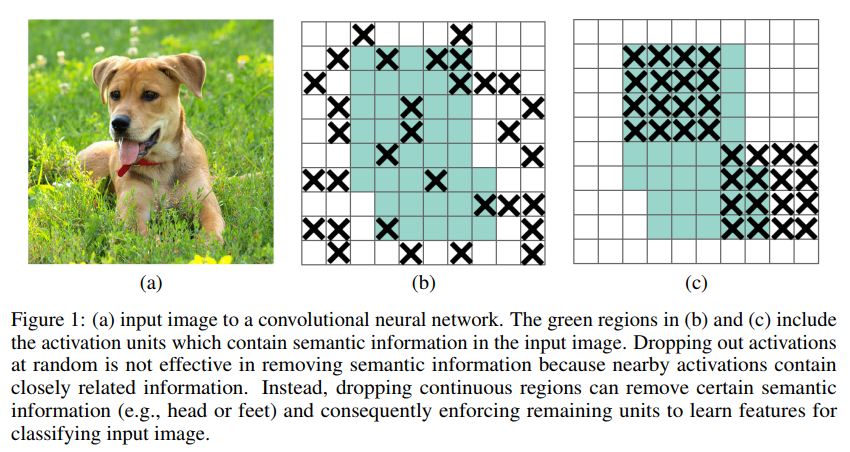
绿色阴影区域是语义特征,b图是模拟dropout的做法,随机丢弃一些位置的特征,但是作者指出这中做法没啥用,因为网络还是可以推断出来,(c)是本文做法,具体的就是:
1)先生成针对layerA的mask M,M表示对每个位置进行伯努利概率分布采样得到所有的Mi,j,然后把这个Mi,j当做中心,利用block_size参数计算出block范围,将block内的Mi,j都设为0;
2)用一个mask向量与该层特征图A对应元素相乘,mask向量维度与输入神经一致,元素为0或1;
3)然后进行rescale操作,对A每个位置值除以保留概率(count_ones(M)/count(M)),相当于乘上(count(M)/count_ones(M))

有两个参数需要指定,一个是block_size,另一个是伯努利概率分布参数γ,这里不直接使用keep_prob是因为在dropout里面这表示一个神经元被保留下来的概率,而在drop block,因为是block而不只是本神经元,所以需要重新计算,具体这个计算公式怎么推导的我没想明白,文中给出的是这样的:

文中说我们一般先估计一个keep_prob(大约为0.75~0.95),然后通过上式计算γ。block_size控制为7*7效果最好,对于所有的feature map都一样。